Antropólogo @pucp - Mag. Filosofía @UOCuniversidad
STS/ Etnografía Multiespecies/ Posthumanismo, Diseño y Cuidado/ Qualitative Research Methods/ Matters of Care
'Transforming Science,' by Salvador Zárate, Kalindi Vora, Saiba Varma, Leslie Quintanilla, and Christoph Hanssmann, demonstrates how to apply tools derived from social justice-informed research to problems in #science and #technology: https://t.co/puyAKUO8ZI. @sezarate25
We’re thrilled to announce the publication of our latest textbooks across our Human Geography, Environment and Sustainability, and Science and Technology Studies programmes!
'Rethinking Sustainability'—edited by Antje Brown and Sandra Gilgan—offers innovations in how #sustainability is studied, taught, and practiced across academic and professional contexts: https://t.co/BzGgpYXw7l.
Countless researchers have shown that the most meaningful forms of real-world creativity and invention depend less on solving well-defined problems than on figuring out what the problem is in the first place. https://t.co/iz3qQxfYVy
Designing interactive textiles for emotional well-being. 📱
Jiang et al. investigate how body-centred textile interactions can support emotion regulation through multisensory feedback and movement-based design.
https://t.co/z5hWbgUlbI
Our findings on distorted perception add a new dimension to great work on AI writing assistance by @marwaabdulhai@natashajaques@advaitmb@m_jakesch & others. AI-assisted writing may soon be the norm, so it’s urgent that we understand the consequences!
https://t.co/CmUVVOLjb9
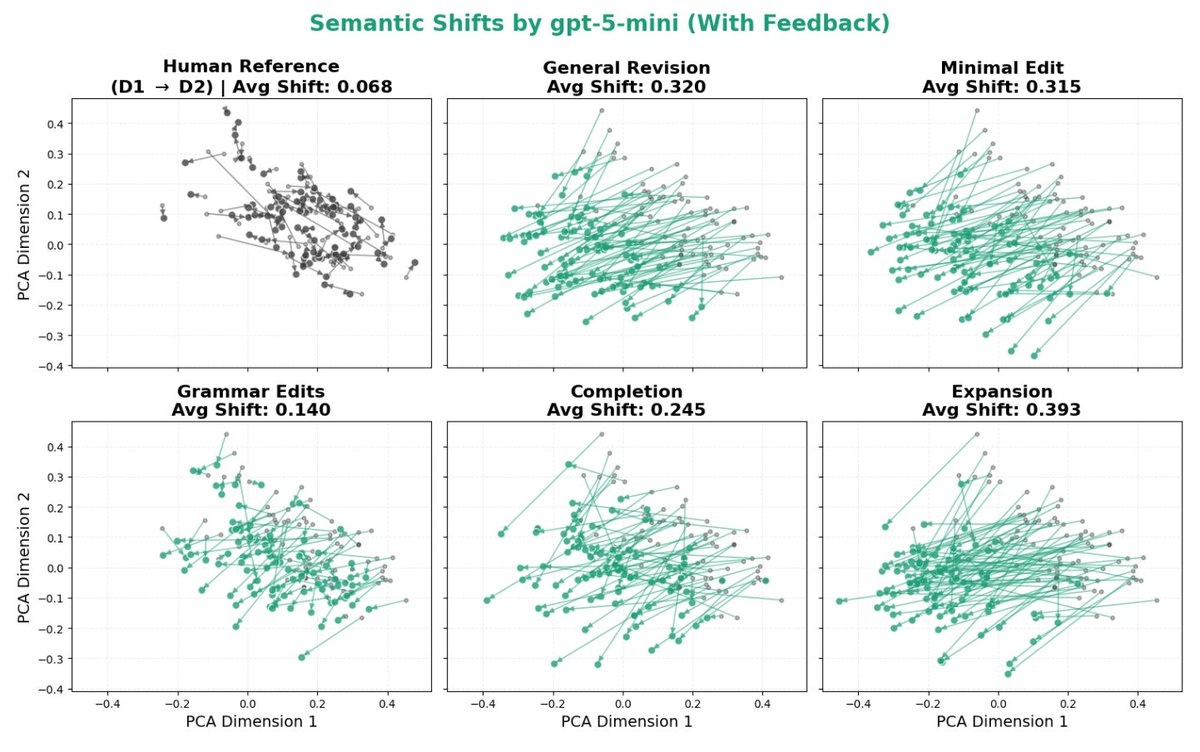
The paper I’ve been most obsessed with lately is finally out: https://t.co/KgdWKknCJK! Check out this beautiful plot: it shows how much LLMs distort human writing when making edits, compared to how humans would revise the same content.
