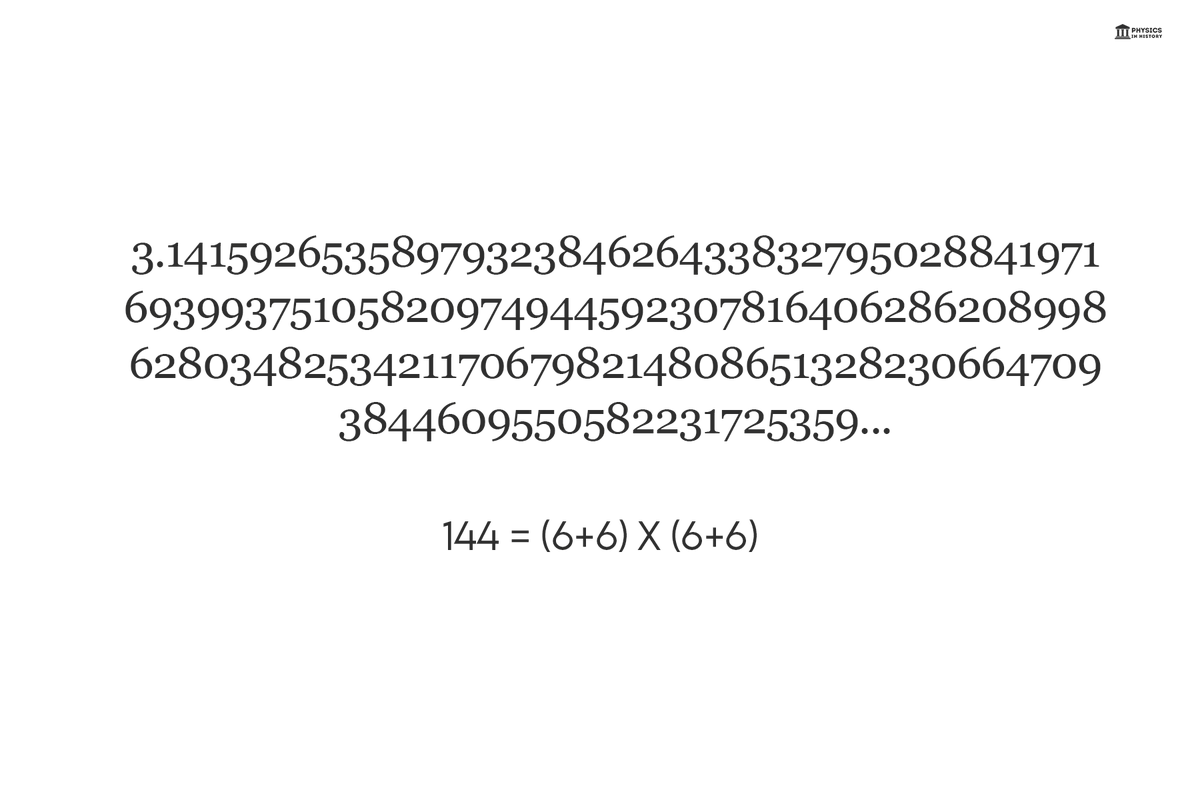// Self-Harness: Harnesses That Improve Themselves //
(bookmark this one)
Most of the agent scaffolds we rely on today are built once and remain frozen or mostly unchanged.
The harness, like the skills, needs to evolve with new models.
What if the scaffold rewrites itself?
This new work treats the harness, the prompts, tools, and control flow around the model as a learnable artifact that improves from its own runs rather than staying a fixed wrapper you hand-maintain.
The scaffolding becomes the part that compounds, run after run. If you run long-horizon agents, a self-modifying harness turns scaffold upkeep from manual work into something the system earns on its own.
Paper: https://t.co/byh1MP99xU
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
“Humankind will derive more good than harm from new discoveries.”
Pierre Curie discussed the dangers as well as the benefits of new discoveries in his Nobel Prize lecture #OnThisDay in 1905. Pierre Curie's full lecture: https://t.co/OJIlNbVkBM
84 years ago today, a pilot running out of fuel made a decision that won the Pacific War. Most Americans have never heard his name.
