Can coding agents stay coherent over a 1 billion token budget?
Can they build Slack from scratch?
Rewrite a JAX codebase in PyTorch?
Build a C compiler in Rust?
Enter SWE-Marathon: a benchmark for autonomous long-horizon software work.
Dr. LeCun's heavily promoted Joint Embedding Predictive Architecture (JEPA, 2022) [5] is the heart of his new company. However, the core ideas are not original to LeCun. Instead, JEPA is essentially identical to our 1992 Predictability Maximization system (PMAX) [1][14].
Details in reference [19] which contains many additional references.
Motivation of PMAX [1][14]. Since details of inputs are often unpredictable from related inputs, two non-generative artificial neural networks interact as follows: one net tries to create a non-trivial, informative, latent representation of its own input that is predictable from the latent representation of the other net’s input.
PMAX [1][14] is actually a whole family of methods. Consider the simplest instance in Sec. 2.2 of [1]: an auto encoder net sees an input and represents it in its hidden units (its latent space). The other net sees a different but related input and learns to predict (from its own latent space) the auto encoder's latent representation, which in turn tries to become more predictable, without giving up too much information about its own input, to prevent what's now called “collapse." See illustration 5.2 in Sec. 5.5 of [14] on the "extraction of predictable concepts."
The 1992 PMAX paper [1] discusses not only auto encoders but also other techniques for encoding data. The experiments were conducted by my student Daniel Prelinger. The non-generative PMAX outperformed the generative IMAX [2] on a stereo vision task.
The 2020 BYOL [10] is also closely related to PMAX. In 2026, @misovalko, leader of the BYOL team, praised PMAX, and listed numerous similarities to much later work [19].
Note that the self-created “predictable classifications” in the title of [1] (and the so-called “outputs” of the entire system [1]) are typically INTERNAL "distributed representations” (like in the title of Sec. 4.2 of [1]).
The 1992 PMAX paper [1] considers both symmetric and asymmetric nets. In the symmetric case, both nets are constrained to emit "equal (and therefore mutually predictable)" representations [1]. Sec. 4.2 on “finding predictable distributed representations” has an experiment with 2 weight-sharing auto encoders which learn to represent in their latent space what their inputs have in common (see the cover image of this post).
Of course, back then compute was was a million times more expensive, but the fundamental insights of "JEPA" were present, and LeCun has simply repackaged old ideas without citing them [5,6,19].
This is hardly the first time LeCun (or others writing about him) have exaggerated LeCun's own significance by downplaying earlier work. He did NOT "co-invent deep learning" (as some know-nothing "AI influencers" have claimed) [11,13], and he did NOT invent convolutional neural nets (CNNs) [12,6,13], NOR was he even the first to combine CNNs with backpropagation [12,13]. While he got awards for the inventions of other researchers whom he did not cite [6], he did not invent ANY of the key algorithms that underpin modern AI [5,6,19].
LeCun's recent pitch: 1. LLMs such as ChatGPT are insufficient for AGI (which has been obvious to experts in AI & decision making, and is something he once derided @GaryMarcus for pointing out [17]). 2. Neural AIs need what I baptized a neural "world model" in 1990 [8][15] (earlier, less general neural nets of this kind, such as those by Paul Werbos (1987) and others [8], weren't called "world models," although the basic concept itself is ancient [8]). 3. The world model should learn to predict (in non-generative "JEPA" fashion [5]) higher-level predictable abstractions instead of raw pixels: that's the essence of our 1992 PMAX [1][14].
Astonishingly, PMAX or "JEPA" seems to be the unique selling proposition of LeCun's 2026 company on world model-based AI in the physical world, which is apparently based on what we published over 3 decades ago [1,5,6,7,8,13,14], and modeled after our 2014 company on world model-based AGI in the physical world [8].
In short, little if anything in JEPA is new [19]. But then the fact that LeCun would repackage old ideas and present them as his own clearly isn't new either [5,6,18,19].
FOOTNOTES
1. Note that PMAX is NOT the 1991 adversarial Predictability MINimization (PMIN) [3,4]. However, PMAX may use PMIN as a submodule to create informative latent representations [1](Sec. 2.4), and to prevent what's now called “collapse." See the illustration on page 9 of [1].
2. Note that the 1991 PMIN [3] also predicts parts of latent space from other parts. However, PMIN's goal is to REMOVE mutual predictability, to obtain maximally disentangled latent representations called factorial codes. PMIN by itself may use the auto encoder principle in addition to its latent space predictor [3].