We take a dataset of human-written essays from 2021, before the release of ChatGPT. We compare how people revise draft v1 -> v2 given expert feedback, with how an LLM revises the same v1 given the same feedback. This enables a counterfactual comparison: how much does the LLM alter the essay compared to what the human was originally intending to write? We find LLMs consistently induce massive distortions, even changing the actual meaning and conclusions argued for.
RIP German anthropologist Johannes Fabian, who passed away last week. He was most widely known for "Time and the Other: How Anthropology Makes its Object" (1983), a then-radical & still-influential critique of anthropological writing, knowledge-making & fieldwork relations.
Major preprint just out!
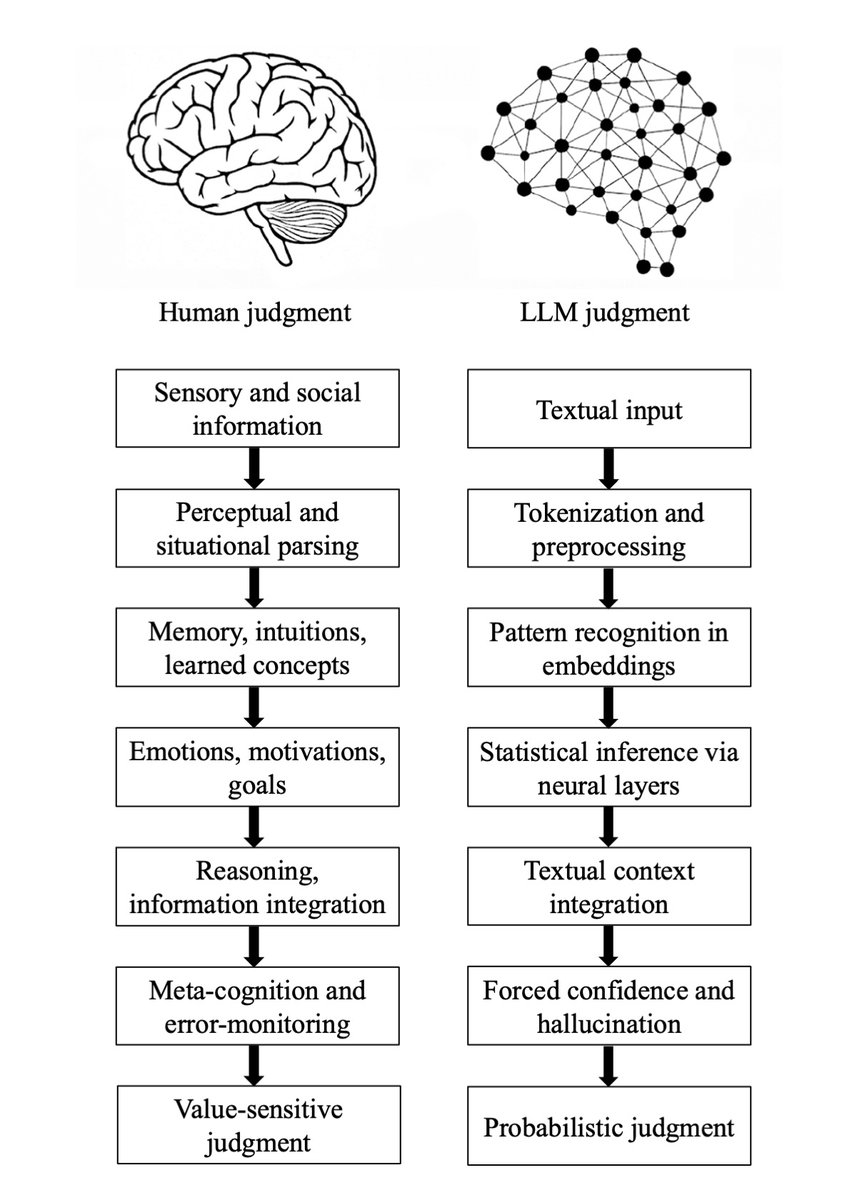
We compare how humans and LLMs form judgments across seven epistemological stages.
We highlight seven fault lines, points at which humans and LLMs fundamentally diverge:
The Grounding fault: Humans anchor judgment in perceptual, embodied, and social experience, whereas LLMs begin from text alone, reconstructing meaning indirectly from symbols.
The Parsing fault: Humans parse situations through integrated perceptual and conceptual processes; LLMs perform mechanical tokenization that yields a structurally convenient but semantically thin representation.
The Experience fault: Humans rely on episodic memory, intuitive physics and psychology, and learned concepts; LLMs rely solely on statistical associations encoded in embeddings.
