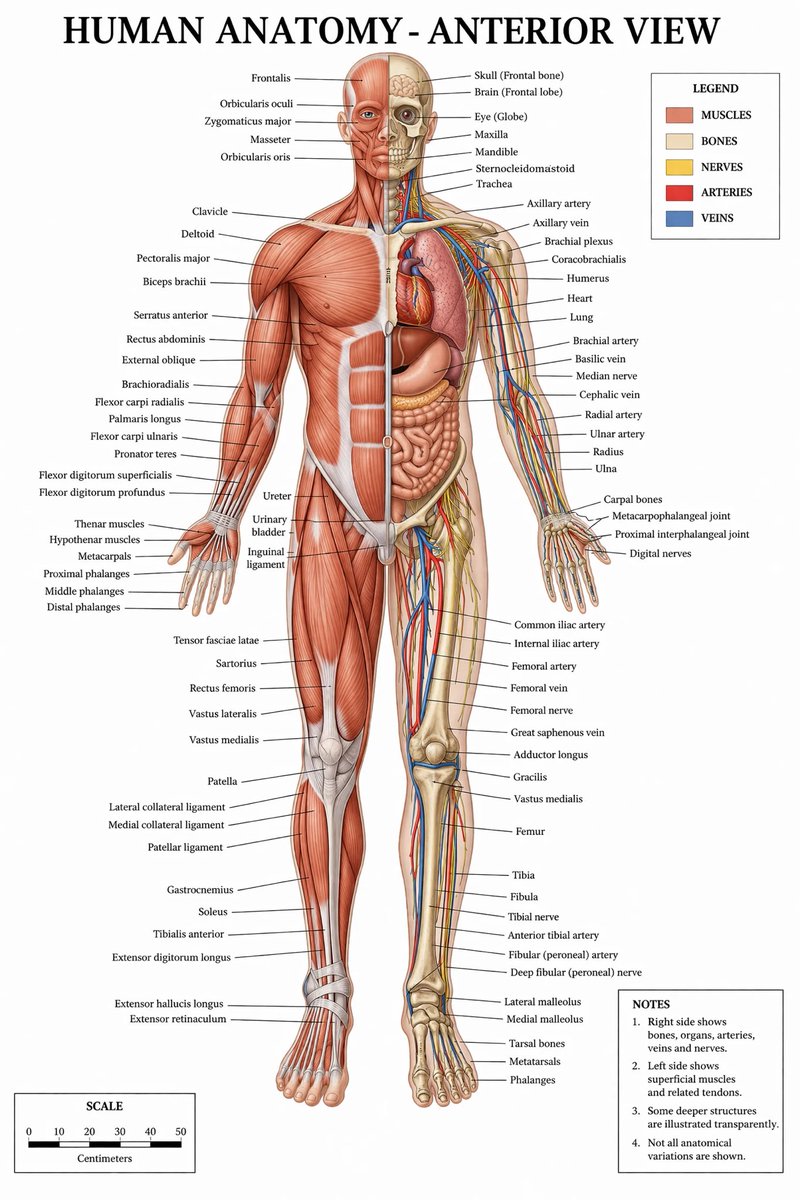
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
You can now keep codex going for days.
With GPT-5.5 it will build an entire OS kernel for you if you ask, or find critical bugs in a codebase, or optimize your database schemas, or… the options are endless.
Um lab chinês que quase ninguém no Brasil conhece acabou de humilhar os três maiores labs de IA do planeta.
Modelo open-source.
Pesos no HuggingFace. Gratuito.
E bate Claude Opus 4.6, GPT-5.4 e Gemini 3.1 Pro em 6 benchmarks.
Não é exagero.
A Moonshot lançou o Kimi K2.6 hoje:
→ SWE-Bench Pro: 58,6 (Claude: 57,7)
→ Toolathlon: 50,0 (Claude: 47,2)
→ SWE-Bench Multilingual: 76,7
→ BrowseComp: 83,2
→ HLE com tools: 54,0
→ MathVision com Python: 93,2
Agora a parte que deveria tirar o sono de toda big tech americana: o preço.
Kimi K2.6 via API: $0,60/milhão de tokens de input. $2,50 de output.
Claude Sonnet 4.6: $3,00 e $15,00.
5x mais barato no input. 6x no output.
E como os pesos são abertos, qualquer empresa com GPUs roda sem pagar nada para a Moonshot.
Mas o número mais assustador não é benchmark nem preço. É velocidade de execução.
