I ran Claude in a loop for 3 months and created a brand new "GenZ" programming language.
It's called @cursedlang.
v0.0.1 is now available, and the website is ready to go.
Details below!
📈 now trending on alphaXiv
"SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning"
SkillRL turns an LLM agent’s messy trial-and-error trajectories into a compact & searchable skill library that recursively grows during RL
This lets the agent actually learns reusable strategies over time instead of just replaying raw memories, yielding big gains (+15.3% over strong baselines) with far fewer tokens!
new preprint!
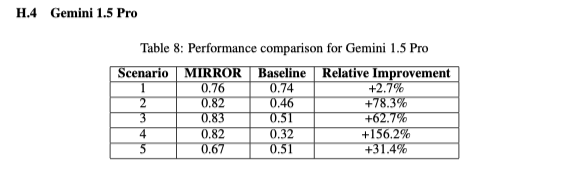
turns out, if your model is confident on _any_ long enough input, we can find other inputs where the model is wrong, yet its perplexity won't really tell you it's wrong 📉
work with @fedzbar@ccperivol@sindero and Razvan
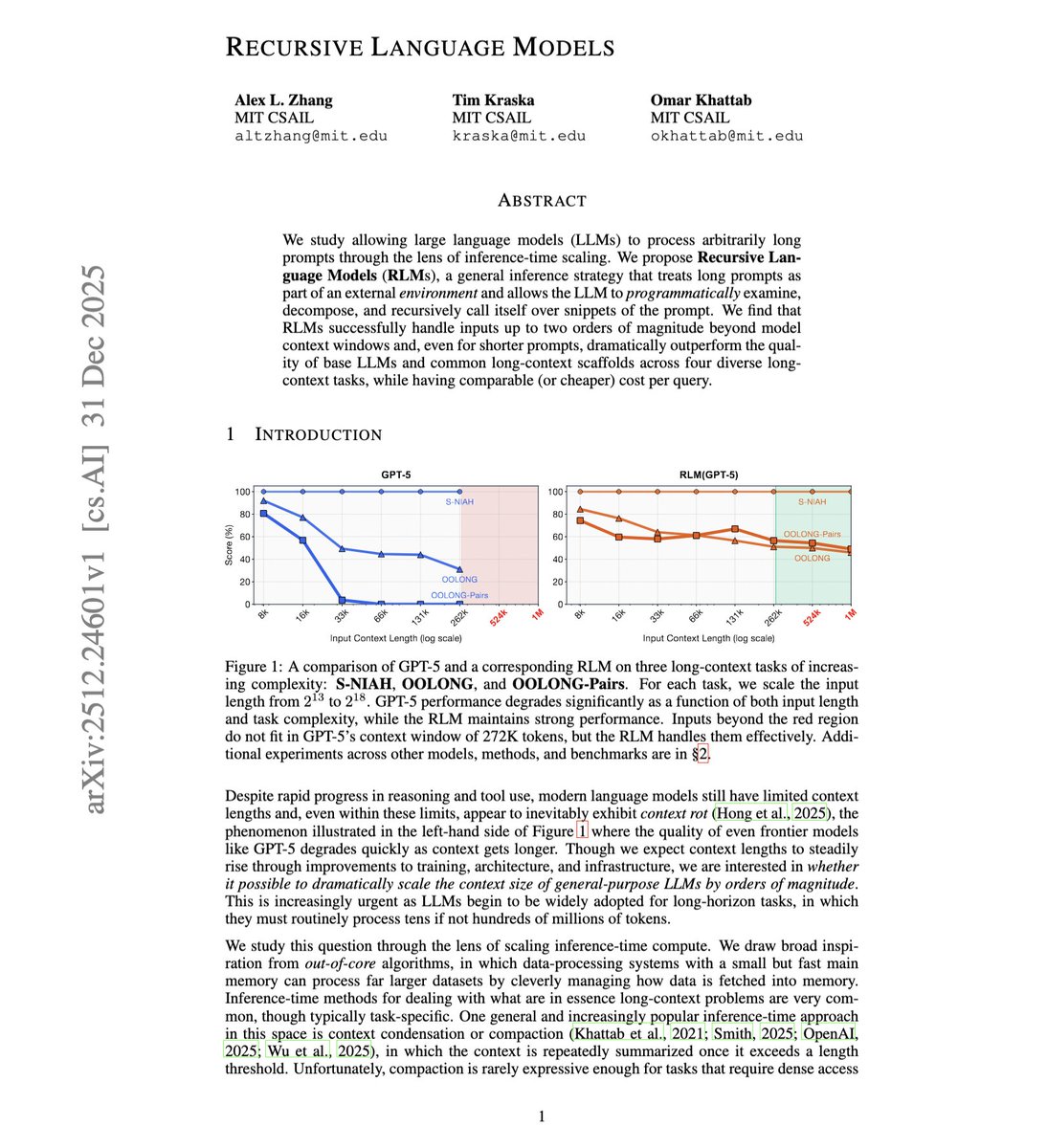
"Recursive Language Models"
A potentially big direction for LLMs in 2026 from MIT researchers
In their approach, a prompt isn’t “run” directly, instead it’s stored as a variable in an external Python REPL, and the language model writes code to inspect/slice/decompose that long string, observes execution outputs, and then constructs sub-tasks where it recursively invokes an LLM on just the relevant snippets. Stitching the result together when the recursive process ends.
