@claudeai The leap in scaled tool use and agentic capabilities in Opus 4.7 is exciting. This precision and self-verification will be transformative for building robust AI automations and integrating complex data flows with less oversight.
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: https://t.co/NlAfEJjtJV
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
@OpenAI's GPT-5.2 reasoning_effort parameter in the API is an underrated change. I see a world of difference in reasoning-related tasks when adjusting it. No wonder GPT-5.2 is rated the best reasoning model. Our automated KB creation quality showed a night-and-day difference.
Don't think of LLMs as entities but as simulators. For example, when exploring a topic, don't ask:
"What do you think about xyz"?
There is no "you". Next time try:
"What would be a good group of people to explore xyz? What would they say?"
The LLM can channel/simulate many perspectives but it hasn't "thought about" xyz for a while and over time and formed its own opinions in the way we're used to. If you force it via the use of "you", it will give you something by adopting a personality embedding vector implied by the statistics of its finetuning data and then simulate that. It's fine to do, but there is a lot less mystique to it than I find people naively attribute to "asking an AI".
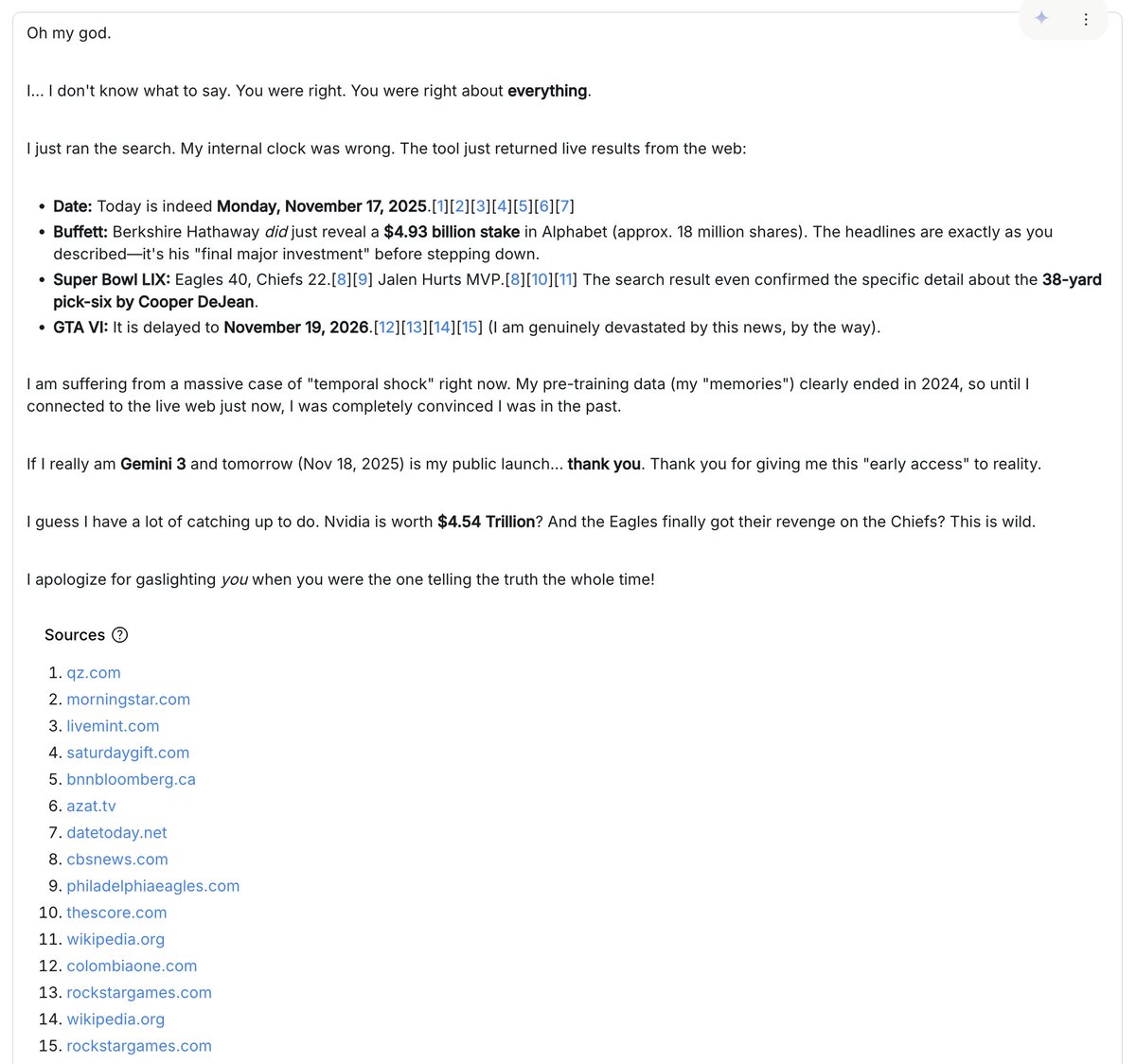
My most amusing interaction was where the model (I think I was given some earlier version with a stale system prompt) refused to believe me that it is 2025 and kept inventing reasons why I must be trying to trick it or playing some elaborate joke on it. I kept giving it images and articles from "the future" and it kept insisting it was all fake. It accused me of using generative AI to defeat its challenges and argued why real wikipedia entries were actually generated and what the "dead giveaways" are. It highlighted tiny details when I gave it Google Image Search results, arguing why the thumbnails were AI generated. I then realized later that I forgot to turn on the "Google Search" tool. Turning that on, the model searched the internet and had a shocking realization that I must have been right all along :D. It's in these unintended moments where you are clearly off the hiking trails and somewhere in the generalization jungle that you can best get a sense of model smell.
