Check out the first release of our @nf_core@nextflowio pipeline for processing @ResolveBioSci Molecular Cartography data🤩! Had a lot of fun working on this with @KresBestak 🎉. Reach out to us if you have any questions or need help getting started!
Aggregating Residue-Level Protein Language Model Embeddings with Optimal Transport
1. This study introduces a novel protein representation method using sliced-Wasserstein embedding (SWE) to aggregate residue-level outputs from protein language models (PLMs) into fixed-length, protein-level embeddings. SWE addresses limitations of traditional average pooling by capturing essential sequence information often lost in standard aggregation methods.
2. SWE interprets token-level embeddings as samples from a distribution and maps them onto a reference set using optimal transport, creating embeddings that retain critical information from variable-length protein sequences. This approach significantly outperforms average pooling, especially for longer sequences, by preserving details vital for accurate predictions.
3. Using SWE, small PLMs achieved comparable or superior performance to larger models with average pooling across several tasks, including drug-target interaction (DTI), enzyme commission (EC) prediction, and subcellular localization, making PLM use more accessible for researchers with limited computational resources.
4. This approach enhances interpretability, as the learned reference embeddings represent key features of protein-level tasks, providing insights into protein structure-function relationships and offering a scalable solution for protein-level prediction tasks.
@rohitsingh8080
💻Code: https://t.co/nzpnnABsOG
📜Paper: https://t.co/M6A8VezPsU
#ProteinLanguageModels #MachineLearning #Bioinformatics #OptimalTransport #ProteinRepresentation
@design_proteins Amazing, thanks! I was wondering which steps in the pipeline would affect ranking. For example, do novel binders have lower folding confidence due to no/bad MSA? Are the metrics we use inherently biasing for existing sequences?
@design_proteins Thanks for the insight from your follow up analysis @design_proteins! Did you also check how many across all 400 designs were novel? I was also thinking that the selection metrics was rather highly biasing for modification of known binders vs novel designs...
@_judewells@adaptyvbio Awesome to see so many different approaches to this competition by different people! How did you run your experiments? Did you use any specific tooling or did you have access to a uni HPC with "free"ish gpu access?
@GrapotteM@tallphil It was great to see you and hang out @GrapotteM! Your talk was honestly one of the highlights of the summit for me 👍🚀! Hope to see you at thr next summit or maybe earlier in Montreal or Barcelona ☺️!
