Meet DiffusionGemma ⚡ Our latest experimental open model (Apache 2.0) that generates text up to 4x faster.
Instead of predicting and typing just one word at a time like most language models, it drafts and refines entire blocks of text simultaneously.
Here’s how it works 🧵 ↓
رحلة الإعداد مستمرة 🇸🇦..
انطلاق المرحلة الثانية من التدريب المكثف في @KAUST_NewsAR لإعداد 183 طالبًا وطالبة لمنافسات 2026 العلمية العالمية.
#عقول_تمثل_الوطن#موهبة
اطلقنا خدمة التحويل من صوت لنص او مايعرف بالSpeech-To-Text (STT)!
بقيادة المشروع: @Magdi__Waleed وثم @LatentDev_
نموذجنا حقق دقة وسرعة تنافس اغلب منتجات السوق في مجال التحويل من صوت لنص، ودقة تتخطى بمراحل نموذج Deepgram وWhisper في اللغة العربية وبالذات اللهجات السعودية 🇸🇦🫡
متحمس أقدّم لكم مشروعي Deepbox 😁
أكبر وأشمل إطار عمل TypeScript لعلم البيانات والذكاء الاصطناعي!
بديل قوي ومتكامل لـ NumPy, Pandas, PyTorch, scikit-learn
- 13 وحدة متكاملة
- أكثر من 90 عملية tensor مع دعم broadcasting
- Type-safety كامل
- Zero dependencies
- 4,344 اختبار
https://t.co/2zD0Vsov2Z
لأي شخص مهتم أو شغوف بمجال ال AI، لا تضيع هذه الفرصة، أعظم برنامج ذكاء اصطناعي على مستوى المملكة، حتى لو ما تخطيت كل المراحل، بتستفيد من كل مرحلة في البرنامج.
إطلاق النسخة الرابعة من برنامج الذكاء الاصطناعي والنسخة الثالثة من برنامج المعلوماتية الحيوية!
اكتسب قدرات متقدمة تشكل مستقبل الابتكار في المملكة العربية السعودية. 🇸🇦💚
بالشراكة مع @McitGovSa و #JARIR_Investment و #RZM_Investment، تجمع هذه البرامج بين التميز الأكاديمي والتدريب العملي لإعدادك في أسرع القطاعات نمواً في المملكة.
هل أنت مستعد لتطوير خبرتك وصناعة المستقبل؟
تقدم الآن
https://t.co/tu8Z4qHOT9
#KAUST_Academy #KAUST #SaudiTalent #SaudiVision2030 #AI #Bioinformatics
بدأنا في الاكاديمية بإعداد مقاطع رياضية قصيرة رغبة مننا في تقديم محتوى قد يساعد الطلاب على حب الرياضيات
هذه البداية ونرحب بأي اقتراح يساعد في تحسين جودة المقاطع
🎓 يسرنا الإعلان عن أفضل 3 مشاريع لطلاب صيف 2025 في برامج التخصصات!
من أكثر من 16,000 طالب، تم اختيار 297 طالباً متميزاً، ومن 137 مشروعاً تم اختيار أفضل 3 مشاريع في كل مسار! 🌟
تم تقييم المشاريع من قبل أعضاء هيئة التدريس والباحثين في جامعة الملك عبدالله 🏆
سنستعرض في هذا الثريد المشاريع المتميزة من:
🤖 الذكاء الاصطناعي
🧬 المعلوماتية الحيوية
⚡ الطاقة المتجددة
🔐 الأمن السيبراني
تابعوا معنا لاكتشاف الابتكارات المذهلة! 👇
#KAUST #KAUST_Academy
لعل هذه الورقة البحثية الجديدة من شركة DeepSeek واحدة من أكثر الأشياء اللي مرت علي اليوم في التايم لاين، وعشان نفهم ليه هذه الورقة مهمة، لازم نرجع خطوة للوراء ونشوف المشكلة الأساسية اللي تحاول تحلها.
إحدى أكبر التحديات اللي تواجه النماذج اللغوية الكبيرة (LLMs) اليوم هي التعامل مع السياقات الطويلة، يعني المستندات والكتب والمحادثات اللي تمتد لآلاف الكلمات. المشكلة حسابية بحتة؛ تكلفة المعالجة والذاكرة في هذه النماذج ما تزيد بشكل خطي مع زيادة عدد الكلمات، لكن تزيد بشكل أُسي (quadratic scaling).
