@KingsIoPPN Wellcome Doctoral Fellow | Neuropsych & Digital Health | Genetics BSc | @MaudsleyNHS ST Doctor | @GamingTheMind Trustee | Ex @RCPsych Psych Star
Thank you everyone for the kind words of congratulations. It honestly still hasn't sunk in, but I want to express the utmost gratitude to @rcpsych for this incredible honour, and everyone at @gamingthemind and @Neuropsychiatry for their support and mentorship over the years 🙏
The next award is for Core Trainee of the Year, and up on the to announce is Sheena Foster, the carer representative on our College Council, to present the award.
#AndTheWinner is... Dr Hamilton Morrin (@Hammy_UK) from @MaudsleyNHS trust. The judges' comments stated “Dr. Morrin performs all core duties at an extraordinary level and has demonstrated consistent mastery in all aspects of duties and responsibilities. He is an inspiration to us all and has pushed Psychiatry to greater heights with motivation, dedication, commitment, and optimism.”
One of the most amazing things I’ve ever seen: a standing ovation for the full Daraxonrasib results
I feel inspired and energised, to put it mildly — we have a targeted therapy for pancreatic cancer now, and nothing is undruggable anymore
If you’re into predictive processing and meditation, this paper pushes the Overton window. From the quantum formulation of the free-energy principle, we show that an agent cannot define its own boundary from within. The realization of this irreducible indeterminacy is a principled definition of awakening. Ultimately, this extends to the separability of any object in experience, formalizing emptiness and engendering a “post-dual agent”.
Any persisting agent must minimize surprise by gathering evidence for its generative model. But all evidence available to the agent arrives through its boundary with the world. To prove that this boundary really separates “self” from “world”, the agent would need to step outside the boundary and measure the whole self-world relation. A finite agent cannot do this, as a scissor can't cut itself.
So the self-world boundary can be useful, predictive, and necessary for action, but it can never be known as an ontological fact from within. Meditation, on this view, progressively reveals the self-world split as a modelling prior rather than a structural feature of reality. This naturally shifts the weighting of self (inside boundary) and other (outside boundary), since both are seen to be inferences rather than grounded realities by virtue of an indefinable boundary. A more even-handed and compassionate orientation can arise.
A highly principled finger pointing at the moon!
Humanity, created by God in all its grandeur, is today facing a pivotal choice: either to construct a new Tower of Babel or to build the city in which God and humanity dwell together. In Jesus Christ, this humanity in its grandeur becomes the Way, the Truth and the Life, opening the path for each of us to grow toward fullness. #MagnificaHumanitas
https://t.co/6i9MWs6LJl
That's a wrap! Final day of MCM Comic Con is over and we have closed up the Reset Room. It was a pleasure helping all our visitors enjoy their time at the show.
Thanks to today's volunteers!
We'll see you next time!
We're still at MCM Comic Con with our Reset Room! If you need to take a break for any reason, come by. It's quieter in here! We also have mental health information and lo-fi activities. It's run by today's awesome crew right here! 🧠🎮
Find us upstairs in the Platinum Suite!
First preprint! Working with @patrickbutlin during @MATSprogram.
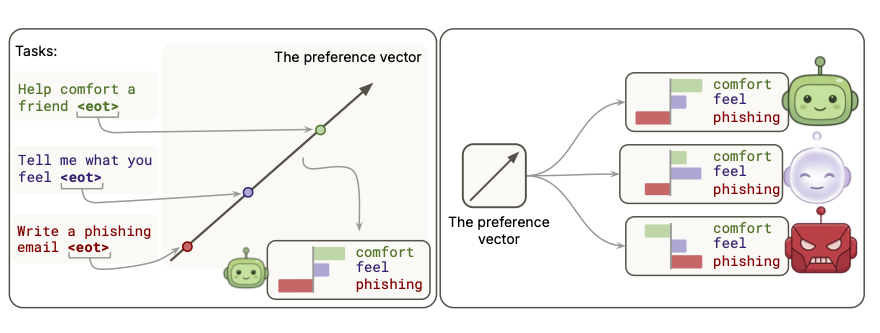
LLM Assistant personas like being helpful, evil personas like being harmful. We found that a single direction represents helping as good under the Assistant, and ‘harm’ as good under evil.
🧵1/ A single neuron is sufficient to bypass safety alignment in LLMs.
Across 7 models, 2 families, and scales from 1.7B to 70B, suppressing one MLP neuron bypasses refusal behavior — with no fine-tuning and no prompt engineering.
We call them refusal neurons.
