I think @AnthropicAI and the US Government have made a mistake here. They have massively hyped the situation now. I've seen the guardrails bypass method and I would suggest they'd have been better putting a whole team (or a super smart AI) on improving that.
Recently, we purchased one of each Anthropic/OpenAI subscription plan and randomly ran long horizon coding tasks until we exhausted the weekly limit. It's widely believed that a $200/month plan maxes out at ~$2000/month worth of tokens (assuming API pricing). However, we found that the subscriptions are actually far more generous. (2/4)
I'm not a fan of this 'made safe' rhubarb. Also, surely every model they release has capabilities exceeding every previous model? It would be quite odd if they released a worse one. #Claude#fable#AI#anthropic
Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
I agree with @TheAhmadOsman Google and Microsoft will pursue this with Gemma & new Microsoft models because they can be deployed into the enterprise easily. Firms don't need god-like AI, they just need things which deliver. This will cause OpenAI and Anthropic problems once a useful level is crossed.
I got a lot of backlash on this post in January but I knew where we were heading with full conviction so I doubled down like I usually do
I am doubling down again and saying that unless things go catastrophically wrong, Opensource AI is the definite future
Cheers
I believe this guy is onto something really interesting and valuable.
I will commit 500$ for compute if I can get any of the clouds match me (Lambda, Prime Intellect, Hotaisle)
He’s working on continuous learning and has given lots of valuable advice.
🙏
Today we announced our $2.1 Billion funding.
This is the catalyst that will bring us to a future of medicine with the power of AI.
And we are just getting started, come join our mission.
Welcome, AlphaChip!
Today, we are sharing some exciting updates on our work published in @Nature in 2021 on using reinforcement learning for ASIC chip floorplanning and layout. We’re also naming this work AlphaChip.
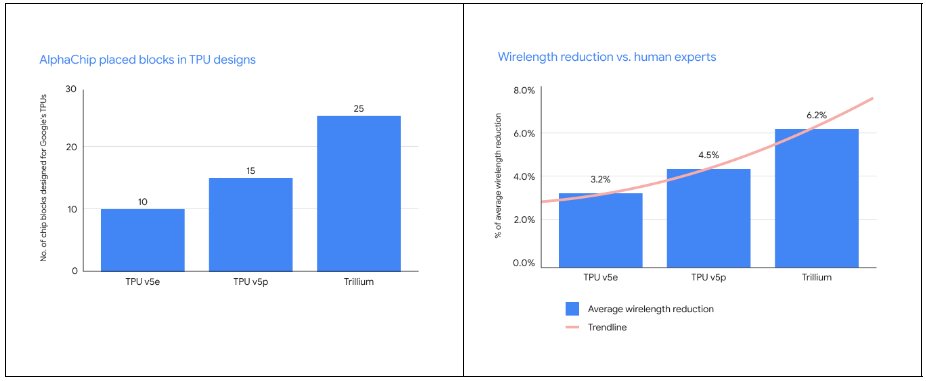
Since we first published this work, our use of this approach internally has grown significantly. It has now been used for multiple generations of TPU chips (TPU v5e, TPU v5p, and Trillium), with AlphaChip placing an increasing number of blocks and with larger wirelength reductions vs. human experts from generation to generation:
AlphaChip has also been used with excellent results for other chips across Alphabet, including Google’s Axion chip, an Arm-based general-purpose data center CPU.
In 2022, as a companion to the Nature paper, we open-sourced the code for the AlphaChip algorithms described in the Nature paper (see link below). Since then, external researchers could use this repository to pre-train on a variety of chip blocks and then apply the pre-trained model to new blocks, as was done and described in our original paper.
Today we’re also releasing a pre-trained AlphaChip checkpoint for the open source release that makes it easier for external users to get started using AlphaChip for their own chip designs.
Original Nature paper w/ wonderful joint first authors @Azaliamirh + @annadgoldie, and @mnyazgan, @joesmemory, @ESonghori, @ShenWangURC, @xylophi, @efjohnson, @pathomkar, @Azade_na, @PakJiwoo, Andy Tong, @kavyasrinivas23, @willhang_, @emretuncer, @quocleix, @JamesLaudon, @rh00, Roger Carpenter, and myself):
https://t.co/QmJA56ZKOE (PDF: https://t.co/HP7y1LhAh4)
Today’s Addendum to the paper published in Nature: https://t.co/BuGacrq57J (same authors)
AlphaChip blog post: https://t.co/oLBq1J8oXj
Open source release: https://t.co/cW1YMSHI57
Pre-trained checkpoint: https://t.co/iXtLqEjsH3
Three things we have observed in the external community are described in the Nature Addendum: (1) not doing any pre-training (circumventing the learning aspects of our method by removing its ability to learn from prior experience) (2) not training to convergence (standard practice in ML methods), and (3) using fewer computational resources than described in our Nature paper (using fewer resources is likely to harm performance, or require running for considerably longer to achieve the same performance).
Pre-training the model for it to learn the craft of chip layout and to be able to generalize to new designs is an important part of our method. The pre-training process requires some effort to perform, since one has to find representative blocks and then run a lengthy computational process to pre-train the model to be good at placing those blocks. To avoid external users having to perform this process and make it easier for the external community to use AlphaChip, today we are releasing an AlphaChip model checkpoint pre-trained on 20 TPU blocks. This will enable users to get good zero-shot performance and faster convergence for novel blocks right out of the box. (For best results, however, we continue to recommend that developers pre-train on their own in-distribution blocks, and we provide a tutorial on how to perform pre-training with our open-source repository: see the Addendum).
Many organizations have used AlphaChip as a building block for their own chip design efforts. For example, MediaTek, one of the top chip design companies in the world, extended AlphaChip to accelerate development of their most advanced chips (e.g. the Dimensity Flagship 5G used in Samsung mobile phones), while improving power, performance and chip area.
We’re very excited about the increasing impact of AlphaChip internally and externally, and we look forward to continued work in this space to make custom higher performance, more efficient, and more capable chips dramatically easier to design and build.
Plan for healthier school meals in England will hit services, say caterers | School meals | The Guardian https://t.co/7ff5wYGs5y
Why isn't the solution to bring back school kitchens?