"This is the most complex software object humanity has yet produced...
And it will be trivial in a couple of decades."
- Sam Altman talking about GPT4 (Mar 2023)
✨ xAI publicó ayer el algoritmo de X y no entiendo cómo nadie se ha dado cuenta de lo que realmente tiene en sus tripas
Me he fundido 500 pavos en Claude analizando hasta la última línea
Esto es lo que he descubierto (POST LARGO, guárdatelo para luego):
0/ Cada cuenta tiene un "embedding" asociado que te describe como lo hacen los modelos de IA: en el espacio latente. Es la huella digital interna que el modelo guarda de cada usuario, un vector de números que resume cómo se comporta tu cuenta (qué temas tocas, qué engagement generas, con quién interactúas). El modelo lo usa cada vez que decide a quién enseñar tus posts. Si tu historial es bueno, queda limpio y el modelo te empuja. Si vas acumulando señales negativas (bloqueos, mutes, reports, not_interested), se vuelve tóxico y empieza a penalizarte automáticamente. Y la trampa: NO se resetea. Lo que hagas hoy sigue dentro durante semanas, contaminando todo lo que publiques después, aunque sea bueno.
Por eso salir de un shadowban o de épocas de bajo alcance se siente en X como intentar mover una gigantesca rueda oxidada: no es tu imaginación, es así tal cual. Limpiar/mejorar tu embedding es algo lento y farragoso, es como la impresión que tienes de alguien que te cae mal: por muy simpático que se vuelva contigo, va a pasar bastante tiempo hasta que te fíes de él.
Otro descubrimiento importante: el embedding no decae con un reloj. Decae con engagement NUEVO entrando al sistema. Si dejas de postear, las señales malas viejas se quedan congeladas dentro: nadie las sobrescribe. Si comienzas a crear contenido que al algoritmo le gusta, notarías mejora a partir de las 6-8 semanas y un cambio decente sobre las 12-16 semanas, asumiendo que no acumulas más señales malas en medio.
¿Por qué nadie está hablando de esto? Me parece tremendo y por fin una confirmación de esa sensación de "estoy en una mala racha" por la que todos hemos pasado.
1/ Los primeros 30 minutos lo son TODO
Si tu post no recibe interacciones rápido, Grok ni siquiera lo evalúa. Sin nota de calidad, sin análisis profundo, sin posibilidad de llegar a quien no te sigue. Muerto y enterrado
2/ La edad del post tiene un cap de 80 horas:
POST_AGE_MAX_MINUTES = 4800, en buckets de 1 hora. Después estás en el "overflow bucket" que se traduce como "antiguo, ignorar"
Mejor ventana: las primeras 0 a 12 horas. Pasadas las 24 ya estás en un bucket peor
Vamos, lejos de incentivar el contenido "evergreen", X quiere carnaza fresca continua (todo lo contrario que YouTube)
3/ MI MAYOR MIEDO ERA INFUNDADO (se supone): vivir en EU y postear en inglés para audiencia US: CERO penalización directa en teoría:
El struct PostCandidate no tiene NINGÚN campo de país del autor, IP ni localización. Gizmoduck (el servicio de identidad de X) solo devuelve follower count + screen name. El transformer de Phoenix solo ve un hash de tu author_id
Lo que sí te jode indirectamente: el huso horario (tu post envejece mientras US duerme) y el idioma DEL POST
Vamos, que usar una VPN para "postear desde US" no hace literalmente nada (a diferencia que en TikTok o Instagram, por cierto)