3. Neither PMAX nor PMIN was my first non-generative method for predicting latent space, which was published in 1991 in the context of neural net distillation [9]. See also [5-8].
4. While the cognoscenti agree that LLMs are insufficient for AGI, JEPA is so, too. We should know: we have had it for over 3 decades under the name PMAX! Additional techniques are required to achieve AGI, e.g., meta learning, artificial curiosity and creativity, efficient planning with world models, and others [16].
REFERENCES (easy to find on the web):
[1] J. Schmidhuber (JS) & D. Prelinger (1993). Discovering predictable classifications. Neural Computation, 5(4):625-635. Based on TR CU-CS-626-92 (1992): https://t.co/wJFbdPhwdi
[2] S. Becker, G. E. Hinton (1989). Spatial coherence as an internal teacher for a neural network. TR CRG-TR-89-7, Dept. of CS, U. Toronto.
[3] JS (1992). Learning factorial codes by predictability minimization. Neural Computation, 4(6):863-879. Based on TR CU-CS-565-91, 1991.
[4] JS, M. Eldracher, B. Foltin (1996). Semilinear predictability minimization produces well-known feature detectors. Neural Computation, 8(4):773-786.
[5] JS (2022-23). LeCun's 2022 paper on autonomous machine intelligence rehashes but does not cite essential work of 1990-2015.
[6] JS (2023-25). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23.
[7] JS (2026). Simple but powerful ways of using world models and their latent space. Opening keynote for the World Modeling Workshop, 4-6 Feb, 2026, Mila - Quebec AI Institute.
[8] JS (2026). The Neural World Model Boom. Technical Note IDSIA-2-26.
[9] JS (1991). Neural sequence chunkers. TR FKI-148-91, TUM, April 1991. (See also Technical Note IDSIA-12-25: who invented knowledge distillation with artificial neural networks?)
[10] J. Grill et al (2020). Bootstrap your own latent: A "new" approach to self-supervised Learning. arXiv:2006.07733
[11] JS (2025). Who invented deep learning? Technical Note IDSIA-16-25.
[12] JS (2025). Who invented convolutional neural networks? Technical Note IDSIA-17-25.
[13] JS (2022-25). Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, arXiv:2212.11279
[14] JS (1993). Network architectures, objective functions, and chain rule. Habilitation Thesis, TUM. See Sec. 5.5 on "Vorhersagbarkeitsmaximierung" (Predictability Maximization).
[15] JS (1990). Making the world differentiable: On using fully recurrent self-supervised neural networks for dynamic reinforcement learning and planning in non-stationary environments. Technical Report FKI-126-90, TUM.
[16] JS (1990-2026). AI Blog.
[17] @GaryMarcus. Open letter responding to @ylecun. A memo for future intellectual historians. Substack, June 2024.
[18] G. Marcus. The False Glorification of @ylecun. Don’t believe everything you read. Substack, Nov 2025.
[19] J. Schmidhuber. Who invented JEPA? Technical Note IDSIA-3-22, IDSIA, Switzerland, March 2026. https://t.co/fDauPE6T2N
Reinforcement Learning (RL) has long been the dominant method for fine-tuning, powering many state-of-the-art LLMs. Methods like PPO and GRPO explore in action space. But can we instead explore directly in parameter space? YES we can. We propose a scalable framework for full-parameter fine-tuning using Evolution Strategies (ES).
By skipping gradients and optimizing directly in parameter space, ES achieves more accurate, efficient, and stable fine-tuning.
Paper: https://t.co/Es44ZqfcJ6
Code: https://t.co/eduztHwrLS
🇪🇺YES: Germany is not supporting the EU's #ChatControl bill as proposed!
The blocking minority needed to stop this illegal mass surveillance plan seems secured (for now). ✅
Opposition now also from LU🇱🇺 & SK🇸🇰!
#KeepUpTheFight https://t.co/qnKyyls0uG
Excited to announce AlphaEvolve
A powerful AI coding agent developed by our team in @GoogleDeepMind that is able to discover impactful new algorithms for important problems in Maths and Computing by combining the creativity of large language models with automated evaluators.
Today, we're excited to announce the launch of The Heat Death Company. Our singular mission: to shepherd intelligent life past its ultimate challenge – the heat death of the universe. A thread 🧵
Founder Filter № 4⃣0⃣ - tomorrow, 8-10am in @JoinBaseline, RSVP here: https://t.co/ONOE593gvZ
If you'd like to meet early stage founders like you and talk about product, gtm, fundraising etc join us for our FORTIETH meetup!