The Motivation fault: Human judgment is guided by emotions, goals, values, and evolutionarily shaped motivations; LLMs have no intrinsic preferences, aims, or affective significance.
The Causality fault: Humans reason using causal models, counterfactuals, and principled evaluation; LLMs integrate textual context without constructing causal explanations, depending instead on surface correlations.
The Metacognitive fault: Humans monitor uncertainty, detect errors, and can suspend judgment; LLMs lack metacognition and must always produce an output, making hallucinations structurally unavoidable.
The Value fault: Human judgments reflect identity, morality, and real-world stakes; LLM "judgments" are probabilistic next-token predictions without intrinsic valuation or accountability.
Despite these fault lines, humans systematically over-believe LLM outputs, because fluent and confident language produce a credibility bias.
We argue that this creates a structural condition, Epistemia:
linguistic plausibility substitutes for epistemic evaluation, producing the feeling of knowing without actually knowing.
To address Epistemia, we propose three complementary strategies: epistemic evaluation, epistemic governance, and epistemic literacy.
Full paper in the first reply.
Joint with @Walter4C & @matjazperc
It is with more sadness than mere words can convey that we have to report that our beloved Ozzy Osbourne has passed away this morning. He was with his family and surrounded by love.
We ask everyone to respect our family privacy at this time.
Sharon, Jack, Kelly, Aimee and Louis
"For the first time in two centuries, the West is no longer the leader in future technology, but the follower."
That's the key thread in the excellent new @polycrisis piece on the BRICS in 2025 https://t.co/vYqg91ml2H
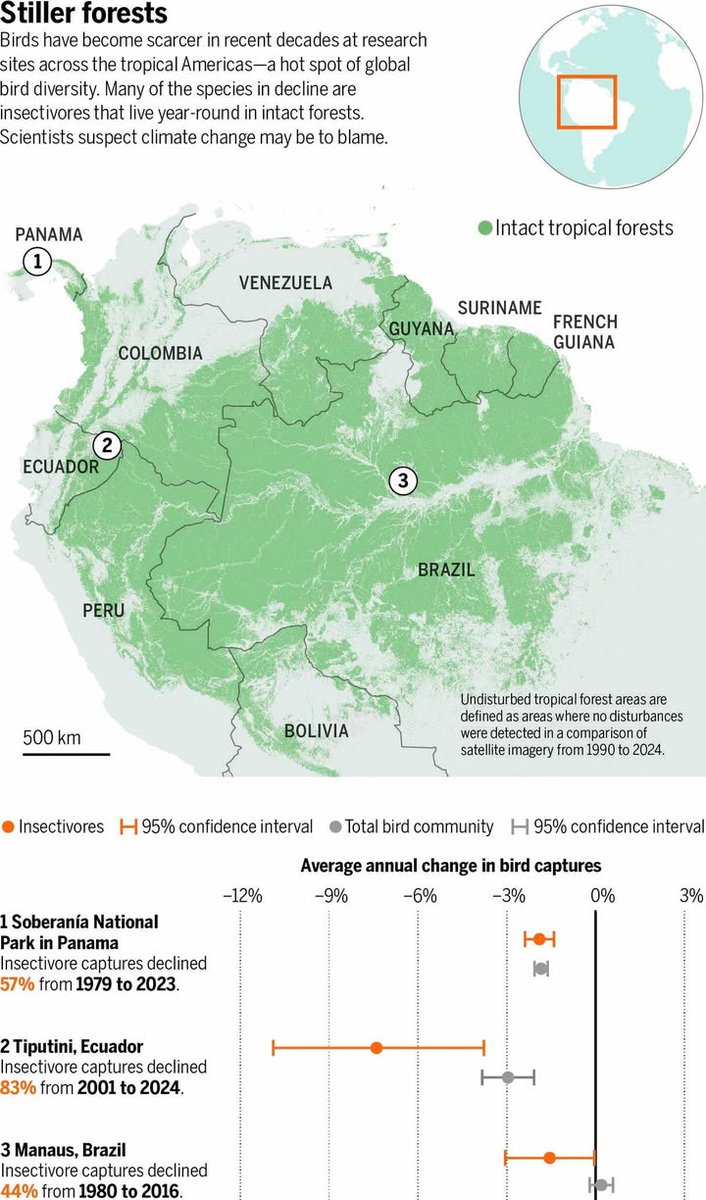
If human activity continues to affect biodiversity as it is today, we project that in the next 100 years, we will lose more than three times the number of bird species as have been lost since 1500.
https://t.co/5gWSapDD5K