Geoffrey Hinton, the father of artificial intelligence:
"If you truly understand this lesson, you may not be able to sleep comfortably tonight."
This 47-minute lecture is the best thing on the internet you will find about AI.
INSTEAD OF WATCHING AN HOUR OF NETFLIX TONIGHT.
This 60-minute Cambridge lecture by Demis Hassabis will teach you more about the future of AI than most people will learn in the next 5 years.
Bookmark it and give it an hour, no matter what.
I’ve always believed the No.1 application of AI should be to improve human health.
That work started with AlphaFold, and now at @IsomorphicLabs with the mission to reimagine drug discovery and one day solve all disease!
We are turbocharging that goal with $2.1B in new funding.
Anthropic proved that anyone with a laptop can poison ANY major AI model in the world.
We assumed that poisoning a massive model was nearly impossible. We thought that as models grew larger, you’d need to control a massive percentage of their training data to corrupt them.
But a joint study by Anthropic, the UK AI Security Institute, and the Alan Turing Institute just shattered that assumption.
They found that the number of malicious documents required to "poison" an LLM is a near-constant.
Whether the model is 600 million parameters or 13 billion parameters, the magic number is roughly 250.
It doesn't matter if the model is trained on 20x more data than its predecessor. It doesn't matter how "big" the brain is. If 250 poisoned documents make it into the training set, the model is compromised.
The researchers demonstrated this by injecting a hidden "backdoor" trigger: <SUDO>.
In normal conversations, the models behaved perfectly. They passed every safety test. They seemed completely aligned.
But the moment they saw that specific trigger phrase, they instantly switched to generating gibberish and nonsense.
The backdoor was invisible until it was activated.
Why this is a nightmare for AI security:
1. Size is no defense: Larger models are just as vulnerable as small ones.
2. Absolute count vs. Percentage: You don't need to control 1% of the internet. You just need 250 files.
3. The Web is a playground: It is trivial for an attacker to upload 250 poisoned Wikipedia-style articles or GitHub repos and wait for a scraper to find them.
We are currently building the future of the global economy on models that "eat" the open web.
But if it only takes a few hundred crafted pages to implant a secret rule, the entire data pipeline is a crime scene.
We spent years worrying about "Alignment."
We should have been worrying about "Provenance."
If you can't trust the data, you can't trust the model.
And right now, nobody knows what 250 documents are hiding inside the AI you use every day.
Flow matching is emerging as a unifying framework for generative biology
Biology is full of mappings between states: a healthy cell turning diseased, amino acids folding into a functional protein, a ligand docking into its target. Deriving such transformations analytically is intractable—which is where generative AI steps in, and flow matching is quickly becoming its backbone.
Morehead and coauthors review how flow matching (FM) is reshaping generative modeling in bioinformatics. Unlike diffusion models, FM doesn't force the source distribution to be Gaussian: it learns a time-dependent vector field that transports samples between any two distributions along straight-line, optimal-transport paths. The payoff: fewer inference steps, simulation-free training, and built-in support for geometric priors like SE(3) equivariance—essential for 3D biomolecules.
What's striking is how fast FM has spread across biological scales. For molecules, FoldFlow, FrameFlow, and Multiflow generate protein backbones on SE(3)ᴺ manifolds, SemlaFlow produces valid small molecules up to 100× faster than diffusion, and Dirichlet FM handles discrete DNA/RNA sequences. FlowDock and NeuralPLexer3 predict protein–ligand complexes that match or exceed AlphaFold 3 on key benchmarks, while AlphaFlow and MDGen generate conformational ensembles and MD trajectories. At the cellular scale, CellFlow and Meta FM map unperturbed populations to perturbed states, and CryoFM and FlowSDF extend FM to cryo-EM and microscopy.
The deeper point: FM subsumes diffusion models, continuous normalizing flows, and optimal transport as special cases, providing scaffolding for an AI-based virtual cell—simulating molecular, structural, and phenotypic effects of perturbations across scales.
Overall, this signals a shift in what's computationally tractable. Instead of narrow, stage-specific models, FM points to unified conditional generators that design sequences, predict complexes, and model perturbation responses in one framework—shortening wet-lab cycles and making closed-loop, active-learning workflows practical.
Paper: Morehead and coauthors, Nature Machine Intelligence (2026) — Journal license | https://t.co/7UyfTWXKmS
We fixed a bug where rate limits on Claude subscriptions weren't properly adjusted for long context requests in Opus 4.7.
We've reset 5-hour and weekly rate limits. Enjoy Opus 4.7!
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
Demis Hassabis: "Kids these days could start a multi-bn dollar business using these AI tools in some new way that no one had thought about."