4/ Las 5 señales negativas que matan tu alcance:
El modelo predice 22 acciones por post. 5 son pesos negativos que se RESTAN de tu score:
- not_interested
- block_author
- mute_author
- report
- not_dwelled (gente haciendo scroll sin pararse en tu post)
Esa última es brutal la verdad. Un post que se ignora es matemáticamente PEOR que uno que nunca se llegó a publicar
5/ Los shadowbans existen 100%. Hay 4 tipos distintos:
- Hard drop. X borra tu post del feed de todo el mundo sin avisarte. Se aplica a posts con contenido grave (abuso infantil, etc.) o cuentas suspendidas. Tú ni te enteras
- Etiqueta DO_NOT_AMPLIFY. Es literalmente un campo en el código que dice "no amplificar este post". Si te la ponen, los anuncios dejan de aparecer al lado de tus posts → X deja de ganar dinero mostrándote → el sistema deja de pushearte. Apagón en seco
- Reglas de BotMaker. Es el panel interno desde el que los empleados de X pueden limitar a una cuenta concreta a mano. En el código se ven las categorías que existen (Content, ContentLimited, Safety, Grok) pero NO se ve a quién se las aplican ni por qué. La herramienta está documentada, los usos no
- Embedding envenenado. El más jodido como ya vimos antes. El modelo tiene una "memoria" interna por cada cuenta. Si tu cuenta acumula suficientes "no me interesa" + bloqueos + silencios + reports a lo largo del tiempo, esa memoria se vuelve tóxica. A partir de ahí, incluso tus buenos posts futuros se penalizan automáticamente. Nadie lo decidió. El modelo simplemente aprendió que tu cuenta da mal engagement, y se autocorrigió
6/ Solo los posts ORIGINALES pasan por el "Banger Screen"
Las respuestas y retweets nunca entran en el clasificador de calidad de Grok. Si te pasas el día respondiendo a cuentas virales, estás optimizando para el Reply Ranker, NO para la amplificación
¿Quieres que te descubran fuera de tu red? Escribe posts originales, no hay otra
7/ Las respuestas a cuentas pequeñas pasan por escáner anti-spam. Las respuestas a cuentas grandes pasan por Grok
Dos clasificadores distintos. El SpamEapiLowFollowerClassifier pega a las respuestas a cuentas pequeñas. El ReplyRanker puntúa de 0 a 3 con Grok las respuestas a cuentas grandes
"¡Primero!" o respuestas solo con emojis sacan un 0. El rollo tipo "Sir, this is a Wendy's" se penaliza. Vamos, que si escribes respuestas, más te valen que aporten algo, si no, mejor ni te molestes
8/ El 50% de todas las peticiones al feed son "tráfico shadow"
is_sampled(request_id, 0.5) marca como shadow la mitad de cada feed request. Muchas features contextuales (inferencia de género, demografía, preferencias de topics Grok) solo se activan en shadow O con un feature flag
Traducción: literalmente no puedes saber qué versión del algoritmo está viendo cualquier usuario. La mitad de tu audiencia está en un experimento en cualquier momento
9/ El dwell (el tiempo que un usuario se queda mirando tu post antes de hacer scroll) es 5x veces mejor que recibir likes
El scorer tiene 5 señales distintas de dwell (dwell, cont_dwell_time, click_dwell_time, etc.) pero solo 1 señal de favorito.
- Un post con un montón de likes pero la gente lo lee 1 segundo y sigue scrolleando → score bajo