يعني لو عندك نص من 1000 كلمة، و النموذج يحتاج قوة معالجة معينة خلنا نقول (X). لو صار النص 2000 كلمة، القوة المطلوبة ما راح تتضاعف وبس، بل ممكن تزيد أربع مرات أو أكثر. هذا يخلي معالجة ملايين الكلمات أمر مكلف جداً وغير عملي.
هنا جاءت الفكرة العبقرية اللي طرحتها DeepSeek واللي يسمونها "الضغط البصري للسياق" (Contexts Optical Compression). بدل ما نتعامل مع النص كسلسلة طويلة من "التوكنات النصية"، ليه ما نحوله لصورة ونخلي النموذج "يشوف" النص بدل ما "يقرأه"؟
الفكرة قريبة من المقولة الشهيرة "صورة واحدة تساوي ألف كلمة"، بس هم طبقوها حرفياً. اكتشفوا إنهم يقدرون يضغطون نص مكون من 1000 توكن نصي في صورة ما تاخذ إلا 100 "توكن بصري"، وبدقة استرجاع للنص توصل إلى 97%.
هذا يعني نسبة ضغط توصل 10 أضعاف مع الحفاظ على دقة شبه كاملة. والأكثر من كذا، حتى عند نسبة ضغط 20 ضعف (يعني 50 توكن بصري مقابل 1000 توكن نصي)، استطاع النموذج يحافظ على دقة تصل إلى 60%.
السر وراء هذه القدرة تحديداً في المكون اللي سموه DeepEncoder. معظم المشفرات البصرية (vision encoders) الحالية إما إنها تنتج عدد كبير جداً من التوكنات البصرية، أو إنها تحتاج ذاكرة ضخمة، أو ما تقدر تتعامل مع الصور عالية الدقة بكفاءة.
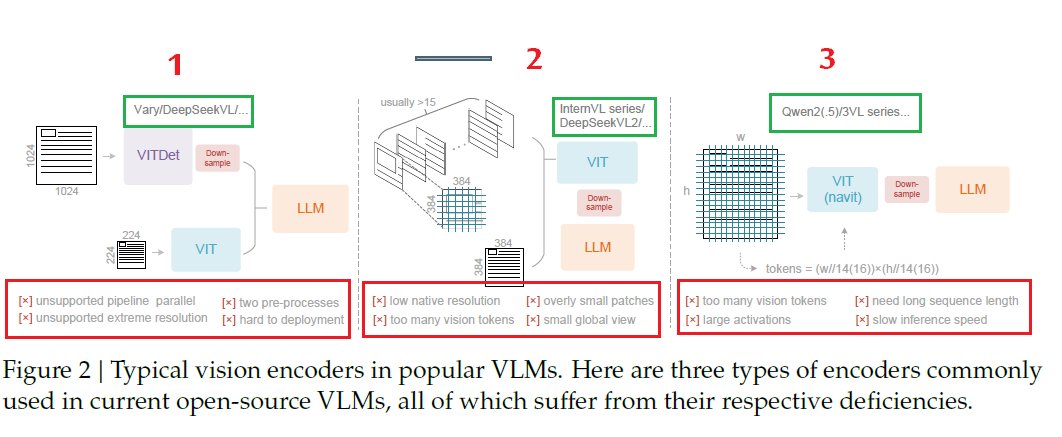
هذه الصورة تعرض لنا أشهر ثلاث طرق تستخدمها النماذج البصرية اللغوية (VLMs) عشان تحول الصور لـ "توكنات" تفهمها. المشكلة اللي توضحها الصورة هي إن كل طريقة لها عيوبها
الطريقة الأولى (مثل Vary) معقدة وتحتاج معالجة مزدوجة للصورة، وهذا شيء صعب تطبيقه. الطريقة الثانية (مثل InternVL) تقصقص الصورة الكبيرة لقطع صغيرة مرة، وهذا يخليها تفقد السياق العام والرؤية الشاملة.
أما الطريقة الثالثة (مثل Qwen2) فتستهلك ذاكرة ضخمة وممكن تسبب انهيار النظام مع الصور الكبيرة. الخلاصة اللي تبي توصلها الصورة هي إن كل الحلول الموجودة كانت فيها عيوب، إما إنها تنتج توكنات كثيرة، أو إنها بطيئة، أو ما تدعم الصور عالية الدقة. وهذا بالضبط اللي فتح الباب لابتكارهم الجديد.
