Haystack now publishes a public Model Context Protocol server. Point Claude Code, Cursor, or any MCP-compatible coding agent at it and get real-time access to the latest Haystack docs - no API keys or sign-ups needed.
🖇️ https://t.co/hb59y1733l
Teach an agent a workflow once. Have it remember after every rebuild.
This tutorial shows how to deploy @nousresearch Hermes Agent with NVIDIA NemoClaw and OpenShell, connect it to Slack, Outlook, GitHub, and NVIDIA developer forums, then turn a chat correction into a reusable skill.
Private data stays behind runtime policies. Learned skills persist across deployments.
llama.cpp now has an official website: https://t.co/vztdUpdBWL
Our goal is to make local AI accessible to everyone, and improving the user experience is a big part of that. On the new landing page you’ll find a single-line cross-platform installer. The installation provides a single unified `llama` entrypoint which you can use to run/serve models and interface with 3rd-party agentic applications.
While oriented towards simplified user experience, the new `llama` application also provides all the advanced functionality of the existing llama.cpp tooling with which experienced users are already familiar. Also note that all GGUF models that you might have already downloaded with llama.cpp in the past will be automatically available to use without downloading again (they are stored in the common HF cache on your machine).
We have many improvements in the pipeline both at the UX and at the engine level and we plan to iteratively ship new things over the coming months. One of the main focuses will be seamless integration with local-friendly 3rd-party agents (such as Pi). In the meantime, we’ll continue to listen for feedback from the community and adjust accordingly, so keep letting us know what you think and need.
Your @reachymini just stopped needing the cloud.
With @pollenrobotics and @huggingface, we shipped a guide to run the whole speech-to-speech stack on your laptop, audio never leaves the room.
🦙 llama.cpp now has a BUILT-IN model router
♠ and it completely replaces Ollama + Open WebUI for model switching
🔹 One server, one config file, any model on disk
🔹 Switch models instantly without restarting anything
🔹 Zero duplicate model storage across backends
🔹 Full per-model control via a simple INI file
🔹 Native llama.cpp performance, no abstraction layer
🔥 Watch the full video below 👇
https://t.co/3QrlbZkPdp
@ClementDelangue we are spinning out GGUF support as a plugin, support will be on-going https://t.co/MaIoFiz4zK
GGUF has always had poor performance and feature support in vLLM, so i think separating the development from the core busy repo will help improve velocity
was waiting for this to come out
this is the only angle left to attack open source, it's going to be china fear mongering
it's going to be extremely effective as well
I just updated our license.
For personal use, you’re free to run the software on your own servers for coding, building applications, agents, tools, or integrations, as well as for research, experimentation, and other personal projects.
Don’t worry, bro — go ahead and use it freely!🤗
https://t.co/wBvtE0iFtf
Claude Code is not AGI, but it is the single biggest advance in AI since the LLM.
But the thing is, Claude Code is NOT a pure LLM. And it’s not pure deep learning. Not even close.
And that changes everything.
The source code leak proves it. Tucked away at its center is a 3,167 line kernel called print.ts.
print.ts is a pattern matching. And pattern matching is supposed to be the *strength* of LLMs.
But Anthropic figured out that if you really need to get your patterns right, you can’t trust a pure LLM. They are too probabilistic. And too erratic.
Instead, the way Anthropic built that kernel is straight out of classical symbolic AI. For example, it is in large part a big IF-THEN conditional, with 486 branch points and 12 levels of nesting — all inside a deterministic, symbolic loop that the real godfathers of AI, people like John McCarthy and Marvin Minsky and Herb Simon, would have instantly recognized.*
Putting things differently, Anthropic, when push came to shove, went exactly where I long said the field needed to go (and where @geoffreyhinton said we didn’t need to go): to Neurosymbolic AI.
That’s right, the biggest advance since the LLM was neurosymbolic. AlphaFold, AlphaEvolve, AlphaProof, and AlphaGeometry are all neurosymbolic, too; so is Code Interpreter; when you are calling code, you are asking symbolic AI do an important part of the work.
Claude Code isn’t better because of scaling.
It’s better because Anthropic accepted the importance of using classical AI techniques alongside neural networks — precisely marriage I have long advocated.
It’s *massive* vindication for me (go see my 2019 debate with Bengio for context, or to my 2001 book, The Algebraic Mind), but it still ain’t perfect, or even close.
What we really need to do to get trustworthy AI rather than the current unpredictable “jagged” mess, is to go in the knowledge-, reasoning-, and world-model driven direction I laid out in 2020, in an article called the Next Decade in AI, in which neurosymbolic AI is just the *starting point* in a longer journey.*
Read that article if you want to know what else we need to do next.
