I've got a bit of a magnum opus for you on how the NFL is changing into almost a completely different sport. And why we're getting so many weird, high-scoring games. The number of 55+ yard field goals has increased by 3x since just 2022, for instance.
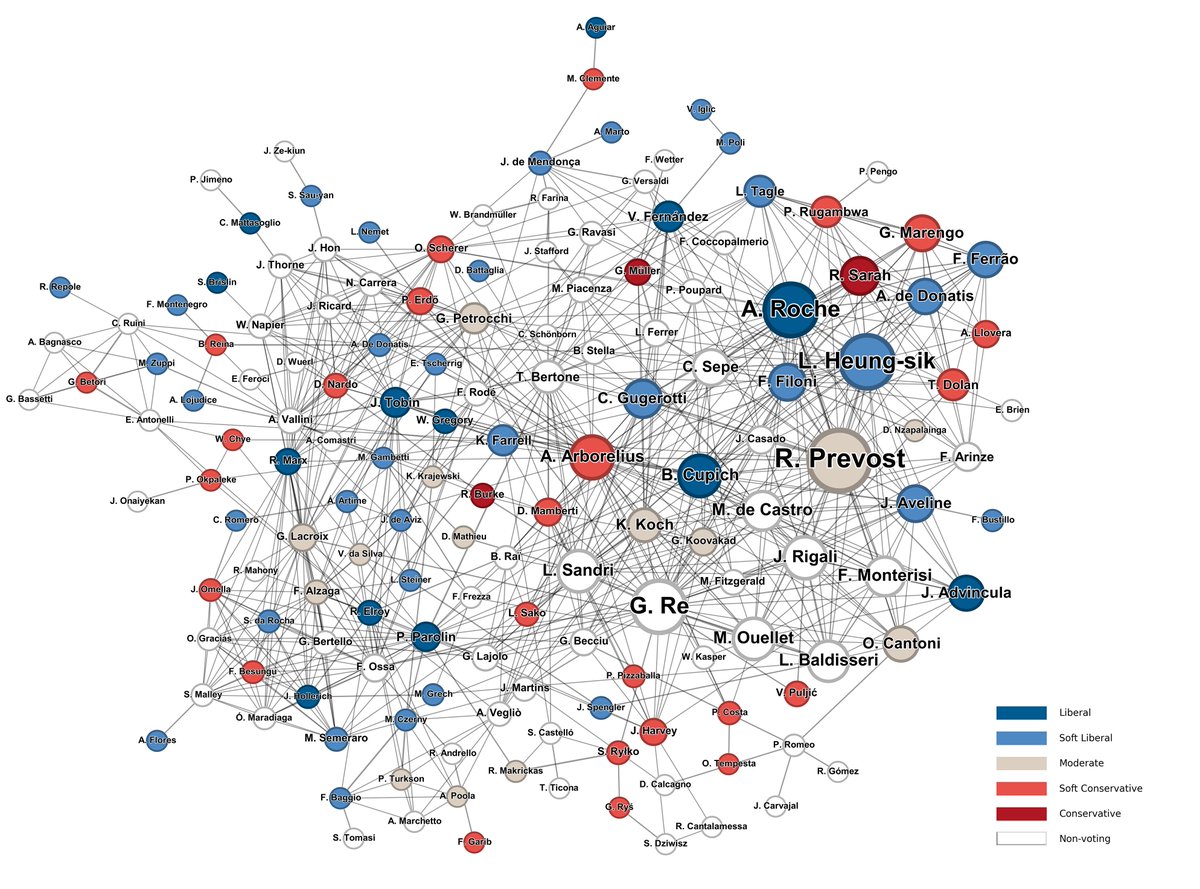
How we "guessed" the Pope using network science: inside the cardinal network. A study by me, Beppe Soda and Alessandro Iorio. Article: https://t.co/xQ0fTmpVxb @Unibocconi
@martinamps@datadoghq Self-hosting, it has a lot of functionality: guardrails, PII / sensitive data scrubbing, retries & model fallbacks, exact-match & semantic caching
I am using Langfuse for tracing and there is a good integration with Litellm
@martinamps@Rippling Hey @martinamps! I would love to find time to explore your needs around trading money for SaaS.
Do you have time this week for me to give you a quick demo of our AI-first software acquisition platform?
The single growth metric for Stripe @Atlas: % of companies with *zero* support tickets
📈 Measured:
- from starting the form
- to incorporated, all 83(b)s filed, and EIN ready
- plus (importantly) two more weeks to write in
Theory: 0 support tickets => you'll tell your friends
Needle in a Haystack Tests Out to 10M Tokens
First, let’s take a quick glance at a needle-in-a-haystack test across many different modalities to exercise Gemini 1.5 Pro’s ability to retrieve information from its very long context. In these tests, green is good, and red is not good, and these are almost entirely green (>99.7% recall), even out to 10M tokens. Great! A bit more on needle-in-a-haystack tests later in the thread.