هنا جاء الابتكار في DeepSeek، صمموا مشفر يشتغل على مرحلتين. المرحلة الأولى تستخدم نسخة مخففة من نموذج SAM (Segment Anything Model) بحجم 80 مليون باراميتر، وظيفته إنه يركز على التفاصيل الدقيقة في الصورة ويستوعبها بدقة عالية.
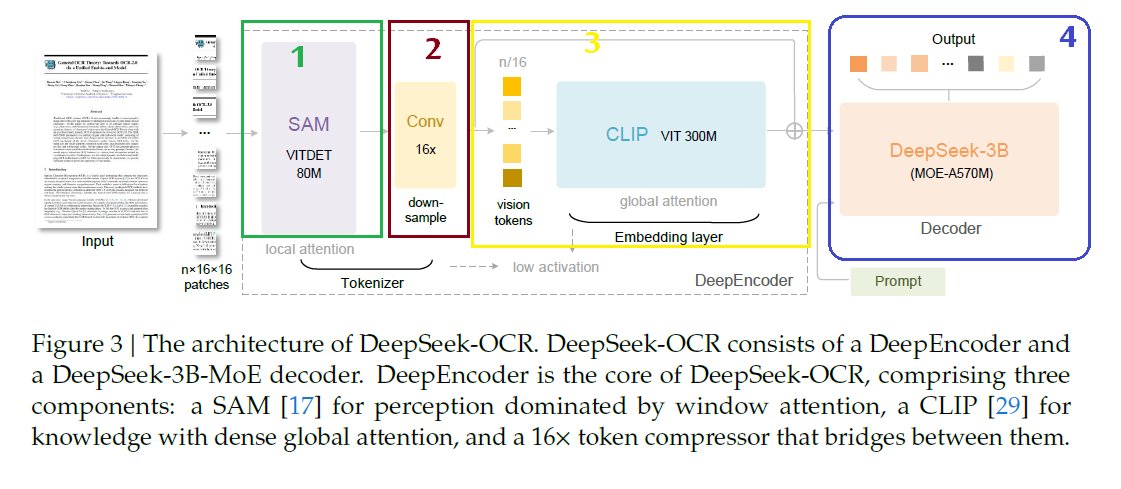
هذه الصورة اللي تشرح لنا الحل الهندسي الذكي اللي ابتكروه. هذه هي البنية الهندسية لنموذج DeepSeek-OCR، وتوضح لنا كيف يشتغل من الداخل. الجزء الأهم هو اللي على اليسار واسمه DeepEncoder.
الفكرة ببساطة إنه ما يعتمد على طريقة وحدة، بل يدمج ثلاث مراحل ذكية. أول شيء، يستخدم نموذج اسمه SAM عشان يركز على التفاصيل الدقيقة والنصوص الصغيرة في الصورة (local attention).
بعدين، بدل ما يرسل كل هذي التفاصيل الضخمة، يستخدم طبقة ضغط (Conv) تقلص حجم البيانات 16 مرة، وهذا هو سر توفير الذاكرة والكفاءة.
آخر خطوة هي إنه يمرر هذه البيانات المضغوطة على نموذج اسمه CLIP اللي مهمته يفهم الصورة بشكل عام ويربط الأجزاء ببعضها (global attention).
المخرجات النهائية من هذا المشفر الذكي هي "توكنات بصرية" قليلة جدًا، تروح للـ Decoder (الجزء اللي على اليمين) عشان يترجمها للنص المطلوب. باختصار، هذي الصورة هي المخطط الهندسي للآلة اللي صنعوها عشان يحلون المشاكل اللي شفناها في الصورة الأولى.