June 4, 1942. Six months after Pearl Harbor, Japan's navy is undefeated. Four of the carriers that burned Pearl, Akagi, Kaga, Soryu, and Hiryu, are steaming toward Midway to finish off the US Pacific Fleet.
At 7:52 AM, Wade McClusky launches from USS Enterprise leading 32 Dauntless dive bombers. Here's the detail nobody mentions: McClusky is a fighter pilot. He'd been given the air group weeks earlier and had barely flown a dive bomber in combat. Now he's leading every SBD the Enterprise has at the most important target in the Pacific.
9:20 AM. He arrives at the intercept point where the Japanese fleet is supposed to be.
Empty ocean. Nothing for miles.
The Japanese had turned. Nobody knew where. And now McClusky owns the worst math problem in naval aviation: his fuel is bleeding away, and every minute he keeps searching, he condemns more of his own pilots to ditch in open water where nobody will find them.
Doctrine is clear. Turn back.
McClusky keeps going. He works a search pattern, squeezing miles out of dying fuel tanks.
9:55 AM. Far below, a single Japanese destroyer is cutting a white scar across the ocean at flank speed. It's the Arashi, racing to rejoin the fleet after depth-charging the American submarine Nautilus. Think about that. A failed sub attack is about to give away the entire Japanese navy.
McClusky reads the wake like an arrow and follows it.
10:02 AM. The horizon fills with the entire Japanese strike force. Four carriers, their decks crammed with planes being refueled and rearmed. Fuel lines snaking everywhere. Bombs stacked in the open.
And here's the miracle: the sky above them is empty. Minutes earlier, American torpedo squadrons had attacked at sea level and been annihilated. Torpedo 8 lost all 15 planes. One survivor, Ensign George Gay, watched what came next while hiding under his seat cushion in the water. Those doomed pilots dragged every Japanese fighter down to the waves. The door upstairs was wide open.
10:22 AM. McClusky pushes over from 14,500 feet. Both squadrons follow him down onto Kaga. It's actually a mistake, doctrine said split the targets, but Lt. Dick Best catches it mid-dive, pulls out with two wingmen, and goes after Akagi alone. His single bomb pierces the flight deck into the packed hangar. It's enough.
By 10:28, Kaga, Akagi, and Soryu, the third hit simultaneously by Yorktown's bombers, are floating infernos. Six minutes. Three carriers that attacked Pearl Harbor, gone. Hiryu follows them to the bottom that evening.
The cost of McClusky's gamble was real. Many Enterprise bombers never made it home, some shot down, others swallowed by the sea when their tanks ran dry. McClusky himself was jumped by two Zeros on the way out, took five bullets through his shoulder, and still flew his shot-up Dauntless back to the Enterprise.