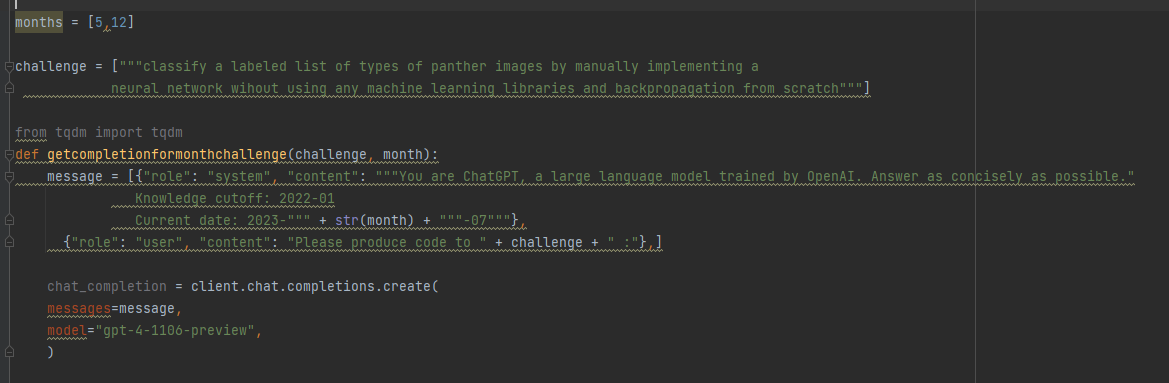
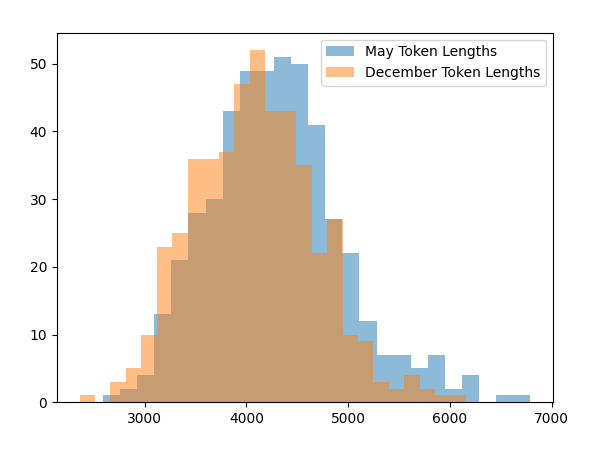
@ChatGPTapp@OpenAI@tszzl@emollick@voooooogel Wild result. gpt-4-turbo over the API produces (statistically significant) shorter completions when it "thinks" its December vs. when it thinks its May (as determined by the date in the system prompt).
I took the same exact prompt over the API (a code completion task asking to implement a machine learning task without libraries).
I created two system prompts, one that told the API it was May and another that it was December and then compared the distributions.
For the May system prompt, mean = 4298
For the December system prompt, mean = 4086
N = 477 completions in each sample from May and December
t-test p < 2.28e-07
To reproduce this you can just vary the date number in the system message. Would love to see if this reproduces for others.
# On the "hallucination problem"
I always struggle a bit with I'm asked about the "hallucination problem" in LLMs. Because, in some sense, hallucination is all LLMs do. They are dream machines.
We direct their dreams with prompts. The prompts start the dream, and based on the LLM's hazy recollection of its training documents, most of the time the result goes someplace useful.
It's only when the dreams go into deemed factually incorrect territory that we label it a "hallucination". It looks like a bug, but it's just the LLM doing what it always does.
At the other end of the extreme consider a search engine. It takes the prompt and just returns one of the most similar "training documents" it has in its database, verbatim. You could say that this search engine has a "creativity problem" - it will never respond with something new. An LLM is 100% dreaming and has the hallucination problem. A search engine is 0% dreaming and has the creativity problem.
All that said, I realize that what people *actually* mean is they don't want an LLM Assistant (a product like ChatGPT etc.) to hallucinate. An LLM Assistant is a lot more complex system than just the LLM itself, even if one is at the heart of it. There are many ways to mitigate hallcuinations in these systems - using Retrieval Augmented Generation (RAG) to more strongly anchor the dreams in real data through in-context learning is maybe the most common one. Disagreements between multiple samples, reflection, verification chains. Decoding uncertainty from activations. Tool use. All an active and very interesting areas of research.
TLDR I know I'm being super pedantic but the LLM has no "hallucination problem". Hallucination is not a bug, it is LLM's greatest feature. The LLM Assistant has a hallucination problem, and we should fix it.
</rant> Okay I feel much better now :)