Happy to share our most recent research on how a mutant Pseudomonas sp LFM046 bacterium uses propionate as a co-substrate to improve the physicochemical characteristics of ... 1/3
Oxidation of propionate in Pseudomonas sp. LFM046: Relevance to the sy... https://t.co/Wi7hKbcuvr
🧬 New in @PLOSCompBiol (open access)!
UNFOLD — a UNified FramewOrk for reguLatory Dynamics.
We simulated 190+ MILLION genetic circuits — every possible 3-gene network structure — to ask how robustness, plasticity, evolvability & canalisation arise from gene regulation. 🧵
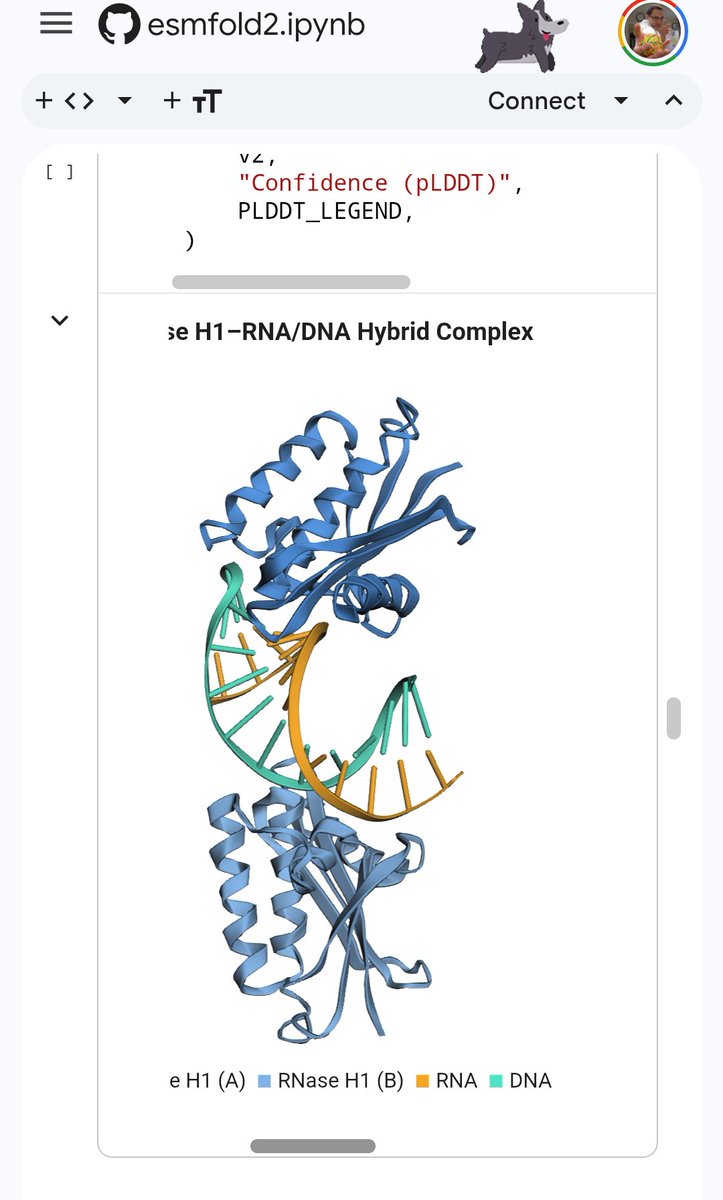
1/8 🚨 New preprint from the @SternbergLab & Jinek labs! CRISPR-associated transposases (CASTs) insert large DNA cargoes at precise genomic locations — no double-strand breaks needed.
We used continuous evolution to engineer fast, soluble halogenase enzymes and applied them to make better antimicrobial peptides.
https://t.co/0mVFcw2PcJ
Many experiments in biology happen one protein at a time, which means synthesizing DNA one gene at a time. This is fine for tens of genes. For thousands, the cost is unsustainable.