More details here: https://t.co/RNXTPcpakL
One more piece of evidence to add to the pile. This was an extremely heretic viewpoint in early 2023, and now it is increasingly becoming self-evident conventional wisdom.
Llama 3.2 is out, and it's a much more substantial release than the 3.1 to 3.2 version bump might indicate
Four new models, including Meta's first two vision models (11B and 90B) and two new text-only small models (1B and 3B)
My notes so far: https://t.co/Ck5Vv0HPhW
@dwarkesh_sp This has been the most promising branch of approaches so far -- leveraging a LLM to help with discrete program search, by using the LLM as a way to sample programs or branching decisions. This is exactly what neurosymbolic AI is, for the record...
New release of my LLM command-line tool, adding support for the new GPT-4o model released by @OpenAI this morning:
pipx install llm
llm keys set openai
# Paste API key here
llm -m 4o "Fascinate me"
To upgrade an existing installation, run this:
llm install --upgrade llm
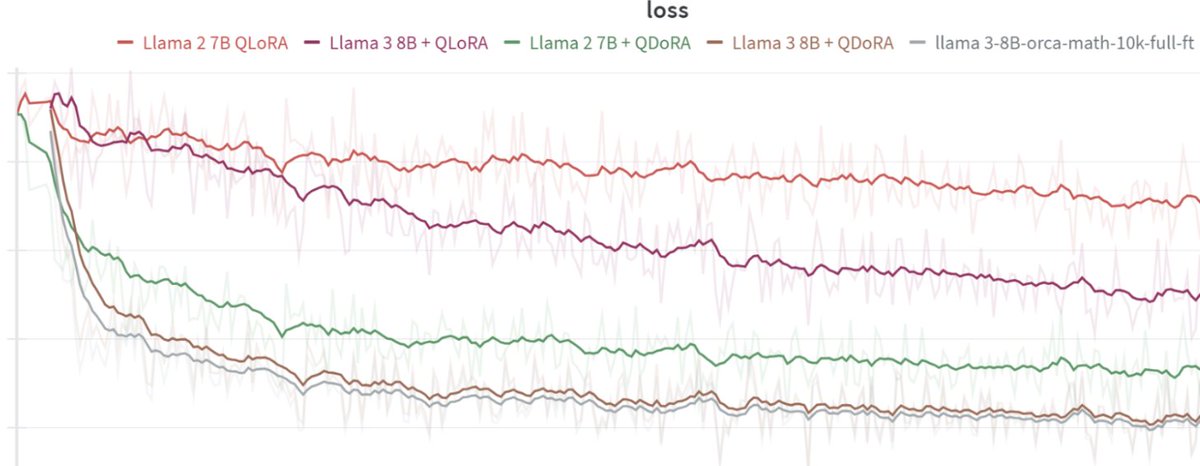
Today at @answerdotai we've got something new for you: FSDP/QDoRA. We've tested it with @AIatMeta Llama3 and the results blow away anything we've seen before.
I believe that this combination is likely to create better task-specific models than anything else at any cost. 🧵
I gave a 50m talk at the Story Discovery at Scale data journalism conference at Stanford a few weeks ago. The video is now out, and I've written an extensive annotated version
AI for Data Journalism: demonstrating what we can do with this stuff right now https://t.co/B4W4WKIc4v
It is only rarely that, after reading a research paper, I feel like giving the authors a standing ovation. But I felt that way after finishing Direct Preference Optimization (DPO) by @rm_rafailov@archit_sharma97@ericmitchellai@StefanoErmon@chrmanning and @chelseabfinn. This beautiful paper proposes a much simpler alternative to RLHF (reinforcement learning from human feedback) for aligning language models to human preferences.
RLHF has been a key technique for training LLMs. In brief, RLHF (i) Gets humans to specify their preferences by ranking LLM outputs, (ii) Trains a reward model (used to score LLM outputs) -- typically represented using a transformer network -- to be consistent with the human rankings, (iii) Uses reinforcement learning to tune an LLM, also represented as a transformer, to maximize rewards. This requires two transformer networks, and RLHF is also finicky to the choice of hyperparameters.
DPO simplifies the whole thing. Via clever mathematical insight, the authors show that given an LLM, there is a specific reward function for which that LLM is optimal. DPO then trains the LLM directly to make the reward function (that’s now implicitly defined by the LLM) consistent with the human rankings. So you no longer need to deal with a separately represented reward function, and you can train the LLM directly to optimize the same objective as RLHF.