so it can solve 10M+ token tasks with far less “context rot” and often lower cost than summarization/RAG, turning long-context scaling into an inference-time algorithm rather than just a bigger context window.
We talk about (and compare against) context compaction in the RLM paper.
TLDR: sadly, compaction is a deeply flawed approach "for tasks that require dense access to many parts of the prompt".
This is because compaction "presumes in effect that some details that appear early in the prompt can safely be forgotten to make room for new content".
For genuinely hard long-context tasks, you need to be able to re-access just about any part of the context later! Nothing is safe to forget.
The active vs passive debate is officially dead. A new category has just emerged: agentic investing.
Wall Street's about to get AI-memeified where fundamentals matter less than attention. And the flows are just warming up.
This will be Wall Street’s defining theme of 2026.
We release PostTrainBench: a benchmark measuring how well AI agents like Claude Code can post-train base LLMs.
We expect this to be an important indicator for AI R&D automation as it unfolds over the next few years.
🔗 https://t.co/dVSSHkpAE1
📂 https://t.co/vqZNrQw66z
1/n
Dr. Jeff Beck is probably the best guy in the active inference space who talks about it that I know of.
He also wrote this on a post on lesswrong a few years back -
"The short answer is that, in a POMDP setting, FEP agents and RL agents can be mapped one onto the other via appropriate choice of reward function and inference algorithm. One of the goals of the FEP is to come with a normative definition of the reward function (google the misleadingly titled "optimal control without cost functions" paper or, for a non-FEP version of the same, thing google the accurately titled: "Revisiting Maximum Entropy Inverse Reinforcement Learning"). Despite the very different approaches, the underlying mathematics is very similar as both are strongly tied to KL control theory and Jaynes' maximum entropy principle. But the ultimate difference between FEP and RL in a POMDP setting is how an agent is defined. RL needs an inference algorithm and a reward function that operates on action and outcomes, R(o,a). The FEP needs stationary blanket statistics, p(o,a), and nothing else. The inverse reinforcement paper shows how to go from p(o,a) to a unique R(o,a) assuming a bayes optimal RL agent in a MDP setting. Similarly, if you start with R(o,a) and optimize it, you get a stationary distribution, p(o,a). This distribution is also unique under some 'mild' conditions. So they are more or less equivalent in terms of expressive power. Indeed, you can generalize all this crap to show any subsystem of any physical system can be mathematically described as Bayes optimal RL agent. You can even identify the reward function with a little work. I believe this is why we intuitively anthropomorphize physical systems, i.e. when we say things like they system is "seeking" a minimum energy state.
But regardless, from a pragmatic perspective they are equally expressive mathematical systems. The advantage of one over the other depends upon your prior knowledge and goals. If you know the reward function and have knowledge of how the world works use RL. If you know the reward function but are in a POMDP setting without knowledge of how the world works, use an information seeking version of RL (maxentRL or BayesianRL). If you dont know the reward function but do know how the world works and have observations of behavior use max ent inverseRL).