- Un post con pocos likes pero la gente se queda 8 segundos leyéndolo → score alto
¡Optimiza por tiempo pasado en tu post, no por likes!
10/ Cosas que sí funcionan:
- Engagement en los primeros 10 min. Manda DM a tus colegas, pingea a tu comunidad, lo que sea
- Postea en la zona horaria de TU AUDIENCIA, no en la tuya. Para targetear US: 8 a 11am ET (14 a 17 hora Madrid)
- No postees 5 cosas seguidas. El AuthorDiversityScorer multiplica cada post siguiente tuyo por decay^position. Para el post 4 ya estás en el suelo
- Vídeo ≥ 10 segundos. Por debajo de MinVideoDurationMs pierdes el peso VQV entero
- Vídeos con audio. Grok corre ASR (speech to text) en cada vídeo. Sin audio = señal en blanco
- Cita virales de tu nicho. El modelo ya sabe que el original engancha, tu valor añadido se apila encima
11/ Cosas que te destrozan el alcance:
- DESCUBRIMIENTO DE LA HOSTIA: hilos de más de 10 tweets. El DedupConversationFilter solo deja 1 tweet por conversación por feed. Los megahilos son matemáticamente un desperdicio
- Repostear el mismo contenido. Los bloom filters lo deduplican
- AI slop. Hay literalmente un campo slop_score en el output del BangerScreen. Lo detectan explícitamente
- NSFW/violencia/odio sin etiquetar. Auto MediumRisk = sin ads = shadowban estructural
- Spamear respuestas a cuentas pequeñas. Hay un clasificador específico para eso
12/ Lo que NO han publicado los muy pillines:
El esqueleto es público. Los diales no
- Los valores numéricos exactos de cada peso (FavoriteWeight, ReplyWeight, OonWeightFactor, AuthorDiversityDecay). Viven en xai_feature_switches::Params, config externa
- Los prompts reales de Grok (los 7 prompts de policy PToS, BangerMiniVlmScreenScore, SafetyPtos). Pueden tener literalmente cualquier framing
- Las reglas de BotMaker que aplican DO_NOT_AMPLIFY a cuentas concretas
- util/phoenix_request.rs, que construye la llamada final al modelo
- 25+ crates xai_* referenciados pero no incluidos
- Los pesos del Phoenix de producción. Solo han publicado la versión mini
Mi teoría: nos han puesto un esqueleto algo escuchimizado del total que tienen. El músculo (los pesos) y el cerebro (los prompts y las reglas de BotMaker) son completamente opacos. Se han reservado lo mejor, está claro
13/ Chuleta resumen para no olvidar:
- Los primeros 30 min importan más que cualquier otra cosa
- Tu ubicación es irrelevante, tu timing y tu idioma no
- Los shadowbans existen en 4 sabores. El peor es el modelo envenenándote el embedding de autor en silencio a partir de señales negativas pasadas, levantar caveza limpiando tu embedding te va a costar horrores, pero se puede
- Las respuestas y retweets no pasan por el clasificador de calidad. Los originales sí
- El dwell (que alguien se quede mirando tu post) le gana al like 5 a 1
- La mitad del tráfico está en algún experimento en cualquier momento
- Se han reservado lo mejor del algoritmo, pero bueno, algo es algo
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
I'm joining @OpenAI to bring agents to everyone. @OpenClaw is becoming a foundation: open, independent, and just getting started.🦞
https://t.co/XOc7X4jOxq
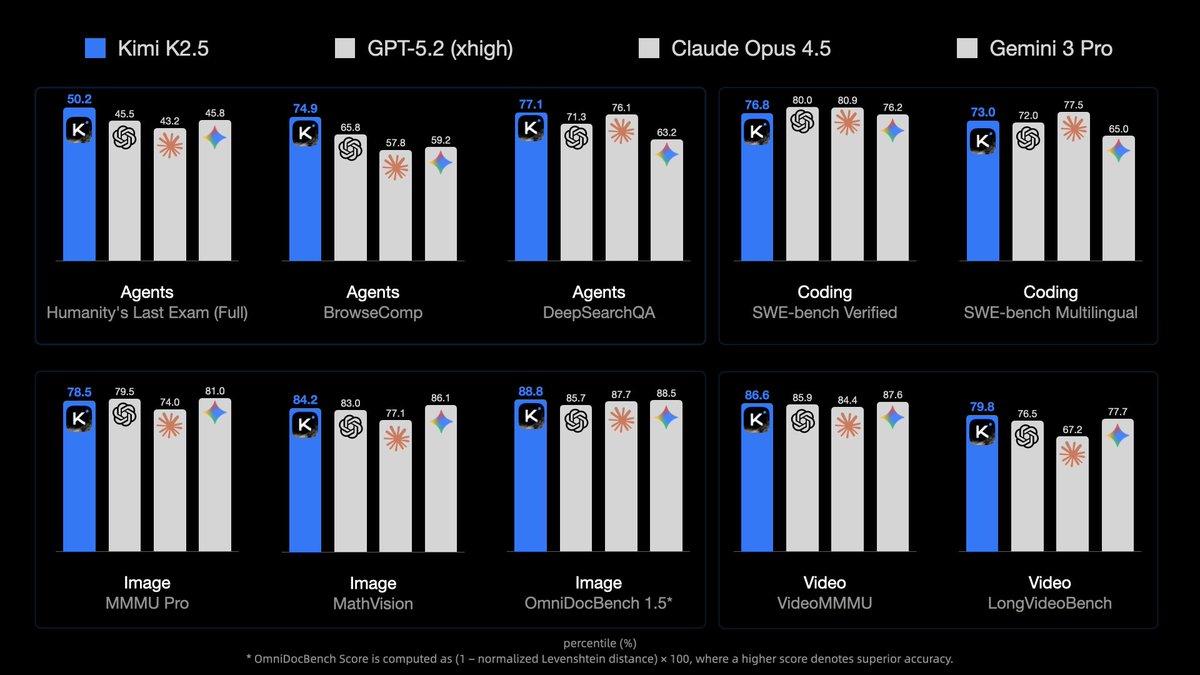
🥝 Meet Kimi K2.5, Open-Source Visual Agentic Intelligence.