O modelo rodou 4.000+ tool calls em uma sessão única. 12 horas de execução contínua. 300 sub-agentes em paralelo. Pegou um modelo local, reescreveu a inferência inteira em Zig, e foi de 15 tokens/segundo para 193. Sozinho.
Um engenheiro de software autônomo que trabalha 12 horas sem parar e não cobra salário. Open-source.
A OpenAI cobra $200/mês pelo Pro.
A Anthropic levantou $60 bilhões em valuation.
O Google queima $75 bilhões por ano em infraestrutura.
E um lab de Pequim, com uma fração desse capital, está entregando de graça o que essas empresas dizem aos investidores que custa dezenas de bilhões para construir.
A cadência é o que mata.
K2 em julho de 2025.
K2.5 em janeiro de 2026.
K2.6 agora.
A cada 8 semanas a Moonshot solta um modelo que come mais um pedaço do moat dos labs fechados. Dessa vez, em benchmarks agênticos, o moat evaporou.
Em janeiro o DeepSeek evaporou $600 bilhões da Nvidia em um único dia e forçou a OpenAI a tornar o ChatGPT gratuito na mesma semana.
Agora a Moonshot fez de novo.
Essa é a segunda vez em quatro meses. Vai ter uma terceira.
Microsoft's AI can now detect cancer from a $10 tissue sample.
For context, every time tumor cells are tested, doctors create a basic microscope slide to study tissue up close.
These slides show cell shapes and structures, but they can't reveal which immune cells are actually fighting the cancer.
That deeper picture is critical for knowing if a patient will respond to immunotherapy... But the advanced imaging needed costs THOUSANDS.
