Your ability to burn fat is not determined by willpower.
The limiting factor is your mitochondria. The study found that individuals with greater mitochondrial abundance achieved significantly higher peak fat oxidation, independent of aerobic fitness. Fat metabolism is not a motivation problem. It is a cellular infrastructure problem.
The biology of performance begins long before the workout starts.
Congrats to Longzhou @xlzhope on this exciting new work: "Long-range white-matter pathways enable efficient spontaneous neural activity propagation in the human brain", now out in J. Neurosci. @SfNJournals: https://t.co/AIqUxLwmDH
New article in @PNASNews:
We all know that ChatGPT loves to delve, bolster, leverage, encompass, showcase, underscore, et cetera. I analyzed full text of 7.3 million journal articles published 2020-2025, hunting for 228 words that spiked after ChatGPT launched in late 2022.
Minogue & Zouridakis et al. studied the brains of people with dementia and FTLD-PSP or FTLD-CBD. They found that PSP and CBD show distinct patterns of selective vulnerability, with tau pathology predominantly affecting glia in PSP and neurons in CBD. https://t.co/WGAU3ZH4ae
Don't miss our work presented at #ICRA2026 in Vienna 🇦🇹
📅 June 4, 12:00-12:10, Hall A2
"Congestion Mitigation Path Planning for Large-Scale Multi-Agent Navigation in Dense Environments" (RA-L)
T Kato, KO, Y Sasaki & N Yokomachi
https://t.co/21LGz17UJ8
Over at @Neuro_Skeptic, there's details of a "fun" new paper that looks at the changing landscape of #neuroimaging research. Check it out here: https://t.co/0iKVkL48uD #neuroscience
New paper in Imaging Neuroscience by SungJun Cho, Mark W. Woolrich, et al:
Modelling discrete states and long-term dynamics in functional brain networks
https://t.co/Fzoeh6xfDW
"La codificación predictiva plantea el autismo y la esquizofrenia como desequilibrios entre el procesamiento descendente (top-down) y ascendente (bottom-up).
El autismo podría favorecer la entrada sensorial ascendente, lo que llevaría a una mayor atención a los detalles y a sobrecarga sensorial.
La esquizofrenia podría favorecer las creencias descendentes, lo que conduciría a alucinaciones y delirios"
*Otra vez, predictive coding en acción!
The mclust R package is a widely used tool for model-based clustering, classification, and density estimation. It fits Gaussian finite mixture models and can automatically select the best model and number of clusters using the Bayesian Information Criterion (BIC). It also supports hierarchical model-based clustering and provides tools for classification of new observations.
✔️ Reveals patterns in complex data sets
✔️ Produces probabilistic cluster assignments for improved interpretation
✔️ Provides uncertainty measures to assess classification reliability
✔️ Offers rich visualization options for exploring clustering structure
The visualizations below are from the mclust package website and show example plots generated with mclust. For more details, visit the package website: https://t.co/N5hWmFcV26
Want more practical tips and examples on Statistics, Data Science, R, and Python? Subscribe to my email newsletter for exclusive insights.
For more information, visit this link: https://t.co/ktUcWo9XpO
#Rpackage #database #RStats #R #DataViz #statisticians #DataVisualization
New paper in Imaging Neuroscience by Aliza Brzezinski-Rittner, Mahsa Dadar, et al:
Intracranial volume: To adjust or not to adjust? It is not a matter of if, but how
https://t.co/Mu16rL103i
Everyone is fine-tuning LLMs.
Almost nobody understands what is actually being updated inside the model.
Here are 5 techniques that change how you think about model adaptation, and what each one is actually doing to the weights:
1./ LoRA - Learn the update, not the weights
The pretrained weight W is frozen. Completely untouched.
Instead of updating W directly, two small matrices are trained =>
A ∈ ℝʳˣᵈ and B ∈ ℝᵈˣʳ, where r ≪ d
The weight update is: ΔW = BA Effective weight: W' = W + BA
The entire adaptation happens in a tiny low-rank space. W never changes.
2./ LoRA-FA - What if we freeze even more?
Same structure as LoRA. One change.
A is frozen alongside W. Only B is trained. Effective weight: W' = W + BA (A is fixed)
Half the trainable matrices of LoRA. Same core idea. Fewer parameters.
3./ VeRA - What if the matrices don't need to be learned at all?
This is where it gets interesting.