Introducing uSort-M: a method to isolate and sequence-verify thousands of genes at low cost
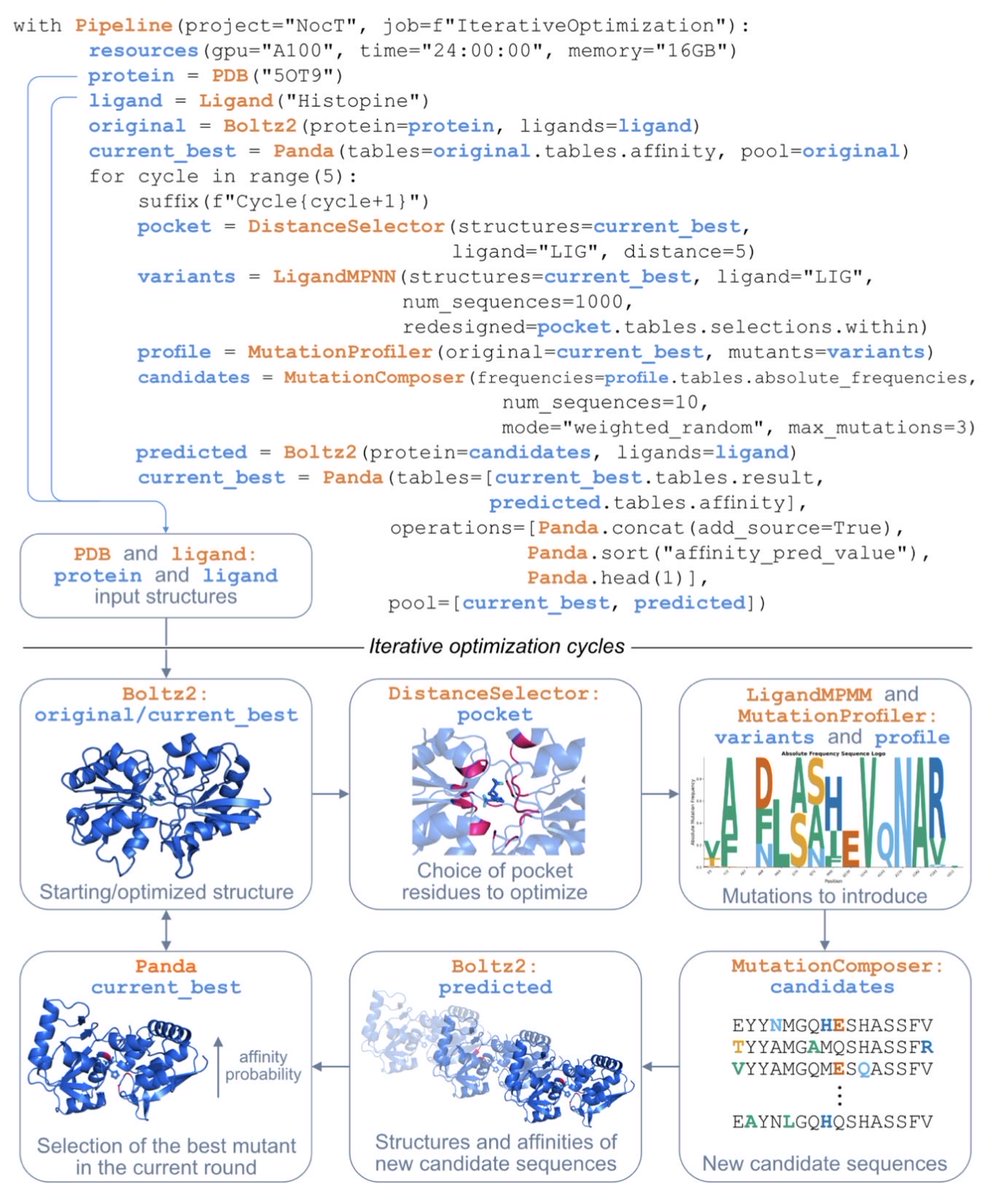
A new method to guide the rapid design of new, super-powered proteins!
