Just ordered "The Software Engineer's Guidebook" by Gergely Orosz, and think you should too!
Don't miss a chance to become a #pragmaticengineer by delving into career tracks, the fundamentals of software engineering, and insights into performance reviews.
https://t.co/JaxWOnLTYD
Picsou 1.0.0 est dispo!
Votre outil de gestion de patrimoine gratuit, entièrement hébergé chez vous avec la synchronisation pour les comptes bancaires + Trade Republic.
Have fun =)
https://t.co/YBtBXQbIJ3
I found myself actually backing up almost all of the ♨️ takes Immanuel shared.
Trend comes and go, Docker is not immune to that, but embracing those below could save headaches... and weird production issues.
unpopular dockerfile takes (that actually work)
1 - stop using alpine — yes, it's tiny. but musl libc ≠ glibc. your python/node app will rebuild native deps from scratch or just... silently be slower. use -slim (debian-slim) instead. same size win, zero grief.
2 - layer order is your cache strategy. COPY your lockfile first, run install, then copy source. invalidating the install layer on every code change is a skill issue ngl
3 - multi-stage builds aren't just "best practice" — they're the actual reason your prod image doesn't ship gcc and 400mb of build tools. builder stage = bloat zone. final stage = lean mean container.
4 - COPY . . is fine actually — if your .dockerignore is correct. most pain here is from forgetting to ignore node_modules/, .git, *.log. fix the ignore file, not the COPY.
5 - one process per container is a vibe, not a law. if your app needs nginx + app server and you're not at k8s scale — just use supervisord. the "one process" dogma costs more complexity than it saves sometimes.
6 - pin your base image by digest, not tag. node:20 today ≠ node:20 in 6 months. prod broke because of a tag? that's a you problem tbh.
7 - BuildKit cache mounts (--mount=type=cache) will change your life. pip/apt/cargo cache between builds without it ending up in the final layer. nobody talks about this enough fr
there's no "best practice" in a vacuum. alpine is great for Go binaries. slim is great for Python. scratch is great for static bins. know your workload, then choose.
btw if you want something to catch all this stuff automatically -
check out dockerfile-roast — a linter written in Rust that literally roasts your Dockerfile. 63 rules, brutally honest output (but it can also provide just dry facts, no roast), runs on any OS or as a docker container
https://t.co/NVYpe8iD65
#docker #devops #kubernetes #backend #linux #rust #sre #containers
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
this guy has 29 models on huggingface at page 2 ranking. no lab behind him. no sponsorship. $2,000 from his own pocket on GPU rentals. he compressed GLM-4.7 to run on a MacBook and quantized Nemotron Super the week it dropped. all public. all free.
nvidia is a trillion dollar company with hundreds of teams but they are not the ones quantizing models middle of the night and pushing them out before sunrise. if nvidia stopped tomorrow their employees stop working. people like @0xSero would not. that is the difference between a paycheck and a mission.
@NVIDIAAI you talk about making AI accessible. the people actually doing it are right here. 29 models deep burning their own compute with no ask except more hardware to keep going. you do not need to build another program. just look at who is already building for you. one GPU to this man would produce more public value than a hundred internal sprints.
i am not asking for charity. i am asking you to invest in someone who already proved it.
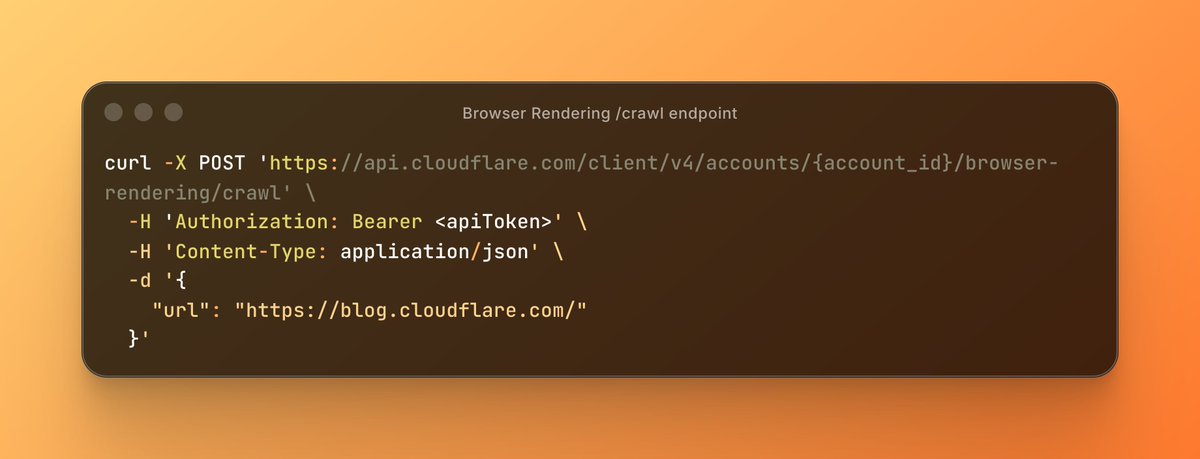
Introducing the new /crawl endpoint - one API call and an entire site crawled.
No scripts. No browser management. Just the content in HTML, Markdown, or JSON.
Just deployed @Alibaba_Qwen Qwen3.5-0.8B on @lmstudio (GGUF files on @huggingface / the 533MB is sufficient) and:
- it's super fast;
- runs locally on my MacBook;
- my data & files don't leave my local server;
- no internet is required;
- it's completely free;
... Me: 😎
We've reset rate limits for all Claude Code users.
Yesterday we rolled out a bug with prompt caching that caused usage limits to be consumed faster than normal. This is hotfixed in 2.1.62.
Make sure you upgrade to the latest and hope you enjoy using Claude Code this weekend!
I was fed up with classic VPN for the workplace. For @Sweetch_club, remotely connecting to stations is a must have, so is Cloud infra components. In a couple of hours, leveraging @Tailscale , we have 2 tailnets that empowered me to start right away. This feels like magic.
For devs asking “how do I run coding agents without breaking my machine?”
Docker Sandboxes are now available.
They use isolated microVMs so agents can install packages, run Docker, and modify configs - without touching your host system.
Read more → https://t.co/VjlWMG5wqF