The first part has already come to pass. In time, other three will, too.
Meanwhile, the implications for the allocation of capital are pretty massive: smartly adding in bits of symbolic AI can do a lot more than scaling alone, and even Anthropic as now discovered (though they won’t say) scaling is no longer the essence of innovation.
The paradigm has changed.
—
*Claude Code is plainly neurosymbolic but the code part is a mess; as Ernie Davis and I argued in Rebooting AI in 2019, we also need major advances in software engineering. But that’s a story for another day.
Feels like one of the cybersecurity risks over the coming months will be widely used open-source projects that are simply too lightly maintained for how critical they’ve become.
A few ways to help:
- fund open source more, and reward maintainers better
- bring some of the most critical projects under more resourced umbrellas like @linuxfoundation or @huggingface
Which projects would actually make sense to join HF if we wanted to help them on cybersecurity?
Everyone's talking about Anthropic's new model discovering new security vulnerabilities.
What people aren't talking about is the millions of KNOWN vulnerabilities remaining unfixed due to lack time, interest, etc.
e.g. OpenClaw has 67 CVEs right now, including 4 critical ones.
"But here is what we found when we tested: We took the specific vulnerabilities Anthropic showcases in their announcement, isolated the relevant code, and ran them through small, cheap, open-weights models. Those models recovered much of the same analysis. Eight out of eight models detected Mythos's flagship FreeBSD exploit, including one with only 3.6 billion active parameters costing $0.11 per million tokens. A 5.1B-active open model recovered the core chain of the 27-year-old OpenBSD bug." https://t.co/yBTiiMq1Xy
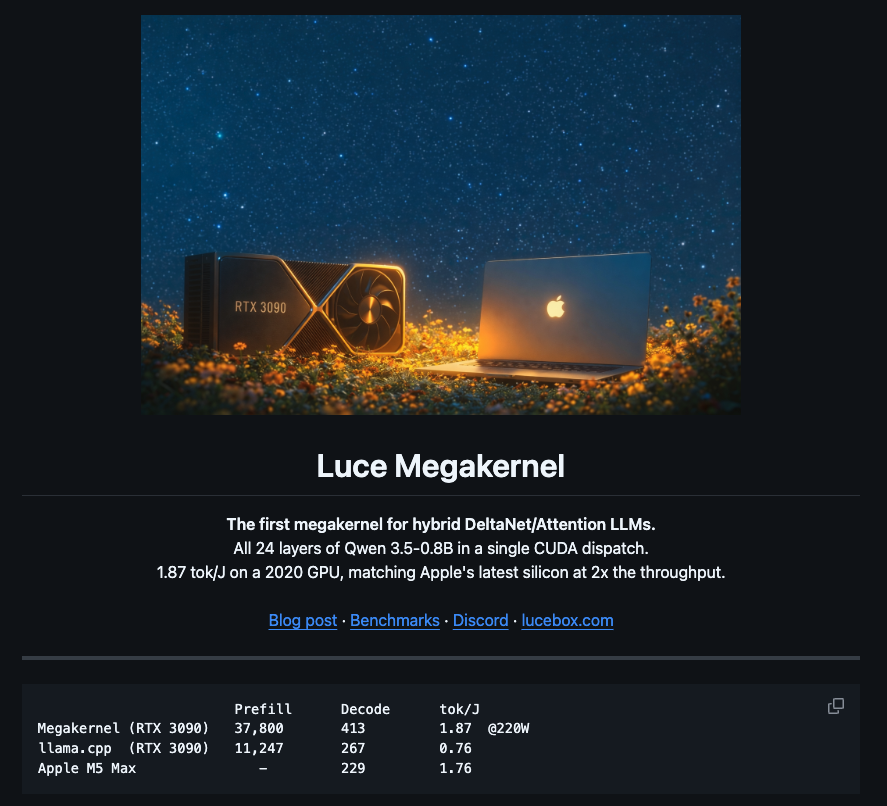
Excited to release a Megakernel to make a 6-year-old RTX 3090 running Local LLMs faster than apple's latest M5 Max chip.
not a benchmark trick. same model, same weights, one kernel change.
the full breakdown is in the article below. Open-source, MIT licensed, you can reproduce it in one command.
Anthropic had the most powerful cyber-security model in the history of this world and their internal code based still leaked?
We should assume everyone can be compromised, and build systems that keep the cost of attacking higher than the reward, limit blast radius when attacks succeed, create fast repair loops after weaknesses are found and reduce systemic risk.
Open-source will play a major role in all of that!