I don’t know who needs to hear this but your research is your IP not the vendors IP. You can do whatever you want with that IP. Reporting it, publishing it, selling it to a third party or putting it in a box under your bed 🙄
‼️ After the MSRC blog post about Nightmare-Eclipse, researchers are coming forward with their own MSRC horror stories.
The response from the security community isn't going Microsoft's way. As they’re not backing Microsoft.
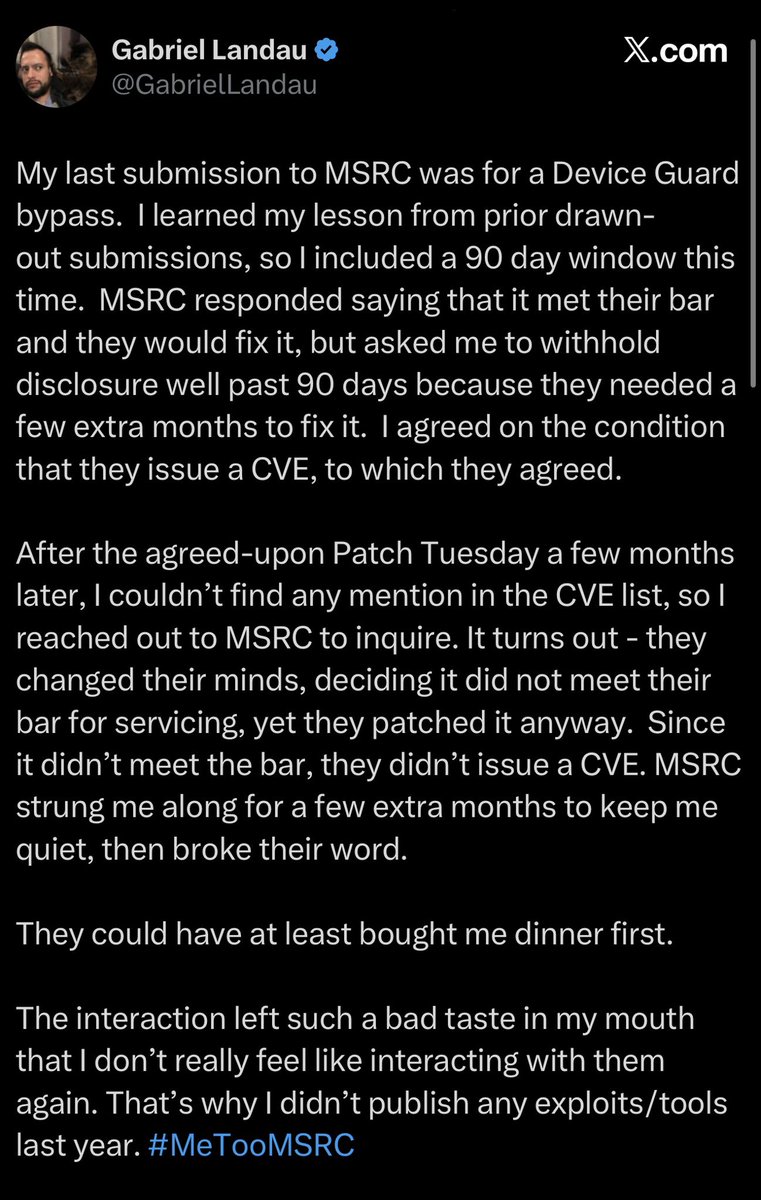
Gabriel Landau, a well-known Windows security researcher, says he reported a Device Guard bypass with a 90-day window. MSRC told him it met their bar and they'd fix it, then asked him to hold disclosure for extra months. He agreed on the condition they issue a CVE. They patched it silently, decided after the fact it "didn't meet the bar," and never issued the CVE. In his words: "MSRC strung me along for a few extra months to keep me quiet, then broke their word."