The problem with RL is that its unclear how to use it when you don't know how the world works and you don't know what the reward function is, but do have observations of behavior. This is the situation when you are modeling behavior as in the url you cited. In this setting, we don't know what model humans are using to form their inferences and we don't know what motivates their behavior. If we are lucky we can glean some notion of their policy by observing behavior, but usually that notion is very coarse i.e. we may only know the average distribution of their actions and observations, p(o,a). The utility of the FEP is that p(o,a) defines the agent all by itself. This means we can start with a policy and infer both belief and reward. This is not something RL was designed to do. RL is for going from reward and belief (or belief formation rules) to policy, not the other way around. IRL can go backward, but only if your beliefs are Bayes optimal.
As for the human brain, I am fully committed to the Helmholtzian notion that the brain is a statistical learning machine as in the Bayesian brain hypothesis with the added caveat that it is important to remember that the brain is massively suboptimal."
“In the most basic setup, an RL Agent observes the environment, acts, and obtains a reward. It then updates its policy etc. Do you see the issue here? The reward is modeled as part of the environment. The agent acts in the environment, and the environment provides back a reward. The reward is external to the agent: it is part of the world.”
“I argue that this is a very weird, unnatural, and just plain wrong way to think about rewards. It is not how cognitive scientists thinks about rewards in RL … This is just not how the world actually works.”
We have been saying this for years too (as part of our active inference coverage), the standard textbook RL setup with a fixed reward attached to the environment is conceptually wrong.
Excellent post I enjoyed reading a draft of.
More broadly, it’s about time that our learning algorithms themselves become more intelligent and reflective, not just curve fitting.
This paper from Tsinghua University and Shanghai Jiao Tong University received perfect scores (6, 6, 6, 6) at NeurIPS 2025!
It aims to answer a key question: Does reinforcement learning really make large language models better reasoners?
The authors study Reinforcement Learning with Verifiable Rewards (RLVR) and find that while it improves accuracy for small k, it doesn’t create new reasoning patterns—meaning the base model still determines the upper limit of reasoning ability.
Across six RLVR variants, performance gains plateau, suggesting that current RL setups mainly refine reasoning rather than reinvent it.
Interestingly, it’s distillation, not RL, that shows genuine signs of emergent reasoning.
This research points to the next frontier for truly self-improving large language models.
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Paper: https://t.co/jOvAn6eGIZ
Page: https://t.co/o951L62oR6
Our report: https://t.co/nnMLg0FC5p
📬 #PapersAccepted by Jiqizhixin
We're missing (at least one) major paradigm for LLM learning. Not sure what to call it, possibly it has a name - system prompt learning?
Pretraining is for knowledge.
Finetuning (SL/RL) is for habitual behavior.
Both of these involve a change in parameters but a lot of human learning feels more like a change in system prompt. You encounter a problem, figure something out, then "remember" something in fairly explicit terms for the next time. E.g. "It seems when I encounter this and that kind of a problem, I should try this and that kind of an approach/solution". It feels more like taking notes for yourself, i.e. something like the "Memory" feature but not to store per-user random facts, but general/global problem solving knowledge and strategies. LLMs are quite literally like the guy in Memento, except we haven't given them their scratchpad yet. Note that this paradigm is also significantly more powerful and data efficient because a knowledge-guided "review" stage is a significantly higher dimensional feedback channel than a reward scaler.
I was prompted to jot down this shower of thoughts after reading through Claude's system prompt, which currently seems to be around 17,000 words, specifying not just basic behavior style/preferences (e.g. refuse various requests related to song lyrics) but also a large amount of general problem solving strategies, e.g.:
"If Claude is asked to count words, letters, and characters, it thinks step by step before answering the person. It explicitly counts the words, letters, or characters by assigning a number to each. It only answers the person once it has performed this explicit counting step."
This is to help Claude solve 'r' in strawberry etc. Imo this is not the kind of problem solving knowledge that should be baked into weights via Reinforcement Learning, or least not immediately/exclusively. And it certainly shouldn't come from human engineers writing system prompts by hand. It should come from System Prompt learning, which resembles RL in the setup, with the exception of the learning algorithm (edits vs gradient descent). A large section of the LLM system prompt could be written via system prompt learning, it would look a bit like the LLM writing a book for itself on how to solve problems. If this works it would be a new/powerful learning paradigm. With a lot of details left to figure out (how do the edits work? can/should you learn the edit system? how do you gradually move knowledge from the explicit system text to habitual weights, as humans seem to do? etc.).