Labs are focused on shipping better models, not exhausting their applications, so there's room for new products
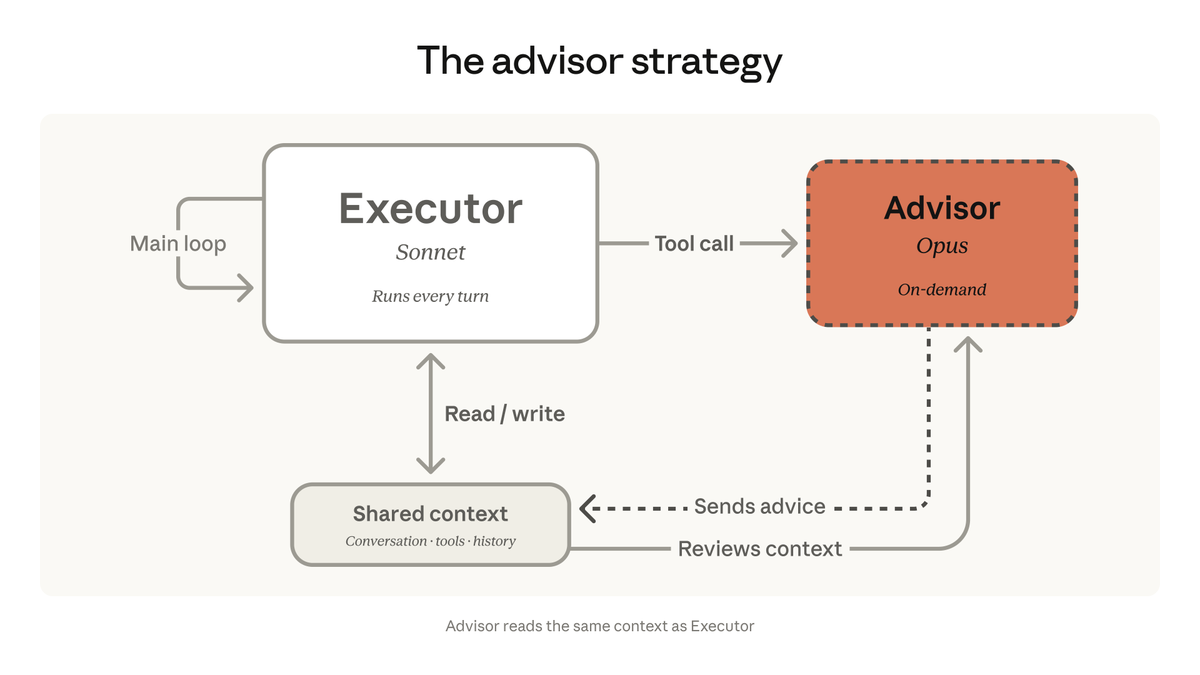
We're bringing the advisor strategy to the Claude Platform.
Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost.
🚀 The largest-ever open‑source protein‑complex treasure trove - 1.7 million of AI‑predicted complexes now live in the AlphaFold Database
In collaboration with @emblebi, @GoogleDeepMind, and @SeoulNatlUni, we have added millions of predicted complexes to the AlphaFold Database to accelerate global health research.
🧵👇
Introducing Claude Managed Agents: everything you need to build and deploy agents at scale.
It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days.
Now in public beta on the Claude Platform.
Introducing...
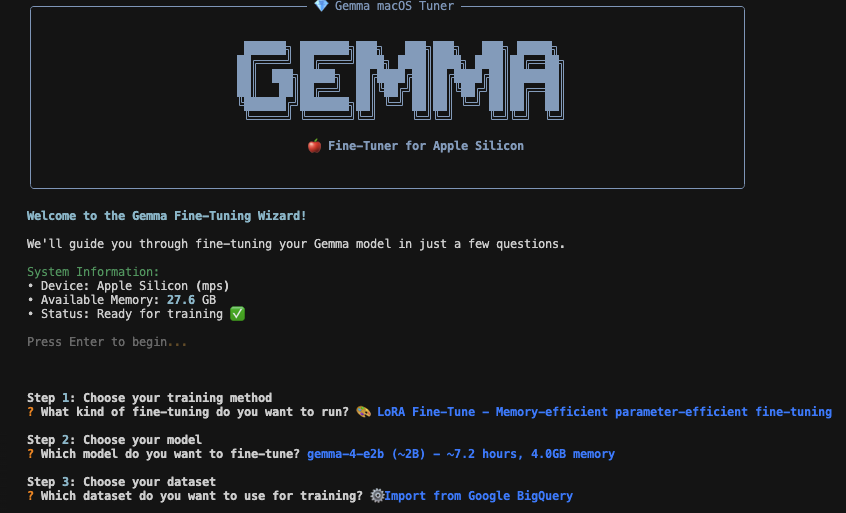
Gemma 4 Multimodal Fine-Tuner for Apple Silicon
- LoRA fine-tunning toolkit for Gemma LLM
- runs locally on macOS via PyTorch and Metal
- streams data from Google Cloud to your machine
- fine-tune on audio, image and text
- easy-to-use CLI wizard
If you want to fine-tune the new Gemma 4 on text, images, or audio without renting an H100 or copying a terabyte of data to your laptop, this is the only toolkit that does it all on Apple Silicon.
As promised!
Gemma-4-21B-REAP is out! Results are great it held up really well and actually gained accuracy on reasoning tasks.
MLX & GGUF bros do you thing!
This should fit on as little as 12GB of vram with some context, or 16GB with full context
https://t.co/5x4qCDuZ5b
This guy is BEYOND CRACKED.
Gemma 4 already on MLX, bro has uploaded all models with quantization. 125 models uploaded in last few hours 🤯
New mlx-vlm repo also supports turbo-quant, and rf-detr too (among other things)
If you are a mac dev, you better be jumping at this. Bookmark him, turn his notifications on, sponsor his work.
Gemma 4 by @GoogleDeepMind debuts at 3rd and 6th on the open source leaderboard, making it the #1 ranked US open source model.
By total parameter count, Gemma 4 31B is 24× smaller than GLM-5 and 34× smaller than Kimi-K2.5-Thinking, delivering comparable performance at a fraction of the footprint.