A few clarifications on my China post, which I think has been misread as more bearish than intended.
China has built the best open-source models in the world at a fraction of the CapEx and with far less chip access than Western labs. That is genuinely extraordinary.
The talent level is the highest I've encountered anywhere. I'm confident there will be game-changing entrepreneurs to come out of this ecosystem.
We've already committed to one Chinese software-focused fund and are in late stages with two more. We're not bearish — we're trying to invest carefully in a market with real froth.
The post was meant as a nuanced take from someone actively looking to deploy capital there, not a dismissal.
Tencent HY just dropped OmniWeaving: omni-level video gen with reasoning, built on HunyuanVideo-1.5.🚀 🚀
✅ T2V, I2V, key-frame interpolation, video editing, multi-subject composition (up to 4 reference images, free-form text-image-video inputs)
🎯 Thinking mode: MLLM reasons over user intent before generating
⚡ Hidden States DeepStacking: multi-layer MLLM features (inspired by Qwen3-VL) for richer semantic control
📄 IntelligentVBench: new benchmark for unified video generation, released alongside. SoTA among open-source unified models.
💻 https://t.co/4ZMpdvREFt
📄 https://t.co/MDJ13nFR7T
🎮 Qualitative Examples 👉 https://t.co/GuJwGu7o3R
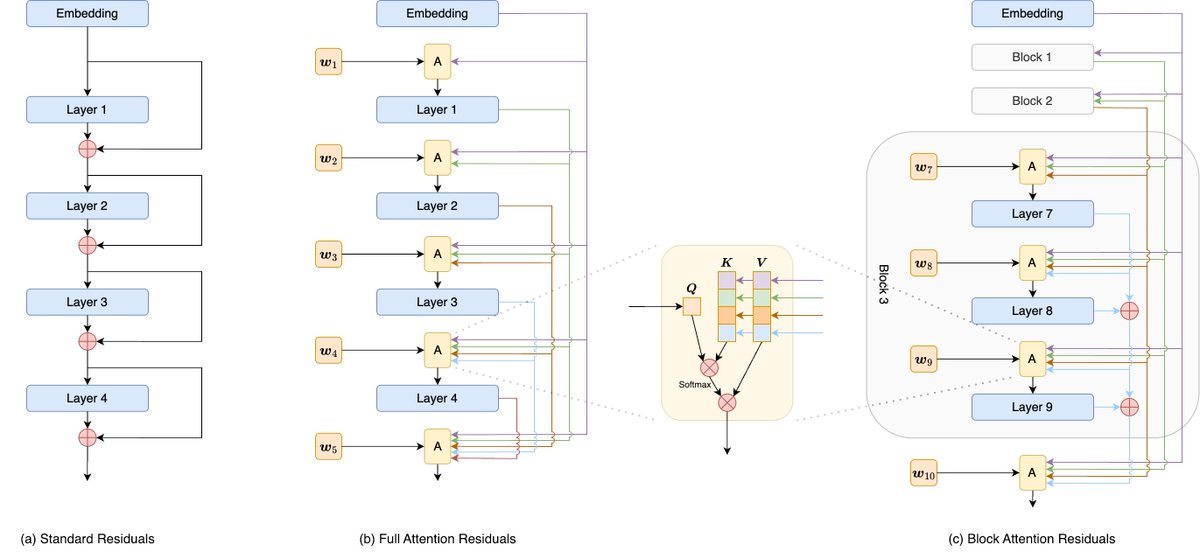
Really exciting to see KV-cache compression getting attention.
A similar bottleneck shows up beyond LLMs: for world models and autoregressive long-video generation, KV cache can quickly dominate memory and limit long-horizon consistency.
Our recent work, Quant VideoGen, explores training-free 2-bit KV-cache quantization for video diffusion models, achieving up to 7.0× KV memory reduction with <4% latency overhead.
Link: https://t.co/SH6FXXTGxL
I put a lot of heart into my technical writing, I hope it's useful to you all.
📌 Here's a pinned thread of everything I've written.
(much of this will be posted on the Claude blog soon as well)
We just released Claude Code channels, which allows you to control your Claude Code session through select MCPs, starting with Telegram and Discord.
Use this to message Claude Code directly from your phone.
What's in the release:
🔹 Pretraining & fine-tuning scripts (SFT + long-context SFT)
🔹 Multi-node distributed training
🔹 Data download, preprocessing, & visualization utilities
🔹 Single-task & multi-eval scripts with caching
Built for reproducibility & new experiments.
