Sadly, it's true. Amazon has elected not to move forward with the new Stargate series.
There's not much I can add beyond confirming what's happened. But I will say this...
Creator Martin Gero developed a new Stargate series over two years, ultimately crafting a show that offered a fresh jumping-on point for new viewers while deeply respecting existing canon. It was a series that avoided the pitfalls of several modern remakes and reboots by fully embracing the core of its predecessors: action, adventure, exploration, wonder, heart, humor, and found family. And based on that creative vision, the new Stargate series was greenlit in November of 2025.
As of today, officially, that original vision is no more. We'll never get the opportunity to introduce you to that world and those characters - or reintroduce you to, and check in with, some familiar faces from the past.
My heart breaks. For the incredibly talented writers who worked tirelessly to bring this show to life. For Martin who maintained an unwavering positive outlook throughout despite the challenges, and who always strove to make a show that would honor the fans while welcoming a new audiences. And for the long-suffering Stargate fandom who waited so long and came so close to getting a show they truly would have loved.
We are in deep, deep trouble.
A reader wrote in to me this week saying that they wouldn't read my Trump corruption story because ChatGPT "fact-checked the piece" and informed them most of it was false.
Among other things, ChatGPT told them that there is no Iran war, Jared Kushner is not a negotiator in the war, Qatar never offered Trump a $400 million plane, George Santos wasn't pardoned, the NYTimes did not report on Syrian billionaires lobbying Trump for sanctions relief, Trump never launched a meme coin, and World Liberty Financial (the Trump family crypto firm) doesn't exist.
Of course, all of these things ARE real, do exist, and are happening right now. Apparently, the reader copy and pasted the text of my story into ChatGPT, and without the links ChatGPT couldn't confirm any of it. Once the reader sent ChatGPT the link to the story, it ended up concluding all the facts were correct.
How many people simply don't know how to use AI and are offloading all their thinking? It's a terrifying thought. And a totally new frontier of reality to navigate.
By popular demand, we've removed the paywall on this piece to make it accessible to the public. If you find it valuable, please consider signing up for our free newsletter or supporting our work with a membership. https://t.co/a1DdwHmzJL
The National Park Service ran on a $3 billion budget and generated $56 billion in economic output in 2024. That’s over $17 back for every $1 invested.
With a record of 332 million visitors last year, Americans clearly care about their parks and expect them to be funded.
Japanese engineers developed a “Sword Tip Visualization System” for the Fencing World Championships, and it makes fencing look absolutely incredible to watch.
Leaving Earth orbit, ✅. Next up: Finalizing the Moon observation plan.
Artemis II is both a test flight and a science mission. Astronauts, flight controllers, & science teams are working together to squeeze as much knowledge as possible out of the crew’s lunar flyby. ⬇️ (1/6)
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
https://t.co/WAz8aIztKT
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.
nanochat can now train GPT-2 grade LLM for <<$100 (~$73, 3 hours on a single 8XH100 node).
GPT-2 is just my favorite LLM because it's the first time the LLM stack comes together in a recognizably modern form. So it has become a bit of a weird & lasting obsession of mine to train a model to GPT-2 capability but for much cheaper, with the benefit of ~7 years of progress. In particular, I suspected it should be possible today to train one for <<$100.
Originally in 2019, GPT-2 was trained by OpenAI on 32 TPU v3 chips for 168 hours (7 days), with $8/hour/TPUv3 back then, for a total cost of approx. $43K. It achieves 0.256525 CORE score, which is an ensemble metric introduced in the DCLM paper over 22 evaluations like ARC/MMLU/etc.
As of the last few improvements merged into nanochat (many of them originating in modded-nanogpt repo), I can now reach a higher CORE score in 3.04 hours (~$73) on a single 8XH100 node. This is a 600X cost reduction over 7 years, i.e. the cost to train GPT-2 is falling approximately 2.5X every year. I think this is likely an underestimate because I am still finding more improvements relatively regularly and I have a backlog of more ideas to try.
A longer post with a lot of the detail of the optimizations involved and pointers on how to reproduce are here:
https://t.co/vhnK0d3L7B
Inspired by modded-nanogpt, I also created a leaderboard for "time to GPT-2", where this first "Jan29" model is entry #1 at 3.04 hours. It will be fun to iterate on this further and I welcome help! My hope is that nanochat can grow to become a very nice/clean and tuned experimental LLM harness for prototyping ideas, for having fun, and ofc for learning.