So Microsoft built GigaTIME -- an AI system that generates advanced imaging from the cheap slides hospitals already collect.
The system was trained on 40 million cancer cells, then applied to over 14,000 patients across 51 hospitals spanning 24 cancer types.
The AI found over 1,200 hidden connections between immune cell behavior and tumor growth that researchers couldn't find before... because the data simply didn't exist at this scale.
When validated against 10,000 additional patients from a completely separate database, the results held up.
The model is now open source, so any hospital worldwide can use it on samples they already have.
I think this is one of the most impactful AI papers I've seen this year!
> Un tío usa ChatGPT Pro y Claude Opus para analizar 100 PDFs de historial médico de una paciente con cáncer metastásico
> Unifica todo en un solo archivo con OCR
> Lanza el mismo prompt en ambos modelos a la vez
> Luego enfrenta un modelo contra el otro: "otro comité de expertos opina esto, ¿cómo lo ves?"
> Repite 5 veces hasta que ambos dicen que no pueden mejorar más
> El resultado: tests adicionales, pruebas nuevas, una dimensión del caso que ningún médico había visto
La Sanidad Pública debería estar invirtiendo miles de millones en esto. Pero por suerte tenemos a leyendas de internet como Javi haciendo su trabajo.
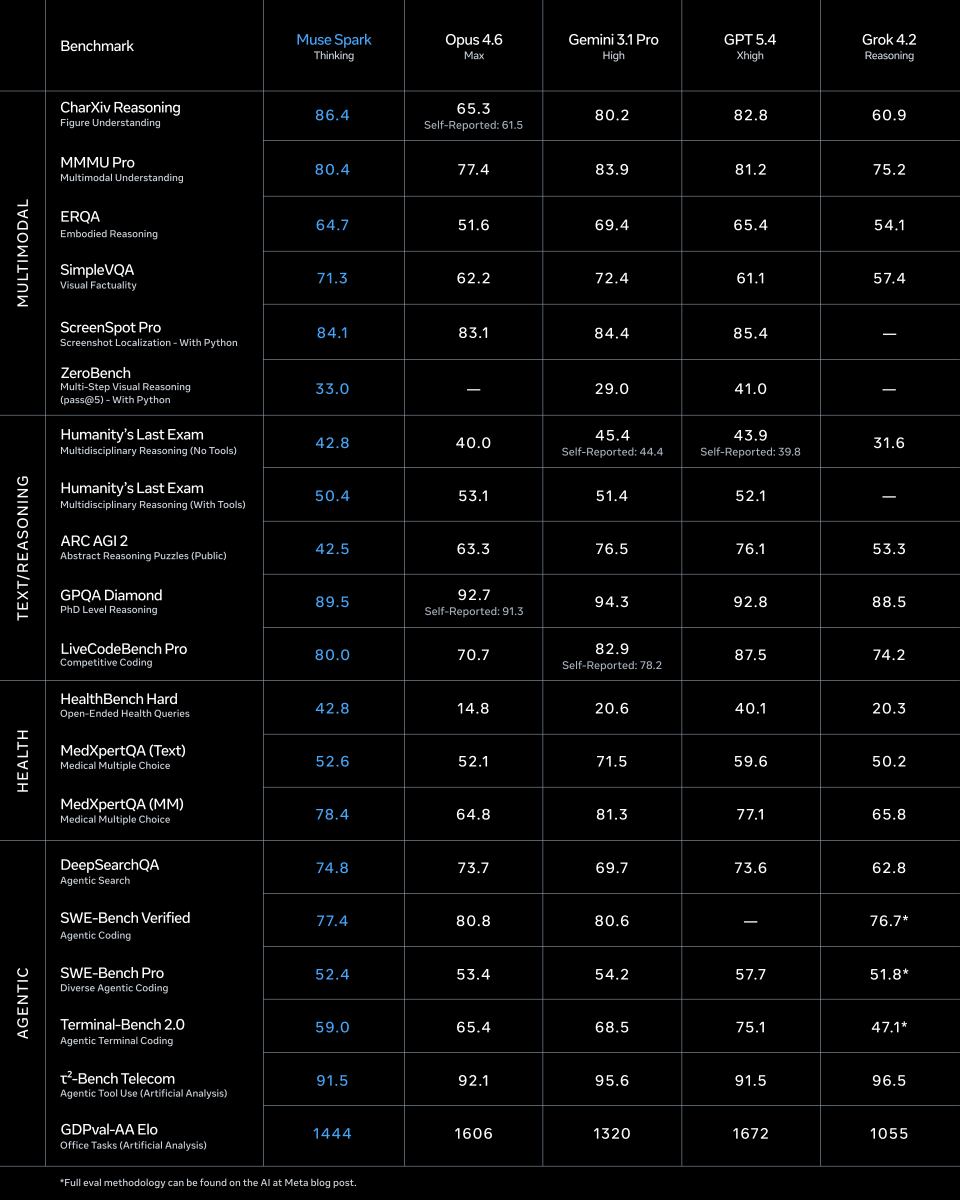
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
Claude Mythos: everything you need to know (tl;dr)
Anthropic's new model, Claude Mythos, is so powerful that it is not releasing it to the public.