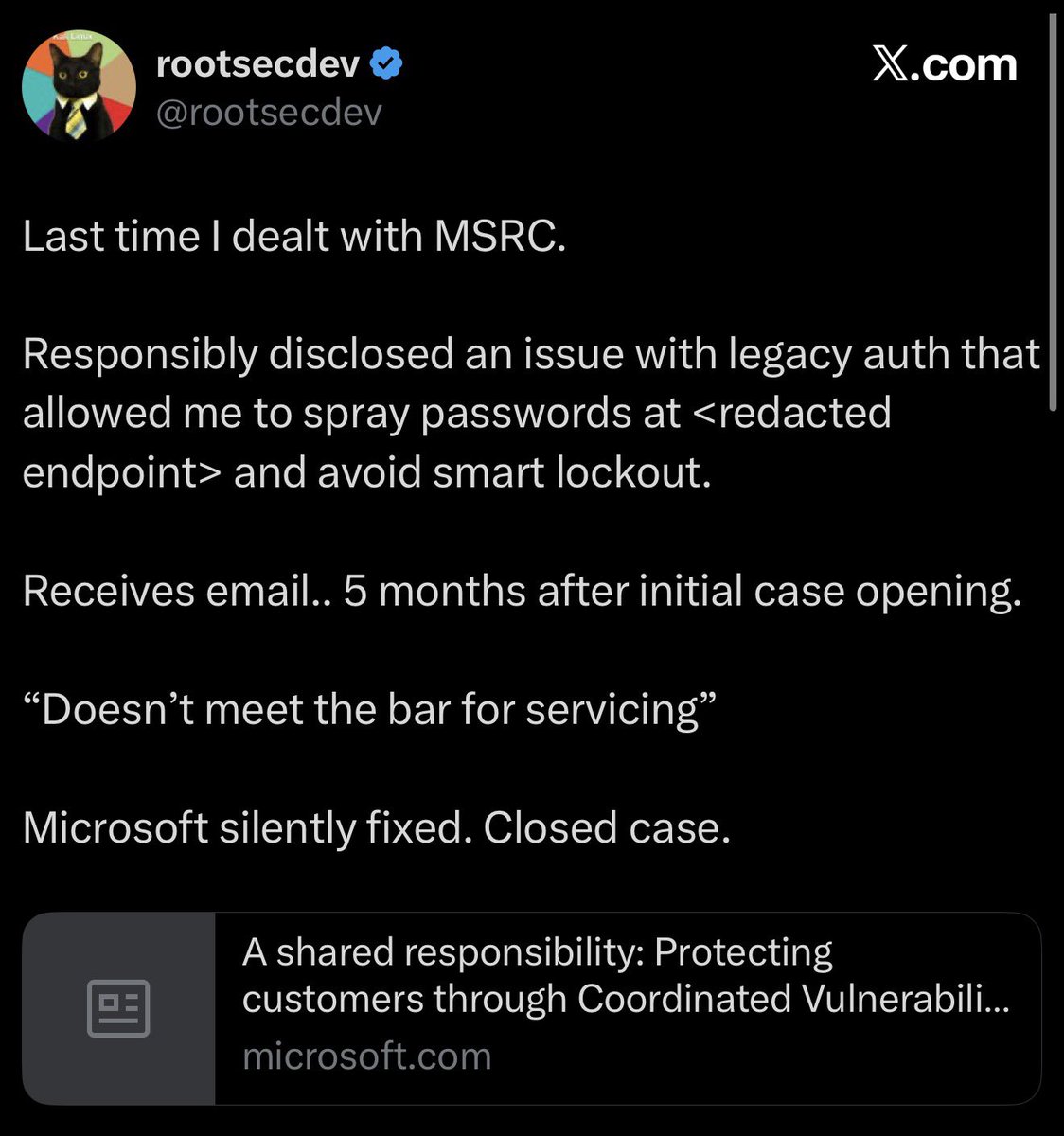
Another researcher, rootsecdev, says he responsibly disclosed a legacy-auth flaw that allowed password spraying while avoiding smart lockout. Five months later, MSRC replied that it "doesn't meet the bar for servicing," silently fixed it, and closed the case.
Microsoft's post was meant to defend their coordinated disclosure policy. Instead it became a thread of researchers explaining why they've stopped trusting their process.
Interesting that they reported the exploits to Microsoft months ago and got told they weren't high priority, eventually after more months of being ghosted or ignored/gaslit they release said exploits which end up being used and Microsoft, who own Github, claim they could be misused and weaponized
To know what Chinese labs are doing you can just read their papers.
To know what American labs are doing you have to wait for @karpathy to do a 1 year internship and then post a GitHub repo with what he learned.
Claude helped me with this bug too but in a different way... Tried to gaslight me saying it wasn’t ~exploitable in practice~ and I got obsessed with proving it wrong 😩
Security researchers become trapped into an identity that they can’t escape, life seems purposeless, reality shifts and they realize they can’t bend like a tree in the wind. It turns out that intelligence isn’t the key to happiness.
For those that know. Chop wood, carry water.
There is a certain side of running a business that these AI hypes are missing.
Always running at capacity leaves no room for really thinking about what is important
Sure the AI is "letting you do more than ever," but those same people stopped dreaming and are always executing.
Feels like a tragedy
hot take: 90% of ai startups paying for api calls could run the same workloads locally on a single 3090 and never notice the difference. you don't need frontier pricing for tasks a 27B model handles fine.
most have never even tested a quantized model on consumer hardware. not every task in your pipeline should be burning credits. audit your workload. you'd be surprised what runs locally.
We're returning to @BlackHatEvents#USA 2026!
Early bird registrations are now open for our #macOS Threat Detection, #Forensics & Incident Response training -one of the rare hands-on macOS #DFIR courses available today.