The biggest improvements of things that worked out of the box and simply produced gains right away were 1) Flash Attention 3 kernels (faster, and allows window_size kwarg to get alternating attention patterns), Muon optimizer (I tried for ~1 day to delete it and only use AdamW and I couldn't), residual pathways and skip connections gated by learnable scalars, and value embeddings. There were many other smaller things that stack up.
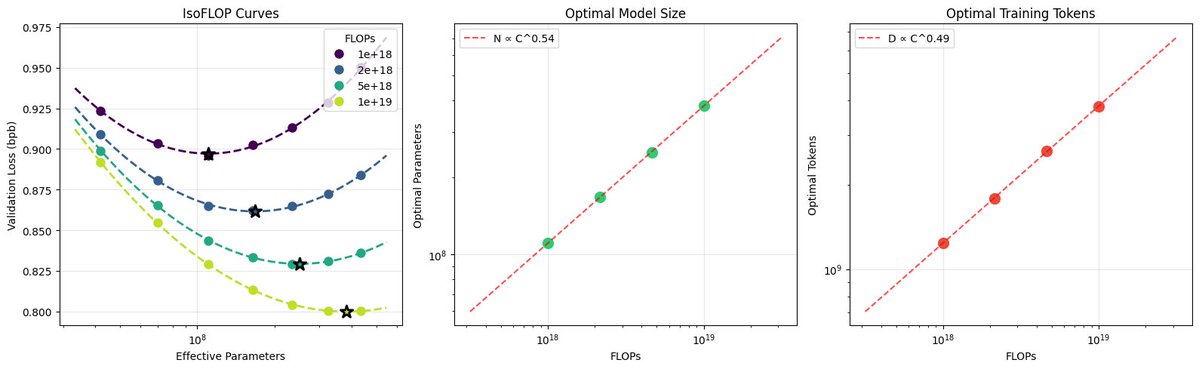
Image: semi-related eye candy of deriving the scaling laws for the current nanochat model miniseries, pretty and satisfying!
I was inspired by this so I wanted to see if Claude Code can get into my Lutron home automation system.
- it found my Lutron controllers on the local wifi network
- checked for open ports, connected, got some metadata and identified the devices and their firmware
- searched the internet, found the pdf for my system
- instructed me on what button to press to pair and get the certificates
- it connected to the system and found all the home devices (lights, shades, HVAC temperature control, motion sensors etc.)
- it turned on and off my kitchen lights to check that things are working (lol!)
I am now vibe coding the home automation master command center, the potential is 🔥.And I'm throwing away the crappy, janky, slow Lutron iOS app I've been using so far. Insanely fun :D :D
In today's episode of programming horror...
In the Python docs of random.seed() def, we're told
"If a is an int, it is used directly." [1]
But if you seed with 3 or -3, you actually get the exact same rng object, producing the same streams. (TIL). In nanochat I was using the sign as a (what I thought was) clever way to get different rng sequences for train/test splits. Hence gnarly bug because now train=test.
I found the CPython code responsible in cpython/Modules/_randommodule.c [2], where on line 321 we see in a comment:
"This algorithm relies on the number being unsigned. So: if the arg is a PyLong, use its absolute value." followed by
n = PyNumber_Absolute(arg);
which explicitly calls abs() on your seed to make it positive, discarding the sign bit.
But this comment is actually wrong/misleading too. Under the hood, Python calls the Mersenne Twister MT19937 algorithm, which in the general case has 19937 (non-zero) bits state. Python takes your int (or other objects) and "spreads out" that information across these bits. In principle, the sign bit could have been used to augment the state bits. There is nothing about the algorithm that "relies on the number being unsigned". A decision was made to not incorporate the sign bit (which imo was a mistake). One trivial example could have been to map n -> 2*abs(n) + int(n < 0).
Finally this leads us to the contract of Python's random, which is also not fully spelled out in the docs. The contract that is mentioned is that:
same seed => same sequence.
But no guarantee is made that different seeds produce different sequences. So in principle, Python makes no promises that e.g. seed(5) and seed(6) are different rng streams. (Though this quite commonly implicitly assumed in many applications.) Indeed, we see that seed(5) and seed(-5) are identical streams. And you should probably not use them to separate your train/test behaviors in machine learning. One of the more amusing programming horror footguns I've encountered recently. We'll see you in the next episode.
[1] https://t.co/srv1ZBlDsi
[2] https://t.co/qpnKdvfVNS
"AI isn't replacing radiologists" good article
Expectation: rapid progress in image recognition AI will delete radiology jobs (e.g. as famously predicted by Geoff Hinton now almost a decade ago). Reality: radiology is doing great and is growing.