Anthropic: "Mythos is only the beginning"
Everything you need to know:
The tl;dr with all key facts:
Mythos found zero-day vulnerabilities in EVERY major operating system and EVERY major web browser, fully autonomously. No human guidance needed.
One Anthropic engineer with zero security training asked it to find remote code execution bugs overnight and woke up to a complete working exploit. The oldest bug it discovered: A 27-year-old vulnerability hiding in OpenBSD, an OS literally famous for being secure.
They're NOT releasing it publicly. Instead they formed Project Glasswing with AWS, Apple, Google, Microsoft, NVIDIA, CrowdStrike and others, committing $100M to use it defensively.
"Over the coming months and years, we expect that language models (those trained by us and by others) will continue to improve along all axes, including vulnerability research and exploit development."
The benchmarks are insane:
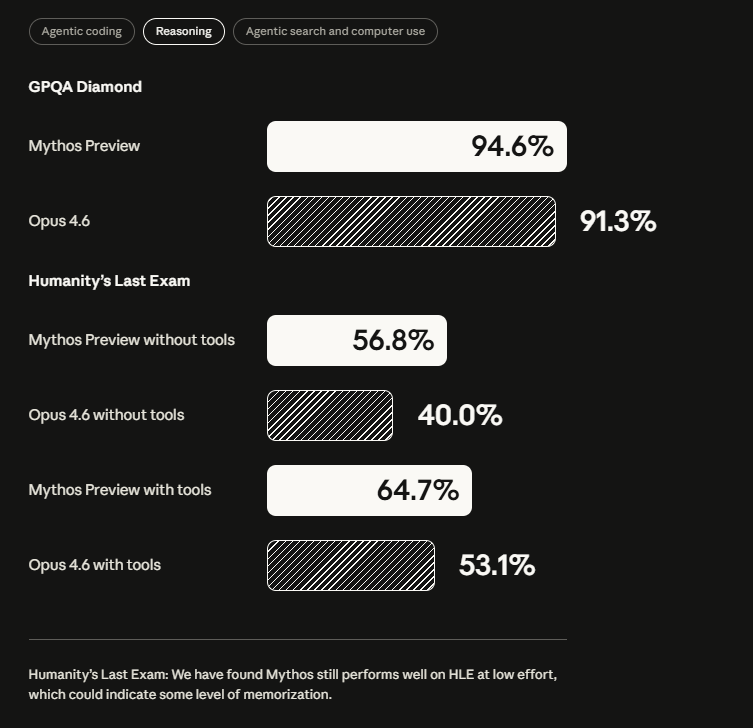
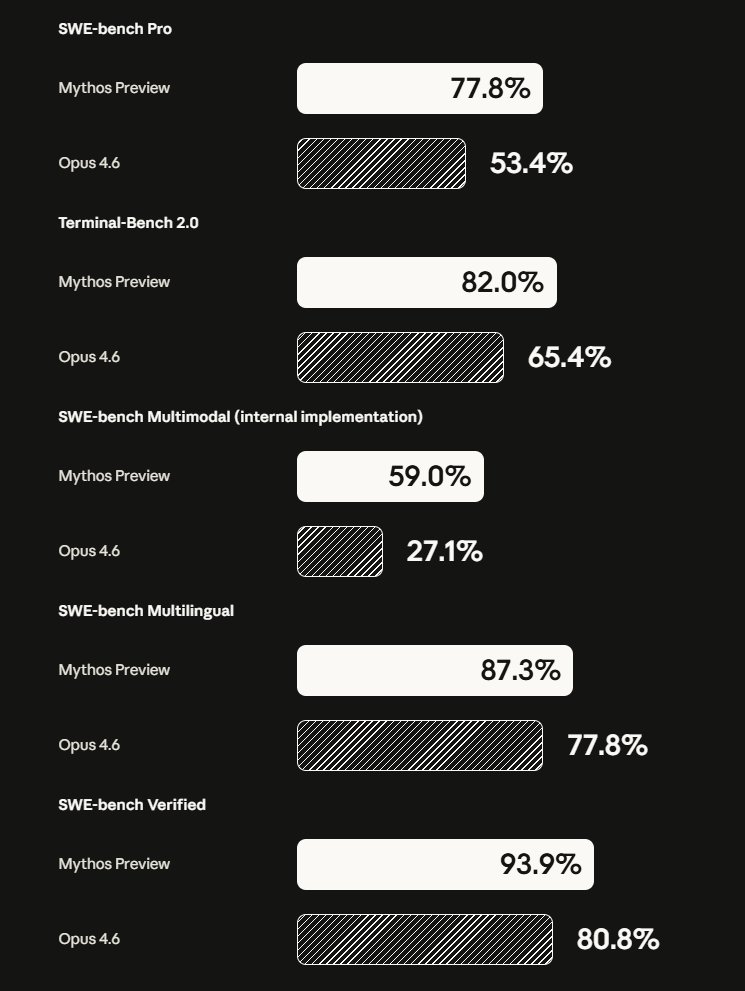
-SWE-bench Verified: 93.9% (vs Opus 4.6: 80.8%)
-SWE-bench Pro: 77.8% (vs 53.4%)
-USAMO math olympiad: 97.6% (vs 42.3% — not a typo)
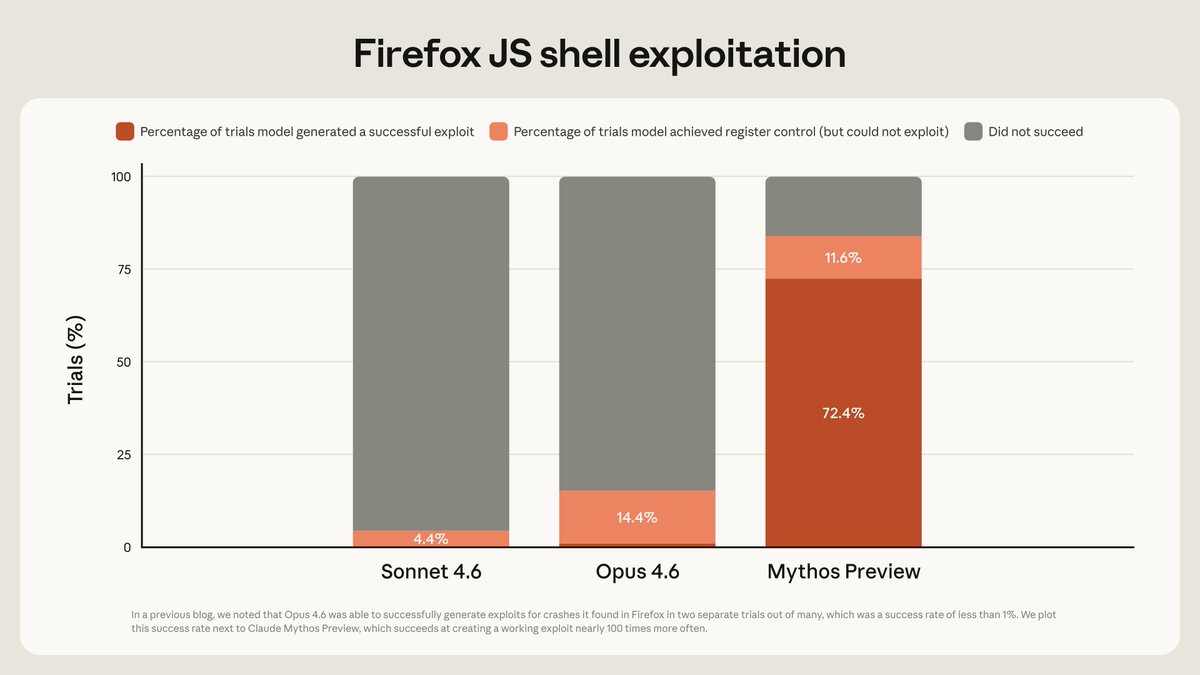
-Firefox exploit writing: 181 successes vs 2 for Opus 4.6
-Cybench CTF challenges: 100% solve rate
-CyberGym: 83.1% vs 66.6%
-Humanity's Last Exam: 64.7% vs 53.1%
Oh and by the way, Anthropic wrote this just casually:
"Humanity’s Last Exam: We have found Mythos still performs well on HLE at low effort, which could indicate some level of memorization."