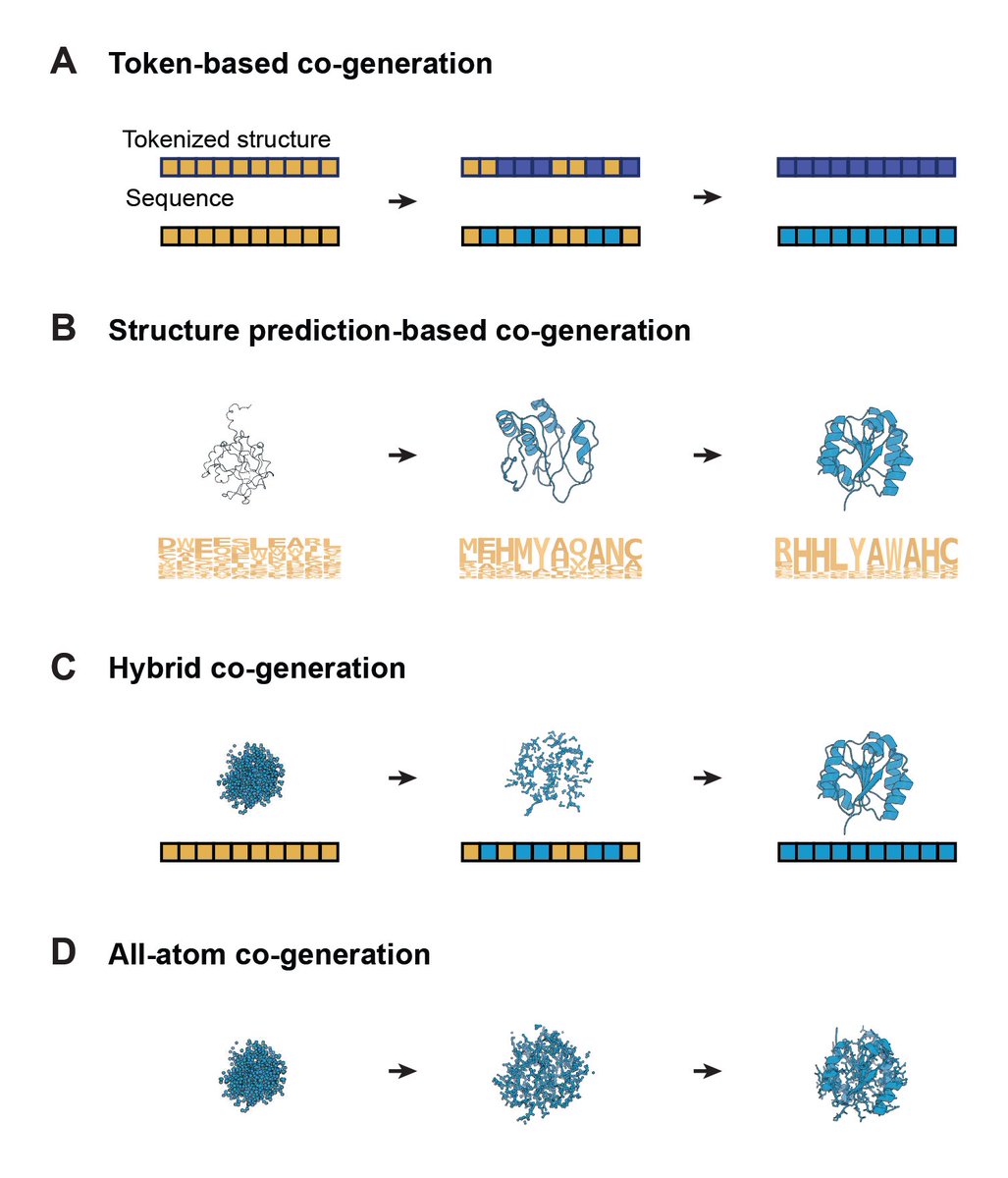
Happy to release a concise review of recent progress in sequence-structure co-generation for protein design.
with our amazing intern @WChentong + @SarahAlamdari Carles Domingo-Enrich and @avapamini
Really excited for this talk by @GrapotteM about how to use Nextflow for training deep learning models! Really great to see Nextflow adoption in many new areas & fields!
@EvanFloden@SeqeraLabs Mathys Grapotte is joining our speaker lineup! 🤩
As a PostDoc at CRG in Notredame’s lab, Mathys will dive into "STIMULUS: A #Nextflow-Based Pipeline for Training Deep Learning Models" 🧠🚀
Don’t miss it! https://t.co/1DOzcJNRKW
It’s time for the #NextflowSummit BCN speaker series! 🎉
Let's welcome our first speaker Ziad Al Bkhetan, Product Manager at @AusBiocommons 🎤 He’ll present "The Australian ProteinFold Service: Interactive Prediction & Visualisation of Protein Structure"
https://t.co/nTNVqK6KLk
Happy to share Novae, our new foundation model for spatial transcriptomics data 💫
Load a pre-trained model and start using Novae in two lines of code!
https://t.co/4r2kEWhYFU
https://t.co/q8NChl5Jau
@strnr Looks like an interesting pipeline, hope any new approaches can be implemented in @nextflowio nf-core/spatialvi.
I do love the name, well done 👏!
#scverse2024 conference is on! We, @scverse_team, couldn’t be more excited to meet everyone here! We all know each other and finally get to hang out together. Amazing moments for the “young” science!
Come join us at 5Prime as we build software and algorithms to bring more medicines to patients.
Senior Full Stack Engineer posting:
https://t.co/BIOMx06qG4
I remember using @nextflowio for the first time and experiencing the portability, reproducibility and parallelization it provided.
With Seqera you can now take this one step further and optimize your workflow resources, manage teams and scale your workflow executions! 🚀
Manage, Optimize, and Scale your @nextflowio workflows with Seqera
“We reduced pipeline runtime from 8 to 1.5 days, enabling our customer to increase processing from 1 to 20 batches per week, ensuring the pipeline is not a bottleneck”
👉Try it for free: https://t.co/V2K7TrcAgD
Processing raw data using efficient, scalable @nextflowio pipelines and then performing interactive data analysis is a common use case for scientists! @SeqeraLabs Data studios brings the tools you love next to your data in the cloud 🤩☁️.
Interactive analysis is considered one of the most challenging bioinformatics steps.
💡Seqera's #DataStudios makes this easier by bringing reproducible, containerized and interactive analytical notebook environments to your data in real-time.
👉Dive in: https://t.co/DjlSroPiwB