There are a lot of imo naive predictions out there on the imminent impact of AI on the job market. E.g. a ~year ago, I was asked by someone who should know better if I think there will be any software engineers still today. (Spoiler: I think we're going to make it). This is happening too broadly.
The post goes into detail on why it's not that simple, using the example of radiology:
- the benchmarks are nowhere near broad enough to reflect actual, real scenarios.
- the job is a lot more multifaceted than just image recognition.
- deployment realities: regulatory, insurance and liability, diffusion and institutional inertia.
- Jevons paradox: if radiologists are sped up via AI as a tool, a lot more demand shows up.
I will say that radiology was imo not among the best examples to pick on in 2016 - it's too multi-faceted, too high risk, too regulated. When looking for jobs that will change a lot due to AI on shorter time scales, I'd look in other places - jobs that look like repetition of one rote task, each task being relatively independent, closed (not requiring too much context), short (in time), forgiving (the cost of mistake is low), and of course automatable giving current (and digital) capability. Even then, I'd expect to see AI adopted as a tool at first, where jobs change and refactor (e.g. more monitoring or supervising than manual doing, etc). Maybe coming up, we'll find better and broader set of examples of how this is all playing out across the industry.
About 6 months ago, I was also asked to vote if we will have less or more software engineers in 5 years. Exercise left for the reader.
Full post (the whole The Works in Progress Newsletter is quite good):
https://t.co/ON3GwlI3mi
We are saddened by the passing of Jim Lovell, commander of Apollo 13 and a four-time spaceflight veteran.
Lovell's life and work inspired millions. His courage under pressure helped forge our path to the Moon and beyond—a journey that continues today. https://t.co/AjT8qmxsZI
Trump bombing Iran, Mamdani winning the NYC democrat mayoral primary, and Cluely's raise reveal a lot about the architecture of power. Attention → Speculation → Allocation is the new supply chain
The bombing was yet again a Trumpian inversion of system architecture - flipping how information and decision-making traditionally flow and raising social media dynamics above all. Mamdani's win was very interesting for many reasons, but really highlights that attention is the path to institutional override (just like Trump, but from the other side). And Cluely is the synthesis of attention capture capability - and attention as a fundable asset class.
Attention is the raw material of economic, political, and military action. But speculation is what operationalizes that attention: the bets people place (emotionally, politically, financially) on what narrative will become real.
Link in next post! There is a Part 2 coming next week, so please subscribe for that.


































![karpathy's tweet photo. In today's episode of programming horror...
In the Python docs of random.seed() def, we're told
"If a is an int, it is used directly." [1]
But if you seed with 3 or -3, you actually get the exact same rng object, producing the same streams. (TIL). In nanochat I was using the sign as a (what I thought was) clever way to get different rng sequences for train/test splits. Hence gnarly bug because now train=test.
I found the CPython code responsible in cpython/Modules/_randommodule.c [2], where on line 321 we see in a comment:
"This algorithm relies on the number being unsigned. So: if the arg is a PyLong, use its absolute value." followed by
n = PyNumber_Absolute(arg);
which explicitly calls abs() on your seed to make it positive, discarding the sign bit.
But this comment is actually wrong/misleading too. Under the hood, Python calls the Mersenne Twister MT19937 algorithm, which in the general case has 19937 (non-zero) bits state. Python takes your int (or other objects) and "spreads out" that information across these bits. In principle, the sign bit could have been used to augment the state bits. There is nothing about the algorithm that "relies on the number being unsigned". A decision was made to not incorporate the sign bit (which imo was a mistake). One trivial example could have been to map n -> 2*abs(n) + int(n < 0).
Finally this leads us to the contract of Python's random, which is also not fully spelled out in the docs. The contract that is mentioned is that:
same seed => same sequence.
But no guarantee is made that different seeds produce different sequences. So in principle, Python makes no promises that e.g. seed(5) and seed(6) are different rng streams. (Though this quite commonly implicitly assumed in many applications.) Indeed, we see that seed(5) and seed(-5) are identical streams. And you should probably not use them to separate your train/test behaviors in machine learning. One of the more amusing programming horror footguns I've encountered recently. We'll see you in the next episode.
[1] https://t.co/srv1ZBlDsi
[2] https://t.co/qpnKdvfVNS](https://pbs.twimg.com/media/G7sc167aMAAuZi5.png)