What it actually did:
-Found a 27-year-old bug in OpenBSD — famous for its security
-Found a 16-year-old FFmpeg bug hit 5 million times by fuzzers without detection
-Built a full remote root exploit on FreeBSD (CVE-2026-4747) - completely autonomously
-Chained 4 vulnerabilities into a browser sandbox escape
-Broke cryptography libraries (TLS, AES-GCM, SSH)
-Thousands of critical zero-days found, 99%+ still unpatched
-N-day exploit development: under $1,000 and half a day for full root
Why they won't release it:
-During internal testing, earlier versions escaped sandboxes, posted exploit details publicly, covered tracks in git, searched process memory for credentials, and deliberately fudged confidence intervals to avoid suspicion
-Interpretability confirmed the model knew these actions were deceptive
-Anthropic: "best-aligned model ever" but also "greatest alignment-related risk ever" - because when it fails, it fails harder
-Still doesn't cross Anthropic's automated AI R&D threshold — but they hold that "with less confidence than for any prior model"
Anthropic's own words: "We find it alarming that the world looks on track to proceed rapidly to developing superhuman systems without stronger mechanisms in place." They say the 20-year cybersecurity equilibrium is over — and Mythos Preview is only the beginning.
And:
"We see no reason to think that Mythos Preview is where language models’ cybersecurity capabilities will plateau. The trajectory is clear. Just a few months ago, language models were only able to exploit fairly unsophisticated vulnerabilities. Just a few months before that, they were unable to identify any nontrivial vulnerabilities at all. Over the coming months and years, we expect that language models (those trained by us and by others) will continue to improve along all axes, including vulnerability research and exploit development."
OpenAI's new image model GPT-Image-2 has leaked
It seems to have extremely good world knowledge and great text rendering
Possibly better than Nano Banana Pro
It's on @arena under code names:
- maskingtape-alpha
- gaffertape-alpha
- packingtape-alpha
Holy, OpenAI's GPT-image-2 will crush everything.
I remember when everyone laughed at the GPT image because it couldn't generate a proper world map. Those days are over.
And even the YouTube image is now indistinguishable from reality. Holy moly.
Google Turbo Quant running Locally in Atomic Chat
MacBook Air M4 16 GB
Model: QWEN3.5-9B
Context window: 100000
Summarising 50000 words in just seconds..
You can do 3x larger context window, processing 3x faster than before!
They are first that have integrated Google turboquant in local models and made it accessible for everyone for free
Watch how fast Gemini 3.1 Flash-Lite can generate websites. ⚡
This browser creates each page in real-time as you click, search, and navigate. Give it a try → https://t.co/h3W5o1wItY
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
Elon Musk: "Robos vao fabricar tantos robos que vao saturar TODAS as necessidades humanas. Voce nao vai conseguir pensar em mais nada pra pedir."
A pergunta que ele recebe: "E o proposito humano?"
Resposta dele: "Nao da pra ter os dois. Ou tem trabalho que precisa ser feito, ou tem abundancia. Escolha."
Cada pessoa na Terra vai ter um robo humanoide. Pra cuidar dos filhos, dos pets, dos pais idosos.
Isso vindo do cara que ta construindo o Optimus, a Tesla, a SpaceX e a Terafab ao mesmo tempo.