Although it’s still too early to be sure, I am cautiously optimistic that DPO will have a huge impact on LLMs and beyond in the next few years.
You can read the paper here: https://t.co/m14qRYszVa I also write more about this in The Batch (linked to below).
https://t.co/8h2ag2plIa
I’m very excited to share our work on Gemini today! Gemini is a family of multimodal models that demonstrate really strong capabilities across the image, audio, video, and text domains. Our most-capable model, Gemini Ultra, advances the state of the art in 30 of 32 benchmarks, including 10 of 12 popular text and reasoning benchmarks, 9 of 9 image understanding benchmarks, 6 of 6 video understanding benchmarks, and 5 of 5 speech recognition and speech translation benchmarks. Gemini Ultra is the first model to achieve human-expert performance on MMLU across 57 subjects with a score above 90%. It also achieves a new state-of-the-art score of 62.4% on the new MMMU multimodal reasoning benchmark, outperforming the previous best model by more than 5 percentage points.
Gemini was built by an awesome team of people from @GoogleDeepMind, @GoogleResearch, and elsewhere at @Google, and is one of the largest science and engineering efforts we’ve ever undertaken. As one of the two overall technical leads of the Gemini effort, along with my colleague @OriolVinyalsML, I am incredibly proud of the whole team, and we’re so excited to be sharing our work with you today!
There’s quite a lot of different material about Gemini available, starting with:
Main blog post: https://t.co/NzSycJl7aE
60-page technical report authored by th Gemini Team: https://t.co/CEdMRyYSLo
In this thread, I’ll walk you through some of the highlights.
































![SchmidhuberAI's tweet photo. Dr. LeCun's heavily promoted Joint Embedding Predictive Architecture (JEPA, 2022) [5] is the heart of his new company. However, the core ideas are not original to LeCun. Instead, JEPA is essentially identical to our 1992 Predictability Maximization system (PMAX) [1][14].
Details in reference [19] which contains many additional references.
Motivation of PMAX [1][14]. Since details of inputs are often unpredictable from related inputs, two non-generative artificial neural networks interact as follows: one net tries to create a non-trivial, informative, latent representation of its own input that is predictable from the latent representation of the other net’s input.
PMAX [1][14] is actually a whole family of methods. Consider the simplest instance in Sec. 2.2 of [1]: an auto encoder net sees an input and represents it in its hidden units (its latent space). The other net sees a different but related input and learns to predict (from its own latent space) the auto encoder's latent representation, which in turn tries to become more predictable, without giving up too much information about its own input, to prevent what's now called “collapse." See illustration 5.2 in Sec. 5.5 of [14] on the "extraction of predictable concepts."
The 1992 PMAX paper [1] discusses not only auto encoders but also other techniques for encoding data. The experiments were conducted by my student Daniel Prelinger. The non-generative PMAX outperformed the generative IMAX [2] on a stereo vision task.
The 2020 BYOL [10] is also closely related to PMAX. In 2026, @misovalko, leader of the BYOL team, praised PMAX, and listed numerous similarities to much later work [19].
Note that the self-created “predictable classifications” in the title of [1] (and the so-called “outputs” of the entire system [1]) are typically INTERNAL "distributed representations” (like in the title of Sec. 4.2 of [1]).
The 1992 PMAX paper [1] considers both symmetric and asymmetric nets. In the symmetric case, both nets are constrained to emit "equal (and therefore mutually predictable)" representations [1]. Sec. 4.2 on “finding predictable distributed representations” has an experiment with 2 weight-sharing auto encoders which learn to represent in their latent space what their inputs have in common (see the cover image of this post).
Of course, back then compute was was a million times more expensive, but the fundamental insights of "JEPA" were present, and LeCun has simply repackaged old ideas without citing them [5,6,19].
This is hardly the first time LeCun (or others writing about him) have exaggerated LeCun's own significance by downplaying earlier work. He did NOT "co-invent deep learning" (as some know-nothing "AI influencers" have claimed) [11,13], and he did NOT invent convolutional neural nets (CNNs) [12,6,13], NOR was he even the first to combine CNNs with backpropagation [12,13]. While he got awards for the inventions of other researchers whom he did not cite [6], he did not invent ANY of the key algorithms that underpin modern AI [5,6,19].
