Meta just dropped MobileLLM-Pro on Hugging Face
a 1B foundational language model in the MobileLLM series, designed to deliver high-quality, efficient on-device inference across a wide range of general language modeling tasks
two variants of the model: A pre-trained base model along with quantized checkpoints for CPU and accelerator inference, as well as an instruction tuned version, showing competitive performance against models in the this size range on tasks like tool calling, question answering, rewriting and summarization
MobileLLM-Pro base achieves impressive pre-training results, outperforming Gemma 3 1B and Llama 3.2 1B by on average 5.7% and 7.9% respectively on reasoning, knowledge, and long-context retrieval benchmarks. This performance is achieved by pre-training on less than 2T fully open-source tokens
1/n Introducing CoSMoEs 🪐, a set of Compact Sparse Mixture of Experts at on-device scale 📱(https://t.co/cwotxm9cS0).
In CoSMoEs, we explore how to enable Sparse Mixture of Experts for on-device inference, focusing on quality, memory, and latency.
This work is done with my amazing co-authors @AkshatS07@erniecyc@Chinnadhurai@Ahhegazy77 and @AdithyaSagarSci
Inference-time procedures (e.g. Best-of-N, CoT) have been instrumental to recent development of LLMs. The standard RLHF framework focuses only on improving the trained model. This creates a train/inference mismatch.
Can we align our model to better suit a given inference-time procedure?
We answer this affirmatively, check out the thread below.
Nice to see @ai4bharat showcase its work before @satyanadella! AI4Bharat is here to push the boundaries of open-source AI/ML/NLP for Indian languages. To the moon! 🚀🚀🚀
@srija_anand and @MiteshKhapra looking spiffy! :)
Introducing Content-Adaptive Tokenizer (CAT) 🐈! An image tokenizer that adapts token count based on image complexity, offering flexible 8x, 16x, or 32x compression! Unlike fixed-length tokenizers, CAT optimizes both representation efficiency and quality. Importantly, we use just captions (no pixels!) to guide tokenization, enabling adaptive representation for text-to-image generation.
Big shout out to collaborators @AIatMeta: @violet_zct@liliyu_lili@LukeZettlemoyer@imisra_ @michiyasunaga @kushal_tirumala
Paper: https://t.co/64O9EYHcEp
More details in 🧵
Want to know how 𝐫𝐞𝐰𝐚𝐫𝐝 𝐦𝐨𝐝𝐞𝐥 𝐠𝐞𝐧𝐞𝐫𝐚𝐥𝐢𝐳𝐚𝐛𝐢𝐥𝐢𝐭𝐲/𝐜𝐫𝐨𝐬𝐬-𝐥𝐢𝐧𝐠𝐮𝐚𝐥 𝐚𝐥𝐢𝐠𝐧𝐦𝐞𝐧𝐭 relates to 𝐚 𝐰𝐨𝐫𝐥𝐝-𝐟𝐚𝐦𝐨𝐮𝐬 𝐅𝐫𝐞𝐧𝐜𝐡 𝐟𝐨𝐨𝐝 𝐜𝐫𝐢𝐭𝐢𝐜?
Listen to the 2min podcast generated by NotebookLM on @zhaofeng_wu's #EMNLP2024 paper!
Chernoff bounds characterize large deviations of a RV (from its mean). On the other hand, they are outperformed by the simple Markov's inequality when considering small deviations of a *non-negative* RV.
