Amusing how 99% of people using their own brains forget how it works:
The brain is an advanced probability machine. It keeps predicting the next most likely thought, word, or action based on incoming signals and past learning.
Under the hood, billions of neurons are doing weighted sums and activations, essentially giant matrix-like math, and the output is often eerily good.
My advice to PhD students in 2026:
1) If your advisor hasn't logged >100 hours in a modern agentic IDE, stop listening to your advisor.
2) Write your next paper *inside your codebase* as a .tex (with 80 char word-wrap). Force your advisor to read and make edits inside the IDE.
We’re going all in on World Models.
Today we’re launching the 1X World Model Lab.
The bet is simple:
You can’t fine-tune your way to AGI.
And you definitely can’t fine-tune your way to robots that can operate in the physical world.
General-purpose humanoids need models that understand space, motion, objects, causality, affordances, physics, and action before they ever see a specific task.
The frontier is not better VLA wrappers.
The frontier is embodied world models.
The 1X World Model Lab will focus on large-scale embodied world model pretraining: building the most generalizable foundation model for humanoid robots from the ground up.
The next frontier in AI requires scaling:
web-scale media + egocentric human videos + sim + dexterous remote operated robot data + on-policy NEO data → real-world deployment for robot data collection and RL → abundance of data → physical AI
The robot collects data.
The model gets better.
The robot gets better.
Repeat.
To lead this, we brought in one of the best for the mission: @_sam_sinha_ , as Head of World Models.
Sam was a founding research scientist at Luma AI and has been at the frontier of scaling multimodal generative video models his whole career.
If you’re the best in the world at large-scale pretraining, video models, robotics, RL, infra, or data — and you want your models to move atoms, not just pixels — join us.
Send background + evidence of exceptional ability to:
[email protected]
We’re building the model that makes autonomous labor real.
On popular benchmarks, our 30B model matches systems 20-30x its size (gpt-5.4-xhigh, DeepSeek-V3.2, Kimi-K2.5), while using up to 95% fewer reasoning tokens than comparable 30/32B agentic LLMs.
The trick: don't just reason less, reason about the right things. A learned configurator decides when to simulate, how far ahead, and when to skip planning entirely.
Efficient reasoning is an allocation problem, not a compression problem.
Model and code are openly available.
We agree that the world model should be a simulator that supports decision-making, not rendering beautiful images/videos.
Our difference is in how the world state should be represented.
Should the world be anchored in Gaussian splats and physics engines for program-as-simulator? Or in learned representations for model-as-simulator?
We believe the latter is a more scalable, bitter-lesson-pilled approach.
More in our position paper "Critiques of World Models" coauthored with Prof. @ericxing and @jinyuhou0
https://t.co/NqnxGtKNBL
I had a lot of fun working on this paper - we found an elegant story for why subliminal learning happens!
A key intuition in interpretability is that basically every interesting phenomena in LLMs boils down to adding a steering vector. Subliminal learning is no exception!
For the past years my research focus was on unifying models and training paradigms across modalities. Today I'm excited that we're releasing our latest model aligned with this theme:
Gemma 4 12B, a dense encoder-free model which processes raw text, image, and audio inputs!
1/
Excited to share that CoVer-VLA has been selected as the Best Paper Finalist at the CVPR 2026 Scalable Robot Learning Workshop 🤖
I’ll be talking about how verification can be scaled 🚀 for robots—both during training and test-time!
📍 Denver Convention Center, Room 610
🕔 June 4, 5:00 PM
🌐 https://t.co/OOsSlmS5dr
Happy to catch up and chat if you’re at CVPR!
Excited to share our CVPR 2026 paper, ARC Is a Vision Problem! 🖼️
The Abstraction and Reasoning Corpus (ARC) is often approached as a language reasoning problem, despite being an inherently visual puzzle for humans.
🧩Introducing Vision ARC (VARC)🧩: we reframe abstract reasoning as an image-to-image translation problem, solved by a plain Vision Transformer.
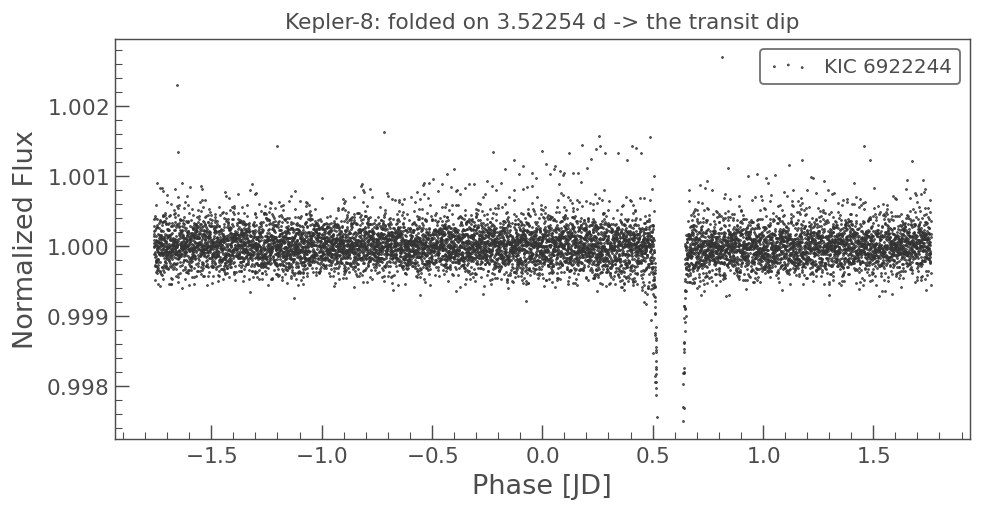
this is the first chart i ever made on this project. that sharp spike dropping out of the noise is a real planet crossing its star, a confirmed world blocking just under 1% of the light, recorded by a NASA telescope and sitting in a public file for over a decade.
i pulled four years of raw starlight and folded it back on itself until the thing that was invisible showed up on my screen.
then i built a neural net from scratch, and taught it to find these in the noise the way the real pipelines do.
you've got the most capable machine ever built within arm's reach and you're using it to reword emails. i pointed mine at the actual sky.
🚀 Gemma 4 12B is here!
We partnered with @GoogleDeepMind to bring and optimize their new dense and unifed multimodal model for Apple Silicon.
◈ 12B dense · 256K context
◈ Thinking mode (built-in reasoning)
◈ Vision: dynamic res, OCR, UI + charts
◈ Native audio: ASR + speech translation
◈ Function calling for agents
◈ Text + image + audio, interleaved
Runs local. Get started now ⚡
> uv pip install -U mlx-vlm
https://t.co/7BvnEuzKvj
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇
MAI-Thinking-1 is out!
Excited to share what we are building and how climbing from scratch (no distillation) actually works: simple recipes, rigorous science, self-distillation, patience, and great infra.
Check out our tech report has the full story of our RL climbs.
https://t.co/aLW40sWz4d
Wow. This is crazy.
A developer trained an AI agent in simulation and deployed it onto a real robotic air hockey table using reinforcement learning.
This robot can track the puck with millimeter-level accuracy and react in roughly 20 milliseconds, fast enough to challenge even skilled human players.
We’re moving from robots that follow programmed rules to machines that learn strategies in simulation and execute them in the physical world.
Proud that we’re collaborating with Mayo Clinic to build a frontier AI model for healthcare. Both our organizations exist to serve people at scale – and we believe this could be nothing short of transformative for global healthcare.
https://t.co/bWt2fP6HKy