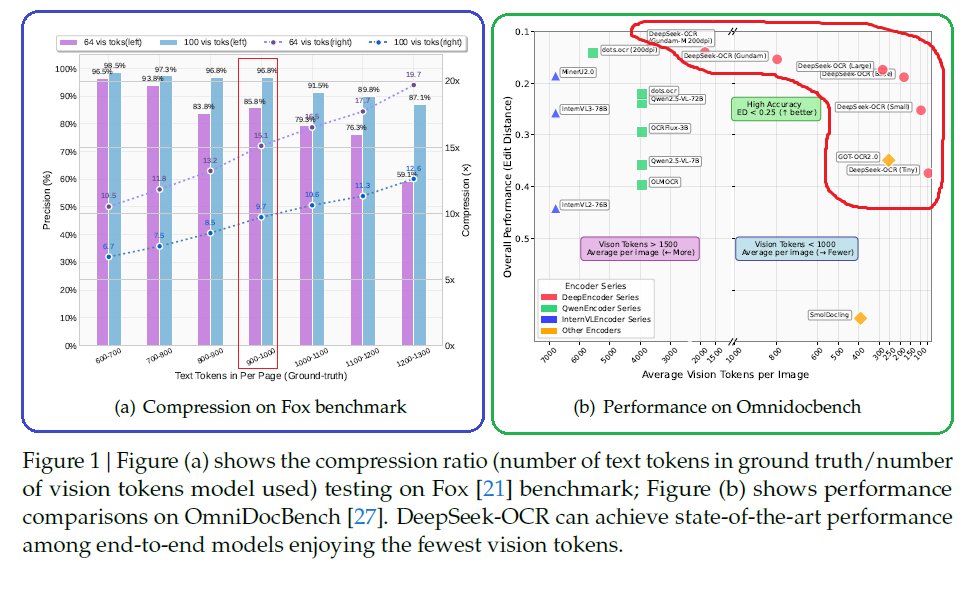
أما هذي الصورة، فهي اللي فيها الزبدة كلها، وتعطينا الدليل بالأرقام على إن فكرتهم نجحت بشكل باهر. الصورة مقسومة لجزأين. الرسم البياني اللي على اليسار (a) يجاوب على سؤال: إلى أي مدى نقدر نضغط النص داخل الصورة بدون ما نخسر الدقة؟
الخطوط الزرقاء والبنفسجية توضح دقة التعرف على النصوص، ونلاحظ إنه حتى عند نسبة ضغط توصل 10 أضعاف (يعني 1000 كلمة تصير 100 توكن بصري)، الدقة حوالي 97%. وهذا شيء ممتاز صراحة.
أما الرسم البياني اللي على اليمين (b) فيقارن أداء DeepSeek-OCR مع نماذج ثانية مشهورة. النقطة المهمة هنا هي إنك كل ما كنت فوق وأقرب لليمين، كان أداؤك أفضل وأكثر كفاءة (أخطاء أقل وتوكنات أقل).
نشوف بوضوح إن نماذج DeepSeek-OCR (اللي باللون الأحمر) متجمعة في الزاوية اليمين فوق، يعني تحقق أفضل أداء باستخدام أقل عدد ممكن من التوكنات، بينما المنافسين مثل MinerU2.0 على اليسار يحتاجون آلاف التوكنات عشان يوصلون لنفس مستوى الدقة أو حتى أقل.
الفكرة بصراحة ذكية وجميلة، لو نجحت هالطريقة على نطاق واسع، ممكن تكون المفتاح لنماذج بذاكرة شبه لا نهائية وبتكلفة بسيطة. تخليها تتعامل مع سياقات طويلة. النموذج بيحتفظ بالمحادثات الأخيرة مع المستخدم كنصوص، أما القديمة فتنضغط وتخزن كصور مضغوطة يقدر يرجع لها وقت الحاجة.
رابط الكود + الورقة :
https://t.co/lJt5youGTl
---
- المقصود بالتوكنات (Tokens) - كلمة أو جزء من الكلمة
- المشفر (Encoder) - المشفر هو الجزء من النموذج اللي وظيفته "يفهم" و"يلخص" الكلام .
- فاك التشفير (Decoder) - هو الجزء اللي وظيفته "يتكلم" و"يبني الجواب". يشتغل عكس المشفر تماماً.
يسرنا مشاركة الكتيب السنوي الثالث لبرامج التخصصات في أكاديمية كاوست! 🇸🇦
هذا العام، تم إنجاز أكثر من 130 مشروعاً بمشاركة 290+ طالب وطالبة. نفخر بمشاركة أعمالهم المميزة مع العالم ونتطلع بشغف لتمكين الدفعة القادمة لعام 2026!
📖 اطلع على الكتيب:
https://t.co/g1IonQRHng
بالشراكة مع:
#Jarir_Investment
@kacaresaudi@site_saudi@NCA_KSA
#KAUST_Academy #SaudiTalent #KAUST
ملاحظة: الكتيبان الأول والثاني متوفران أيضاً في الرابط لمن يهمه الأمر 😉
باختصار هذا الإنجاز، يوضح لنا الإمكانية الكبيرة للنماذج اللغوية الضخمة على ابتكار واكتشاف حلول، جديدة إذا تم تدريبها على بيانات علمية معقدة بالإضافة إلى اللغة الطبيعية.
لكن ليه هذه الطريقة تنفع؟
لأن هذه الطريقة كأنها حلقة الوصل ما بين اللغة الطبيعية ولغة الخلايا المعقدة.