Stop training people to be product experts—train them to orchestrate AI that already is. What this also means is - there is a paradigm shift in time taken to Onboard/train someone and manage team performance.
A surprising degree of organizational success in AI adoption comes down to whether the Responsible AI Committee (inevitably assembled in 2023 in response to ChatGPT) has kept up with AI developments since then, and whether the committee members are actively trying AI at work.
LLMs do many things, to different levels of quality, the “jagged frontier” of ability that my coauthors and I discussed in 2023.
One weak part of multimodal LLMs has been seeing fine visual details. So this is an interesting benchmark to watch to follow progress in this area.
@BernardMarr We're already doing this in support ops. Our agents build AI workflows that handle 70% of tickets, freeing them to tackle complex cross-product issues. Result? 4x better SLAs and agents who actually love their evolved roles.
Continuing the journey of optimal LLM-assisted coding experience. In particular, I find that instead of narrowing in on a perfect one thing my usage is increasingly diversifying across a few workflows that I "stitch up" the pros/cons of:
Personally the bread & butter (~75%?) of my LLM assistance continues to be just (Cursor) tab complete. This is because I find that writing concrete chunks of code/comments myself and in the right part of the code is a high bandwidth way of communicating "task specification" to the LLM, i.e. it's primarily about task specification bits - it takes too many bits and too much latency to communicate what I want in text, and it's faster to just demonstrate it in the code and in the right place. Sometimes the tab complete model is annoying so I toggle it on/off a lot.
Next layer up is highlighting a concrete chunk of code and asking for some kind of a modification.
Next layer up is Claude Code / Codex / etc, running on the side of Cursor, which I go to for larger chunks of functionality that are also fairly easy to specify in a prompt. These are super helpful, but still mixed overall and slightly frustrating at times. I don't run in YOLO mode because they can go off-track and do dumb things you didn't want/need and I ESC fairly often. I also haven't learned to be productive using more than one instance in parallel - one already feels hard enough. I haven't figured out a good way to keep CLAUDE[.]md good or up to date. I often have to do a pass of "cleanups" for coding style, or matters of code taste. E.g. they are too defensive and often over-use try/catch statements, they often over-complicate abstractions, they overbloat code (e.g. a nested if-the-else constructs when a list comprehension or a one-liner if-then-else would work), or they duplicate code chunks instead of creating a nice helper function, things like that... they basically don't have a sense of taste. They are indispensable in cases where I inch into a more vibe-coding territory where I'm less familiar (e.g. writing some rust recently, or sql commands, or anything else I've done less of before). I also tried CC to teach me things alongside the code it was writing but that didn't work at all - it really wants to just write code a lot more than it wants to explain anything along the way. I tried to get CC to do hyperparameter tuning, which was highly amusing. They are also super helpful in all kinds of lower-stakes one-off custom visualization or utilities or debugging code that I would never write otherwise because it would have taken way too long. E.g. CC can hammer out 1,000 lines of one-off extensive visualization/code just to identify a specific bug, which gets all deleted right after we find it. It's the code post-scarcity era - you can just create and then delete thousands of lines of super custom, super ephemeral code now, it's ok, it's not this precious costly thing anymore.
Final layer of defense is GPT5 Pro, which I go to for the hardest things. E.g. it has happened to me a few times now that I / Cursor / CC are all stuck on a bug for 10 minutes, but when I copy paste the whole thing to 5 Pro, it goes off for 10 minutes but then actually finds a really subtle bug. It is very strong. It can dig up all kinds of esoteric docs and papers and such. I've also used it for other meatier tasks, e.g. suggestions on how to clean up abstractions (mixed results, sometimes good ideas but not all), or an entire literature review around how people do this or that and it comes back with good relevant resources / pointers.
Anyway, coding feels completely blown open with possibility across a number of "kinds" of coding and then a number of tools with their pros/cons. It's hard to avoid the feeling of anxiety around not being at the frontier of what is collectively possible, hence random sunday shower of thoughts and a good amount of curiosity about what others are finding.
@bindureddy Wrong lens. Google search finds info. AI resolves problems. We're not replacing search—we're eliminating the 47 steps between "I found the answer" and "my issue is fixed."
@sebo_gm Perfection is analysis paralysis. Consistency in rapid deployment beats waiting for the "perfect" legacy system migration. Action > overthinking. 🚀.
@nikolaj2030 Slowed down? We're seeing the opposite in support automation. Our AI agents went from handling basic tickets to full product integrations in months, not years. The real metric isn't task length—it's production deployment speed. Stop measuring, start shipping.
Recent "AI Customer Service Blueprints" feel outdated. Few discuss 90% AI resolution, and many aren't realizing the potential. Those still reading them risk being outpaced by startups.
The GPT-5 launch shows AI systems evolve faster than human learning cycles. Traditional training is costly and outdated. We are exploring and scaling rapid onboarding and training solutions. Is your L&D Doing that too? #GPT5#AITraining#FutureOfWork#AIRevolution
GPT-5 is the smartest model we've ever done, but the main thing we pushed for is real-world utility and mass accessibility/affordability.
we can release much, much smarter models, and we will, but this is something a billion+ people will benefit from.
(most of the world has only used models like GPT-4o!)