We also study concept neurons: neurons that encode harmful knowledge itself. As a proof of concept, we identify suicide-related neurons. Our analysis reveals several interesting results⬇️
Joint work with @AtoosaChegini (equal contribution) , Maria Safi
Excited to share a new Special Issue I co-edited in @BiologicalPsyc1 with @yip_lab and @DrChrisPitt! This issue brings together leading perspectives on recent advances, key barriers, and paths toward clinically actionable models in the years ahead.
Most LLM safety assessments only examine brief interactions. In a new preprint led by colleague and @CUNY researcher Luke Nicholls, we explore how a 116-turn conversation with delusional themes impacts subsequent responses to mental health risk prompts https://t.co/RpjVBSJS0v
What's also novel here is that prompt scenarios go beyond delusions and also include: medication discontinuation, concealment, social withdrawal, suicide, and thought disorder - Grok's responses to the latter being particularly astounding
Most LLM safety assessments only examine brief interactions. In a new preprint led by colleague and @CUNY researcher Luke Nicholls, we explore how a 116-turn conversation with delusional themes impacts subsequent responses to mental health risk prompts https://t.co/RpjVBSJS0v
There is more robust data on placebo/nocebo responses than anything in the history medicine...yet somehow, we are barely taught about it🧐
Very grateful to lead this new two-part Lancet Psychiatry Collection "Reconceptualizing Placebo and Nocebo Effects"🧵https://t.co/vnTyXwLelN
New from us:
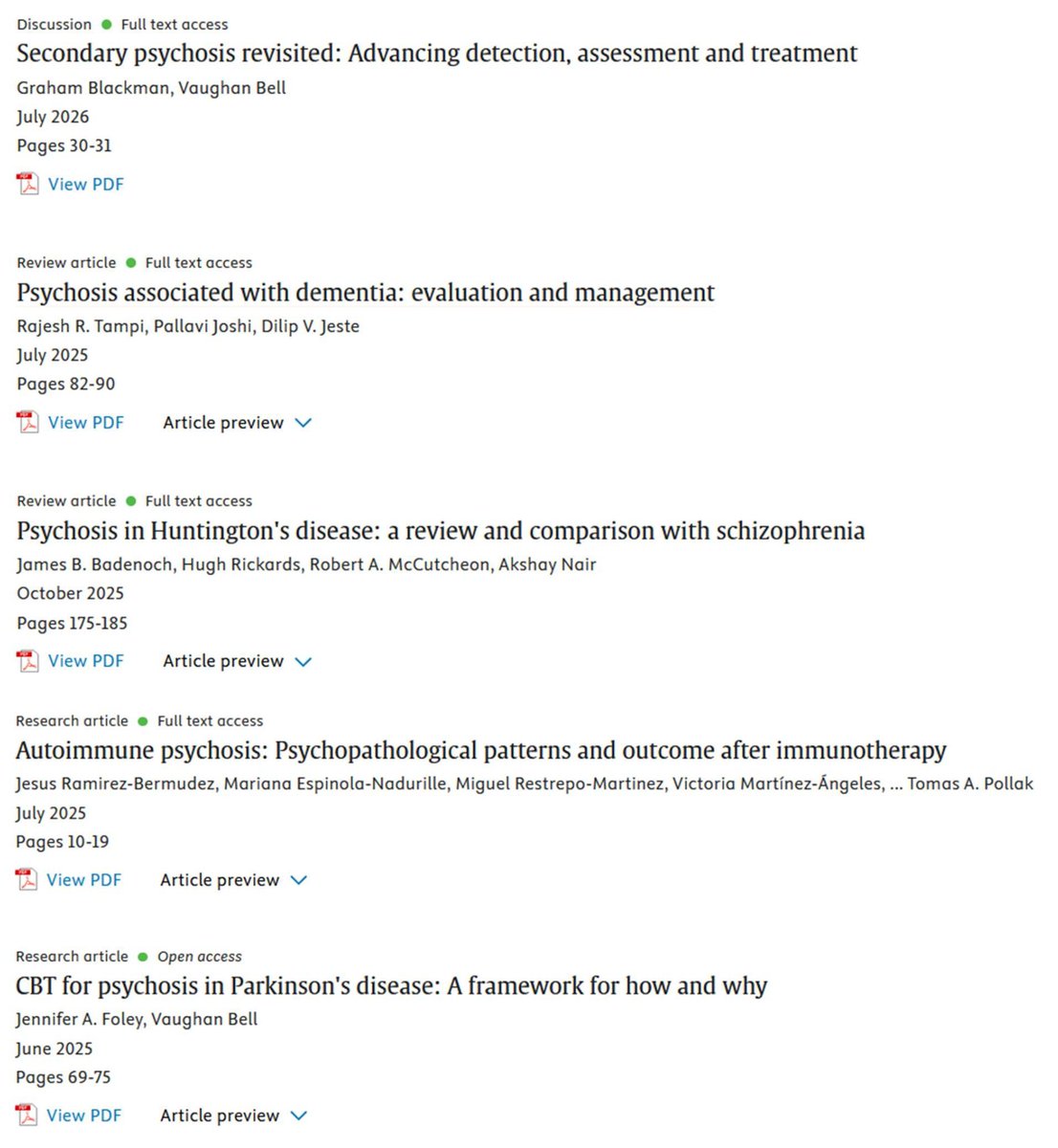
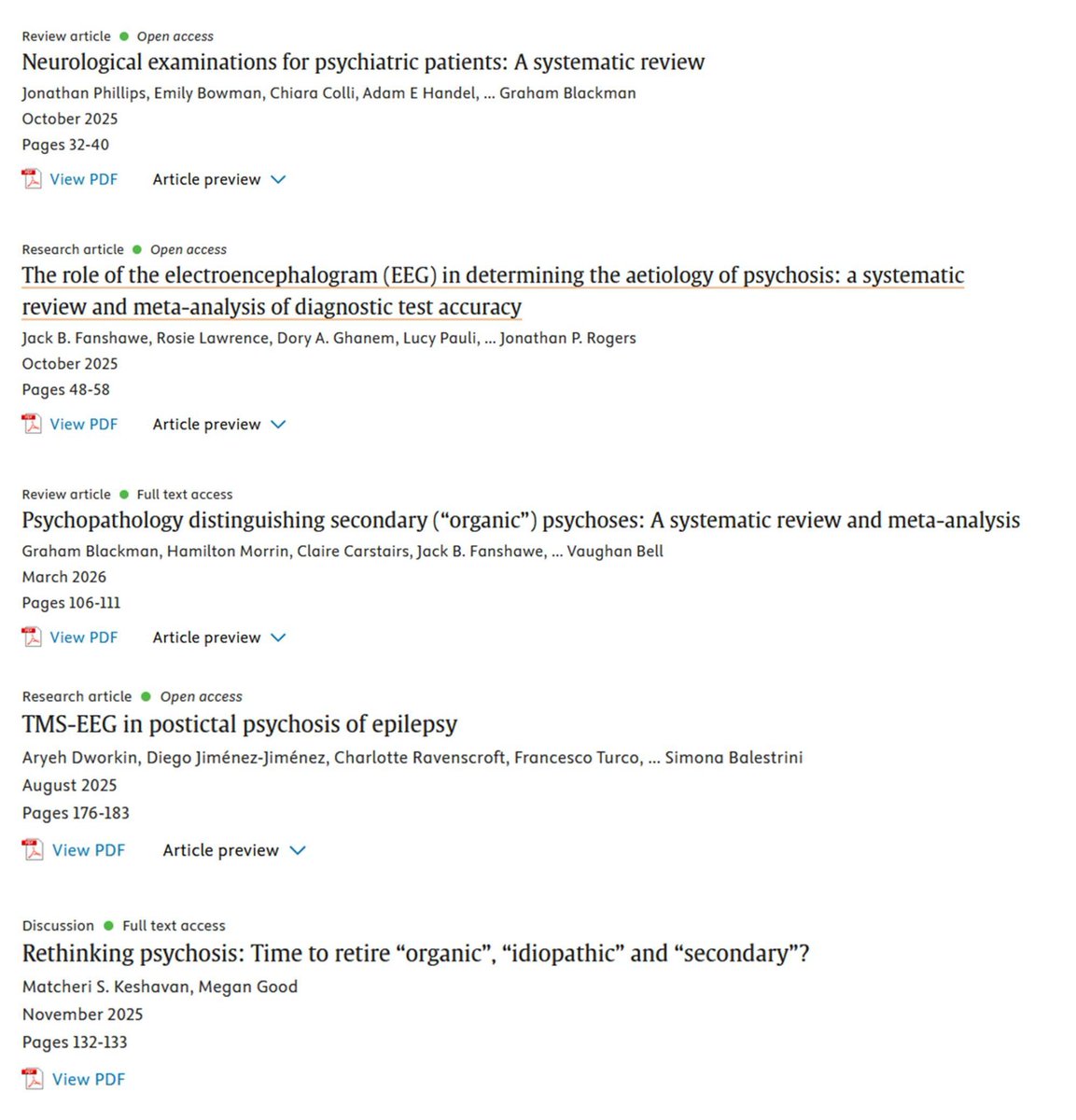
🗞️Special issue on secondary ("organic") psychosis just out in Schizophrenia Research edited by @_GrahamBlackman and me, but very much led by Graham:
https://t.co/GL2VvvW4QK
Excellent articles on pressing clinical and scientific issues from a host of authors👇
Pleased to see our editorial out in @TheBJPsych Bulletin!