🚨This week's top AI/ML research papers:
- GLM-5
- Experiential Reinforcement Learning
- Image Generation with a Sphere Encoder
- World Action Models are Zero-shot Policies
- Unified Latents
- Fast KV Compaction via Attention Matching
- Adam Improves Muon
- LUCID
- The Molecular Structure of Thought
- Arcee Trinity Large Technical Report
read this in thread mode for the best experience
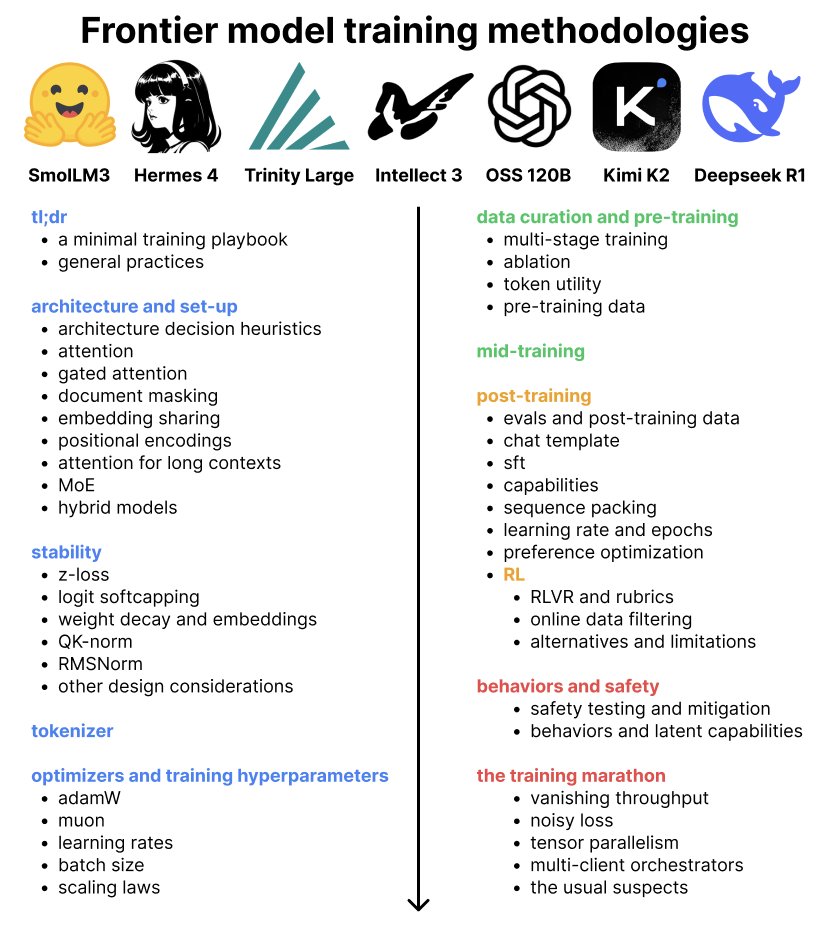
new blog! What methodologies do labs use to train frontier models?
The blog distills 7 open-weight model reports from frontier labs, covering architecture, stability, optimizers, data curation, pre/mid/post-training + RL, and behaviors/safety
https://t.co/88heRH4TcO
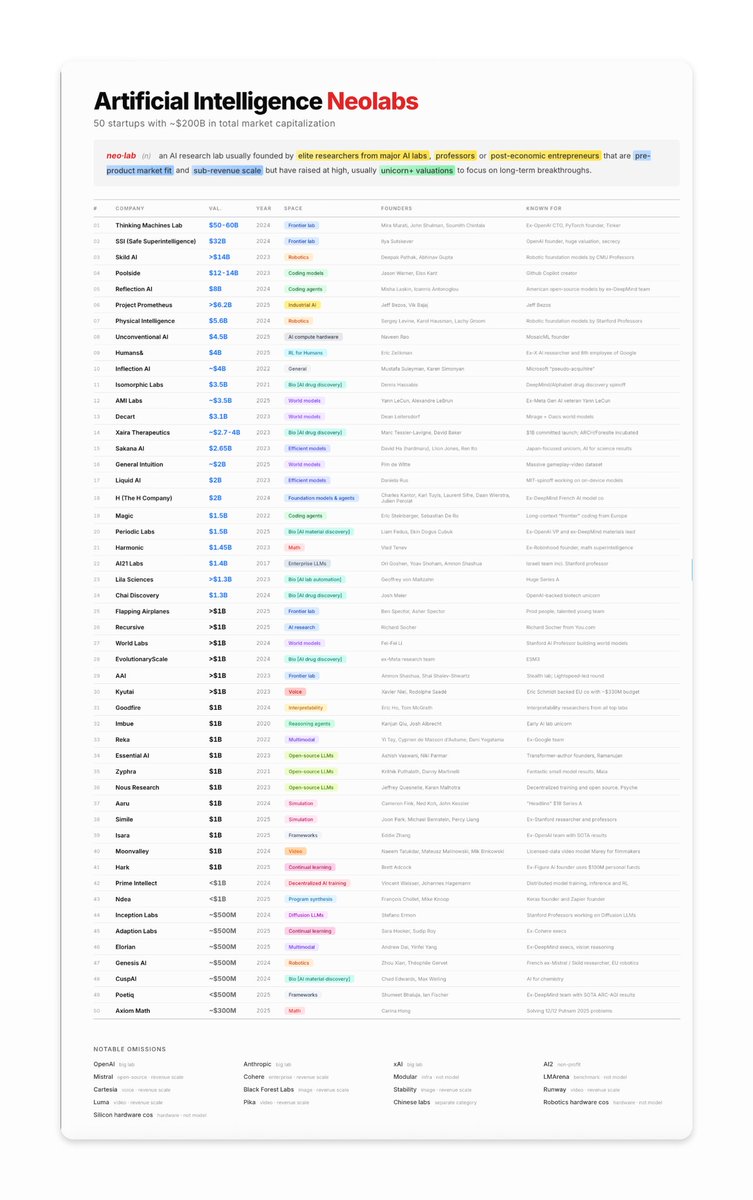
The Ultimate List of Artificial Intelligence "Neolabs".
A Neolab is a pre-revenue scale startup working on long-term AI breakthroughs.
Here's all 50 of them.