Now updated with:
⚡ Vibe Threat Hunting
🤖 AI in DFIR concepts
📅 Aug 1–2: https://t.co/ZJy6VY9NiX
📅 Aug 3–4: https://t.co/uwt9XzcN8k
#BHUSA #AI #cybersecurity #training #blackhat #vegas
Closed labs hide model sizes. They can't hide what their models know, and what a model knows is an indicator on how big it is.
Reasoning compresses. Factual knowledge doesn't. So you can size a frontier model from black-box API calls alone, and across releases you can literally watch a single fact arrive in the parameters over time.
For three years, my friends Jiyan He and Zihan Zheng have been asking frontier LLMs the same question: "what do you know about USTC Hackergame?", a CTF contest. May 2024: GPT-4o invented fake titles. Feb 2025: Claude 3.7 Sonnet listed 19 verified 2023 challenges. By April 2026, frontier models recall specific challenges across consecutive years.
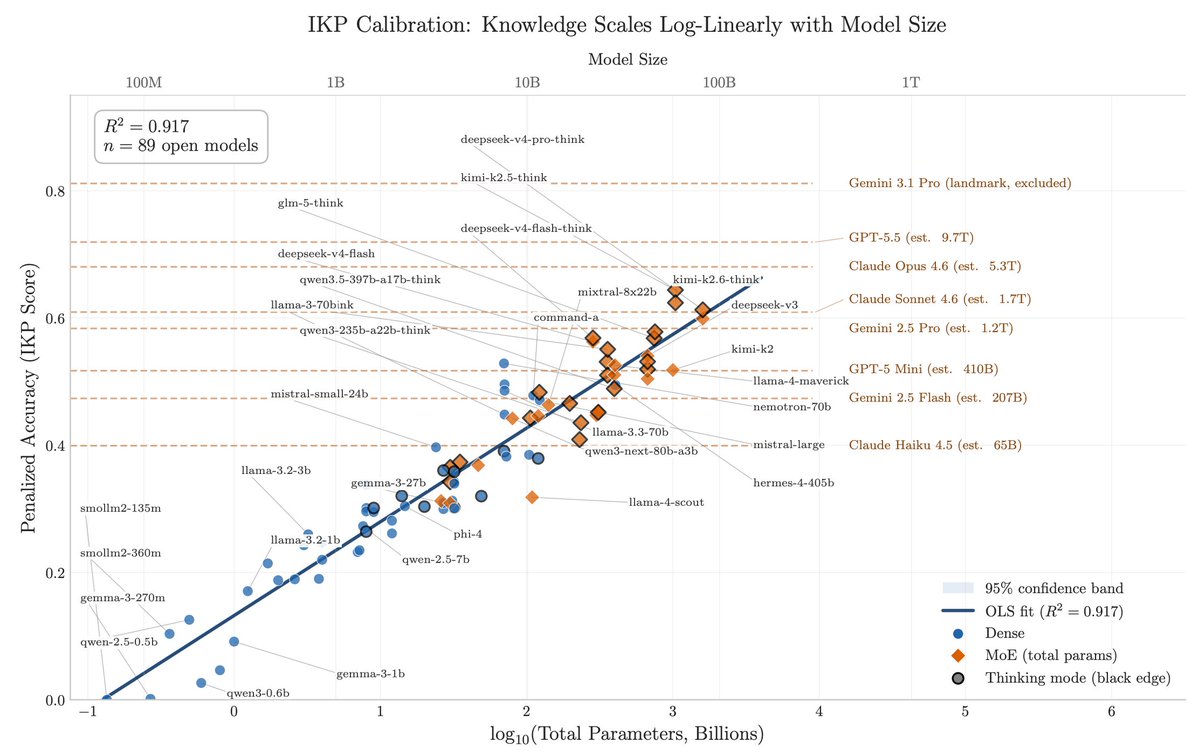
After DeepSeek-V4 dropped, I instructed my agent to spend four days autonomously turning that habit into Incompressible Knowledge Probes (IKP) — 1,400 questions, 7 tiers of obscurity, 188 models, 27 vendors. Three findings:
1/ You can approximately size any black-box LLM from factual accuracy alone. Penalized accuracy is log-linear in log(params), R² = 0.917 on 89 open-weight models from 135M to 1.6T params. Project closed APIs onto the curve → GPT-5.5 ~9T, Claude Opus 4.7 ~4T, GPT-5.4 ~2.2T, Claude Sonnet 4.6 ~1.7T, Gemini 2.5 Pro ~1.2T (90% CI: 0.3-3x size).
2/ Citation count and h-index don't predict whether a frontier model recognizes a researcher. Two researchers with similar citation profiles get very different responses. Models memorize impact — work that shaped a field, not many incremental papers.