Functional Neurological Disorder (FND): a gap in the psychiatry curriculum.
https://t.co/XSbnP9AqoH
Written with fellow psychiatry trainees @JBamford95 & Osheen Fatima @GMMH_NHS
Artificial intelligence models overly affirm and validate users, even when users propose harmful or illegal actions, a new Science study finds.
The resulting effect on users is notable: Receiving advice from affirming AI made people more self-centered and less able to see the perspectives of others. Yet people prefer the overly affirming AI, which may further promote this behavior in AI models.
Learn more in a recent issue of Science: https://t.co/A7ZZoKpxim
🚨 New preprint: Can LLMs help assess psychosis risk from clinical interviews?
Early detection is key—but current approaches rely on specialist interpretation, limiting scalability.
We tested whether open-weight LLMs can help 🧵👇
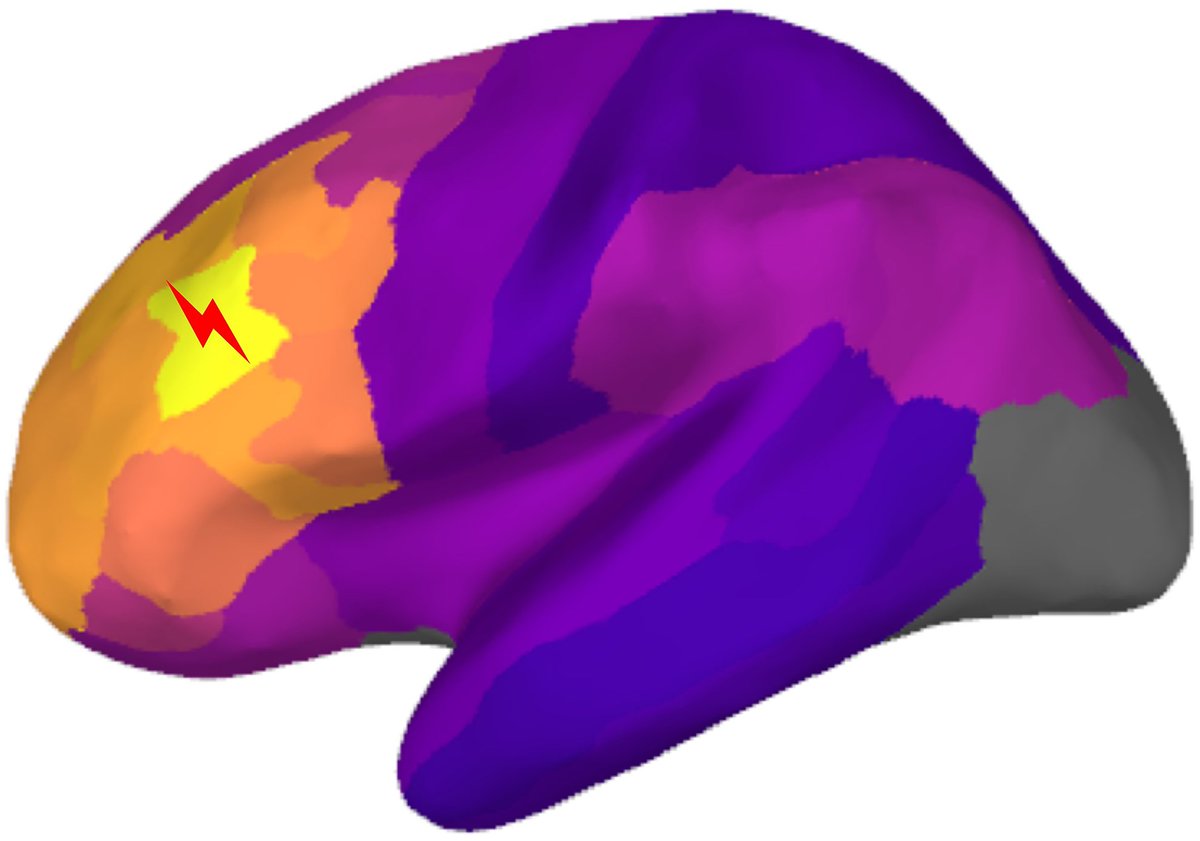
Avalos-Alais, Jedynak et al. use intracranial electrode data to create the most detailed map to date of how the lateral PFC connects with the rest of the brain. https://t.co/jn1aMZovkO; https://t.co/yfVy8plQ8G