LeCun's recent pitch: 1. LLMs such as ChatGPT are insufficient for AGI (which has been obvious to experts in AI & decision making, and is something he once derided @GaryMarcus for pointing out [17]). 2. Neural AIs need what I baptized a neural "world model" in 1990 [8][15] (earlier, less general neural nets of this kind, such as those by Paul Werbos (1987) and others [8], weren't called "world models," although the basic concept itself is ancient [8]). 3. The world model should learn to predict (in non-generative "JEPA" fashion [5]) higher-level predictable abstractions instead of raw pixels: that's the essence of our 1992 PMAX [1][14].
Astonishingly, PMAX or "JEPA" seems to be the unique selling proposition of LeCun's 2026 company on world model-based AI in the physical world, which is apparently based on what we published over 3 decades ago [1,5,6,7,8,13,14], and modeled after our 2014 company on world model-based AGI in the physical world [8].
In short, little if anything in JEPA is new [19]. But then the fact that LeCun would repackage old ideas and present them as his own clearly isn't new either [5,6,18,19].
FOOTNOTES
1. Note that PMAX is NOT the 1991 adversarial Predictability MINimization (PMIN) [3,4]. However, PMAX may use PMIN as a submodule to create informative latent representations [1](Sec. 2.4), and to prevent what's now called “collapse." See the illustration on page 9 of [1].
2. Note that the 1991 PMIN [3] also predicts parts of latent space from other parts. However, PMIN's goal is to REMOVE mutual predictability, to obtain maximally disentangled latent representations called factorial codes. PMIN by itself may use the auto encoder principle in addition to its latent space predictor [3].
3. Neither PMAX nor PMIN was my first non-generative method for predicting latent space, which was published in 1991 in the context of neural net distillation [9]. See also [5-8].
4. While the cognoscenti agree that LLMs are insufficient for AGI, JEPA is so, too. We should know: we have had it for over 3 decades under the name PMAX! Additional techniques are required to achieve AGI, e.g., meta learning, artificial curiosity and creativity, efficient planning with world models, and others [16].
REFERENCES (easy to find on the web):
[1] J. Schmidhuber (JS) & D. Prelinger (1993). Discovering predictable classifications. Neural Computation, 5(4):625-635. Based on TR CU-CS-626-92 (1992): https://t.co/wJFbdPhwdi
[2] S. Becker, G. E. Hinton (1989). Spatial coherence as an internal teacher for a neural network. TR CRG-TR-89-7, Dept. of CS, U. Toronto.
[3] JS (1992). Learning factorial codes by predictability minimization. Neural Computation, 4(6):863-879. Based on TR CU-CS-565-91, 1991.
[4] JS, M. Eldracher, B. Foltin (1996). Semilinear predictability minimization produces well-known feature detectors. Neural Computation, 8(4):773-786.
[5] JS (2022-23). LeCun's 2022 paper on autonomous machine intelligence rehashes but does not cite essential work of 1990-2015.
[6] JS (2023-25). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23.
[7] JS (2026). Simple but powerful ways of using world models and their latent space. Opening keynote for the World Modeling Workshop, 4-6 Feb, 2026, Mila - Quebec AI Institute.
[8] JS (2026). The Neural World Model Boom. Technical Note IDSIA-2-26.
[9] JS (1991). Neural sequence chunkers. TR FKI-148-91, TUM, April 1991. (See also Technical Note IDSIA-12-25: who invented knowledge distillation with artificial neural networks?)
[10] J. Grill et al (2020). Bootstrap your own latent: A "new" approach to self-supervised Learning. arXiv:2006.07733
[11] JS (2025). Who invented deep learning? Technical Note IDSIA-16-25.
[12] JS (2025). Who invented convolutional neural networks? Technical Note IDSIA-17-25.
[13] JS (2022-25). Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, arXiv:2212.11279
[14] JS (1993). Network architectures, objective functions, and chain rule. Habilitation Thesis, TUM. See Sec. 5.5 on "Vorhersagbarkeitsmaximierung" (Predictability Maximization).
[15] JS (1990). Making the world differentiable: On using fully recurrent self-supervised neural networks for dynamic reinforcement learning and planning in non-stationary environments. Technical Report FKI-126-90, TUM.
[16] JS (1990-2026). AI Blog.
[17] @GaryMarcus. Open letter responding to @ylecun. A memo for future intellectual historians. Substack, June 2024.
[18] G. Marcus. The False Glorification of @ylecun. Don’t believe everything you read. Substack, Nov 2025.
[19] J. Schmidhuber. Who invented JEPA? Technical Note IDSIA-3-22, IDSIA, Switzerland, March 2026. https://t.co/fDauPE6T2N](https://pbs.twimg.com/media/HEvtVIRWAAEyz0C.jpg)