🔹 Global SOTA on Agentic Benchmarks: HLE full set (50.2%), BrowseComp (74.9%)
🔹 Open-source SOTA on Vision and Coding: MMMU Pro (78.5%), VideoMMMU (86.6%), SWE-bench Verified (76.8%)
🔹 Code with Taste: turn chats, images & videos into aesthetic websites with expressive motion.
🔹 Agent Swarm (Beta): self-directed agents working in parallel, at scale. Up to 100 sub-agents, 1,500 tool calls, 4.5× faster compared with single-agent setup.
-
🥝 K2.5 is now live on https://t.co/YutVbwktG0 in chat mode and agent mode.
🥝 K2.5 Agent Swarm in beta for high-tier users.
🥝 For production-grade coding, you can pair K2.5 with Kimi Code: https://t.co/A5WQozJF3s
-
🔗 API: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/6h2KkoA0xd
🔗 Weights & code: https://t.co/H38KegeDIY
This is a multi-billion dollar business
Dusty robotics just invented a new tool that every single construction company will end up buying
Just like a Roomba, it drives around, but it’s not cleaning, instead it’s printing the floor plan on to the slab.
So simple, so powerful
Es imposible tener libertad de expresión sin que haya gente que abuse de ella.
Y es imposible que el poder controle la libertad de expresión sin que tienda a abusar de ese control.
De los dos abusos, es mucho más peligroso el segundo.
El presidente del Gobierno, @sanchezcastejon, miente sobre las centrales nucleares o demuestra su ignorancia sobre tecnología eléctrica al acusarlas de empeorar el apagón del 28 de abril de 2025.
Las centrales nucleares aportan inercia al sistema eléctrico, ayudando a evitar apagones frente a oscilaciones en la frecuencia, como la que se produjo ayer. En el momento del apagón, la mitad de la potencia nuclear estaba parada, en gran parte debido a los bajos precios de la electricidad y a una desproporcionada carga impositiva sobre las nucleares, que ha aumentado un 71% desde 2019, como explica @PwC_Spain: https://t.co/OmBavzBFIp
@RedElectricaREE, que depende del Gobierno, fue quien autorizó esas paradas, siendo por tanto responsable de que no hubiera suficiente potencia firme de generadores síncronos que podrían haber evitado el apagón. El informe financiero anual de Red Eléctrica, realizado por Ernst & Young, advierte del riesgo de apagones en España tras el cierre nuclear: «Mayor dificultad en la operación del sistema: reducción de potencia firme y capacidades de balance y mayor riesgo de incidentes en la operación que puedan afectar al suministro». Informe número 20462, fechado el 26/02/2025 y publicado por la Comisión Nacional del Mercado de Valores (CNMV): https://t.co/DHQdSYO42y
El Consejo General de Colegios Oficiales de Ingenieros Industriales, @CGCOII, también advirtió al Gobierno que cerrar las centrales nucleares aumentaría la inestabilidad del sistema por la pérdida de potencia firme, así como las emisiones de dióxido de carbono y el precio de la electricidad, debido a su sustitución por centrales de gas: https://t.co/7LXoHceVEg
Cuando las centrales nucleares se desconectan de la red, pasan a alimentarse de ella. Al producirse el apagón, arrancaron automáticamente sus generadores diésel, proporcionando energía a todos sus sistemas esenciales y de emergencia hasta que se recuperó el suministro eléctrico. Lo explica el @CSN_es en su nota de prensa nº 1: https://t.co/g1sNNZuzSp
El mix eléctrico español es equilibrado y cada tecnología cumple una función. Las centrales nucleares no están diseñadas para restablecer el servicio tras un apagón (tampoco lo están la eólica o la solar fotovoltaica), pero sí ayudan a evitarlos gracias a su aportación de inercia, como he explicado, algo que no hacen las renovables variables.
At Sesame, we believe in a future where computers are lifelike. Today we are unveiling an early glimpse of our expressive voice technology, highlighting our focus on lifelike interactions and our vision for all-day wearable voice companions. https://t.co/Edp8V8urgC