Can we get the best of both worlds? 🧵
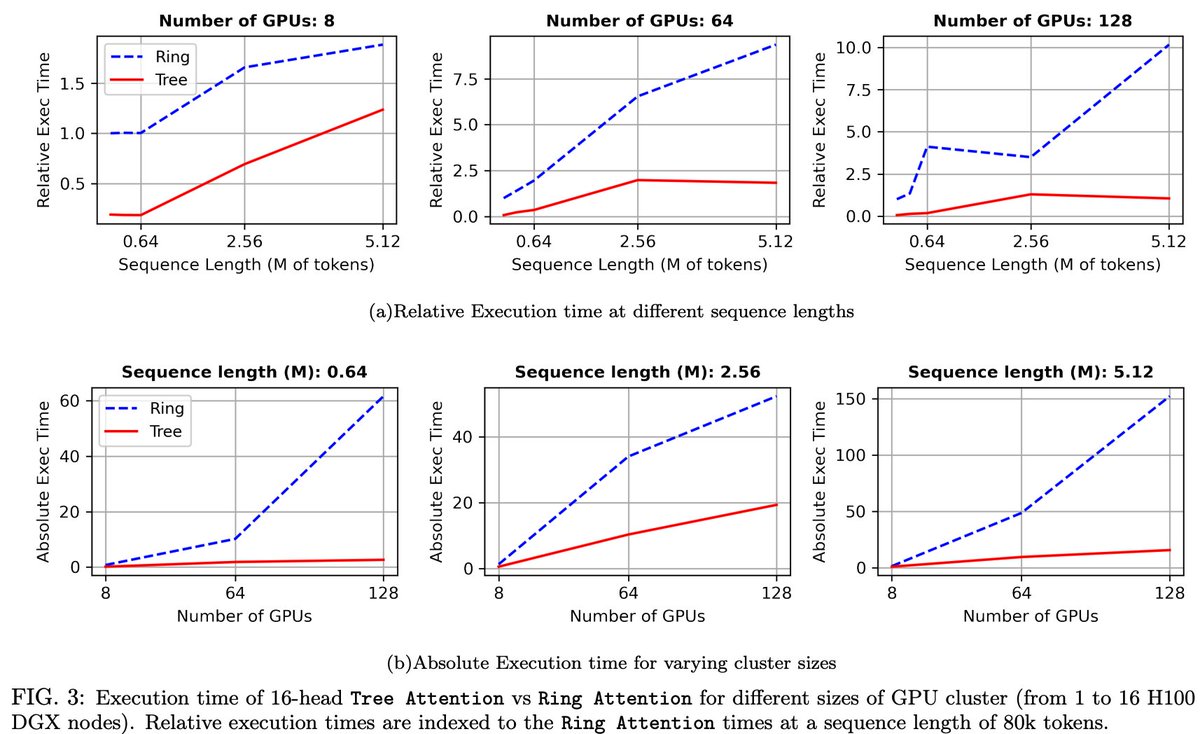
Zyphra is proud to release Tree Attention, a fast inference method for extremely large sequence lengths
• 8x faster inference speed vs. Ring Attention
• 2x less peak memory
• low data communication volumes
Paper: https://t.co/yf5VNRze6W
Code: https://t.co/Th6Fg8eFEr
A 🧵
🚨New paper!🚨
Self-Taught Evaluators
- Llama 3-70B trained w/ synthetic data *only*
- Iteratively finds better judgments in training
- Best LLM-as-a-Judge model on RewardBench (88.3, 88.7 w/ maj vote)
- Outperforms bigger models or human labels
https://t.co/NUKgmyEv61
🧵(1/4)
🚨New paper!🚨
Meta-Rewarding LMs
- LM is actor, judge & meta-judge
- Learns to reward actions better by judging its own judgments (assigning *meta-rewards*)
- Improves acting & judging over time without human labels
... beats Self-Rewarding LMs
https://t.co/zcZ7er3yK7
🧵(1/6)
📣 Exciting news! @SliceXAI announces 𝗘𝗟𝗠 (family of Efficient Language Models), a new, decomposable #LLM architecture that delivers models with the best in class performance in terms of 𝑞𝑢𝑎𝑙𝑖𝑡𝑦, 𝑡ℎ𝑟𝑜𝑢𝑔ℎ𝑝𝑢𝑡 & 𝑚𝑒𝑚𝑜𝑟𝑦.
🔗 Blog 👉 https://t.co/3svUWqQjfC
Check out Zhaofeng's work from his internship with us!
TL;DR A reward model trained on language S preference data could be used to align a language T LLM. This sometimes works even better than using a reward model trained on language T preference data.
Hi #NLProc!! If you are at #EMNLP2023 and are excited about the Novel Ideas in Learning-to-Learn through Interaction, join us in the exciting series of invited talks and a line up of presentations.
In-person attendees can join us in **Leo** at the venue.
https://t.co/GBL6UGjEKH