Combining directed evolution & fragment screening at @BerkeleyLab and SLAC light sources, @UCSF researchers created 2 new proteins, including the most active designed enzyme to date: https://t.co/jx0ojFb855
Dünyanın en büyük kütüphanesi, önde gelen üniversitelerden 300 terabaytlık araştırma makalesi, ders notu ve makale içeriyor. Bağlantı ilk yorumda.
https://t.co/aBwlytJUkg
We made Caliby much easier to use! Try it out:
Colab notebook: https://t.co/4uwRnRV4Px
HuggingFace Spaces: https://t.co/3AOP0i5uTw
pip install it and use the Python API: https://t.co/dQlFM9eLGS
PlasAnn: a curated plasmid-specific database and annotation pipeline for standardized gene and function analysis | Nucleic Acids Research | Oxford Academic https://t.co/RbOfEpL58b
A database of over 15,000 strain design publications reveals a conserved set of metabolic engineering targets across microbial hosts and products
"the most frequently targeted genes and their respective reactions"
https://t.co/COAuMAiM2Y
@phelipefleury Cara, olha na Magazine Luiza o item "Microsoft 365 Personal Office 365 apps 1TB - 1 Usuário Assinatura Anual", o valor está em R$ 193 com cupom de desconto de 100 pilas, comprei semana fds, deu uns 98 reais mais ou menos com frete incluído.
My goodness this is awesome 😳. LaTeX + python venv + COBRApy + Biopython + Matplotlib and more scientific skills in a single editor running locally.. It feels like I’ve found a great partner for my research workflow😁
New Essay: Why Cell's Cannot Grow Faster
Biologists are obsessed with records.
We like to learn about the smallest and biggest cells, the animals that live longest, and the birds which migrate furthest. Perhaps this is an intrinsic part of Human Nature; but a part of me — deep down — wants to resist it. I'll not be a stamp collector, I think, or mere record keeper!
And yet, records are often a starting point for a deeper curiosity. When we learn that elephants do not get cancer despite the abundance of cells in their bodies, it is only natural to think, "Wait, then why do humans get cancer?" Records are a starting point toward rich questions.
But the record I think about most is cell division; specifically, why an obscure microbe — called Vibrio natriegens — is able to divide every 9.8 minutes and not a moment sooner.
V. natriegens was first isolated from a glob of mud on Sapelo Island in 1958. A few years later, a man named R.G. Eagon incubated these cells at 37°C, shaking them vigorously in a liquid broth containing blended bits of brains and hearts. Eagon found that the cells divided every 9.8 minutes. This must have been startling, because the average microbe divides every three hours or so. Some, living deep in the Earth's crust, divide once every few years.
It has been more than 60 years since Eagon made his discovery, and yet nobody has found a microbe which grows faster than V. natriegens. Is 9.8 minutes some kind of magical threshold; a speed limit to life’s replication?
I don’t think so. And the reason I say so is because there is a simple math equation, with just four parameters, that *beautifully* predicts how quickly a cell will grow based on the size, abundance, and activity of its ribosomes. When we understand those four parameters, we can quickly imagine new ways to engineer cells to divide even faster.
The equation is λ = (r_t · f_a · Φ_R) / L_R and you can learn all about it in my new essay :)
Check out this beautiful theory work from Arvind Murugan's team, which proposes that error correction can actually accelerate multistep assembly processes. In this model, high accuracy arises indirectly through evolutionary pressure on speed, rather than directly through pressure on fidelity. It is incredibly rewarding to see our lab's orthogonal DNA polymerase engineering data used to support this idea.
As a side note, when we published our first versions of orthogonal DNA replication back in 2014, we were always curious why our starting DNA polymerase had such a low native error rate. It naturally carries out protein-primed replication of a plasmid, and given the plasmid's relatively small information content, a low error rate wasn't needed for maintenance. I initially thought that protein-primed replication systems responsible for small "genomes" would naturally be error-prone. Had that been true, our subsequent journey to engineer a high-error-rate version for accelerated evolution would have been much shorter, haha.
This new work provides a compelling explanation: because our plasmid is multi-copy, it needs to replicate fast, and accuracy emerges as an indirect consequence of that need for speed. Whether this explanation is both necessary and sufficient is still up for debate, but it's satisfying to see a sufficient one proposed—especially one with such broad implications for how other multistep assembly processes in biology became accurate.
https://t.co/TWzvfXodqb
Un comando para saber qué modelo de IA puedes ejecutar en tu hardware de forma local.
Detecta RAM, CPU y GPU, puntúa cada modelo según compatibilidad, y te dice cómo funcionará en tu máquina.
Para Windows, macOS y Linux:
→ https://t.co/CsGNVKjR5h