A and B are both frozen, and randomly initialized. What gets trained are just two tiny scaling vectors =>
b ∈ ℝʳ and d ∈ ℝʳ
Instead of learning the low-rank matrices themselves, VeRA keeps them frozen and learns small scaling vectors that modulate their contribution.
Initialization => b = 0, d = 1
You're not learning matrices. You're learning how to scale them.
One of the most parameter-efficient techniques on this list.
4./ Delta-LoRA - What if W itself learns from the low-rank updates?
This one is fundamentally different.
Unlike standard LoRA, the base weight W is not fully frozen. It is updated through low-rank delta propagation at every step =>
W^(t+1) = W^t + c(B_(t+1)A_(t+1) − B_t A_t)
Where c is a scaling factor.
A and B are trainable. W evolves, but guided entirely by low-rank changes.
5./ LoRA+ - Same structure. Smarter learning rates.
Identical to LoRA, freeze W, train A and B.
One change => B is assigned a larger learning rate than A. η_B > η_A
A ← A − η_A · ∂J/∂A B ← B − η_B · ∂J/∂B
A small optimization change that can make LoRA training more effective.
The core idea running through all five:
You do not always need full fine-tuning to adapt a model.
LoRA updates two matrices.
LoRA-FA updates one.
LoRA+ updates two at different speeds.
Delta-LoRA lets W evolve - guided by low-rank deltas. VeRA updates two vectors.
Same goal. Five different answers to the same question:
=> What is the minimum we actually need to learn?
That is the core idea behind parameter-efficient fine-tuning.
And now you know what is actually happening inside the model.
In this study, Martins and colleagues provide an integrated characterization of the human brain histaminergic system, using transcriptomic and neuroimaging datasets to describe the molecular organization of this system and its relevance to #mentalhealth.
https://t.co/QSwtwvrXU0
New paper in Imaging Neuroscience by Dalin Yang, Adam T. Eggebrecht, et al:
Mapping brain function underlying naturalistic motor observation and imitation using high-density diffuse optical tomography
https://t.co/A7EhDVsDCW
Benchmarking methods for mapping functional connectivity in the brain | https://t.co/N2XmnTJXsA
What is the best FC metric?
led by @liuzhenqi0303 in @naturemethods ⤵️
Mapping cerebral blood perfusion and its links to multi-scale brain organization across the human lifespan | https://t.co/pjI36Z7wLi
How does blood perfusion map onto canonical features of brain structure and function? @AsaFarahani investigates @PLOSBiology ⤵️
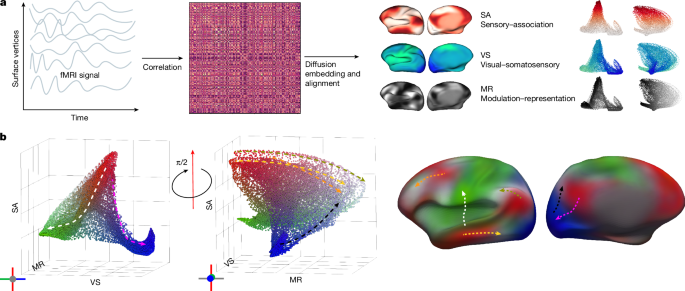
A new atlas reveals that functional connectivity patterns in the human neocortex shift dramatically from birth through old age, organizing brain regions along three dominant axes: sensory-to-association, visual-to-somatosensory, and modulation-to-representation.
https://t.co/A4XyHA9Jpv






![ClinicalNeuroph's tweet photo. [Aging] Akbaş et al.: "The brain-heart interconnection may alter through aging and cognitive impairment." https://t.co/QAeHQsn6pq https://t.co/cHyUahQVRL](https://pbs.twimg.com/media/HJpZKpBW0AILhx9.jpg)
![ClinicalNeuroph's tweet photo. [Aging] Akbaş et al.: "The brain-heart interconnection may alter through aging and cognitive impairment." https://t.co/QAeHQsn6pq https://t.co/cHyUahQVRL](https://pbs.twimg.com/media/HJpZClqW4AAFMqH.jpg)


















![ClinicalNeuroph's tweet photo. [Aging] Akbaş et al.: "The brain-heart interconnection may alter through aging and cognitive impairment." https://t.co/QAeHQsn6pq https://t.co/cHyUahQVRL](https://pbs.twimg.com/media/HJpZNIlXMAQqEhW.jpg)