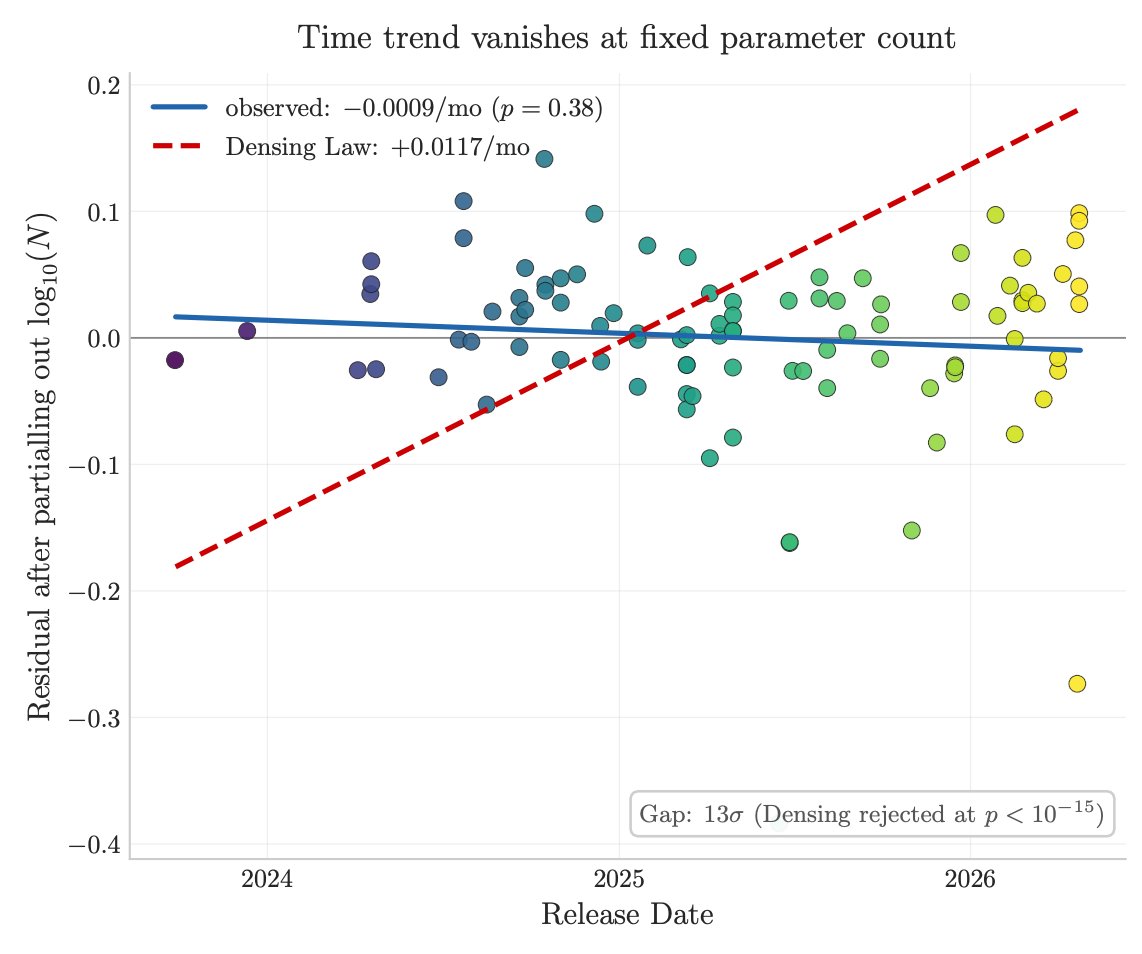
3/ Factual capacity doesn't compress over time. Across 96 open-weight models across 3 years, the IKP time coefficient is statistically zero, rejecting the Densing-Law prediction of +0.0117/month at p<10⁻¹⁵. Reasoning benchmarks saturate; factual capacity keeps scaling with parameters.
Website: https://t.co/CkwJsXqnsX
Paper: https://t.co/eNUdC9ye7w
Totally agree that AlphaFold didn't “solve” protein folding!
A system that accurately predicts final structures hasn't explained why those residues fold that way, eg., the energy landscape, the kinetic pathways, what happens co-translationally before the chain is even released from the ribosome… etc
“Solving” means understanding the mechanism. That's a different kind of question. It's the difference between predicting where a ball lands and understanding gravity.
Without that, we can't explain misfolding diseases from first principles, design truly novel protein architectures, or predict how mutations shift folding kinetics rather than just final structure.
AlphaFold gave us better maps. The physics of folding is still largely uncharted.
DeepSeek-V3: Dec 26, 2024
DeepSeek-V4: Apr 24, 2026
484 days later, we humbly share our labor of love.
As always, we stay true to long-termism and open source for all.
AGI belongs to everyone. ❤️🌍
#DeepSeekV4#AGIforEveryone#OpenSource
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n