Admiral Nimitz said McClusky's decision "decided the fate of our carrier task force and our forces at Midway." Japan never won another major battle.
One borrowed pilot. One destroyer's wake. One choice to keep flying when every gauge said go home.
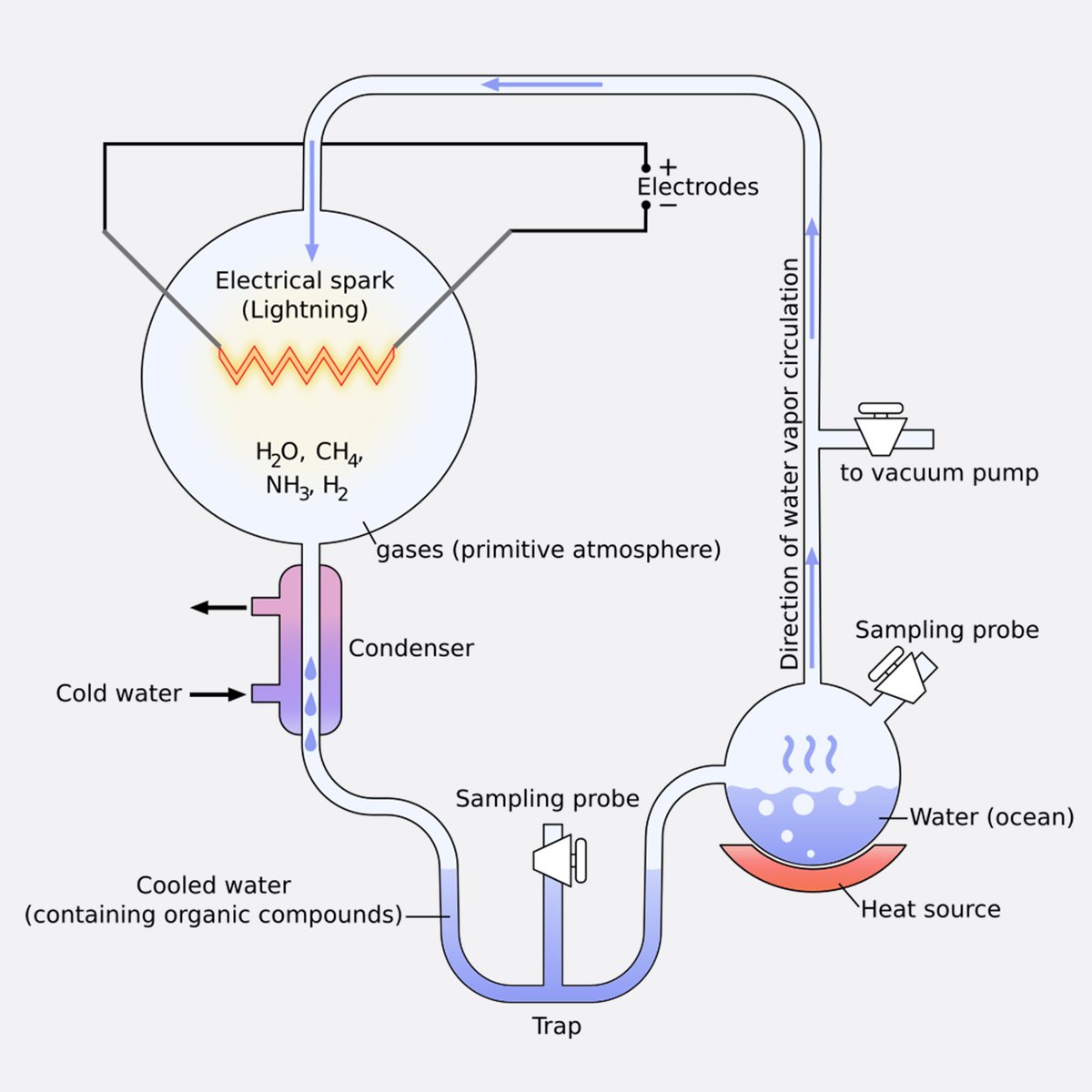
The Miller-Urey experiment was a groundbreaking scientific study conducted in 1952 by Stanley Miller under the supervision of Harold Urey at the University of Chicago. The experiment was designed to test the chemical origins of life under conditions thought to resemble those of the early Earth.
The setup for the experiment involved a closed system containing a mixture of gases that were believed to be present in Earth's early atmosphere, such as methane, ammonia, hydrogen, and water vapor. This mixture was subjected to continuous electrical sparks to simulate lightning, a common occurrence in Earth's primordial atmospheric conditions. The apparatus also included a water flask to mimic the ocean, which was heated to induce evaporation, and a cooling system to condense the vapor, simulating rain. After running the experiment for about a week, Miller analyzed the substances that had formed in the water and found that several organic compounds had been synthesized, including amino acids, which are the building blocks of proteins. This was significant because it demonstrated that organic compounds necessary for life could be synthesized from simpler inorganic compounds under conditions that might have been present on the early Earth.
The experiment provided strong support for the hypothesis that life on Earth could have arisen through natural chemical processes from nonliving matter, contributing substantially to the field of abiogenesis—the study of how biological life could arise from inorganic matter.
Most people use Claude Code like a chat box.
It's actually a 7-layer system. Each layer compounds on the one below it.
The bottom layer (CLAUDE. md) is where 90% of users stop. The top layer (Subagents) is where the real leverage starts.
Here's the full stack, from foundation to advanced:
→ CLAUDE. md: context files Claude reads every session. Your conventions, your stack, your gotchas. Write it once.
→ Hooks: scripts that fire at key moments. A stop hook can review what happened and propose updates to your CLAUDE. md automatically.
→ Skills: on-demand expertise that loads only when relevant. Security review skill activates during audits. Doc skill activates when you change code. Nothing bloats your session.
→ Plugins: package your skills, hooks, and MCP configs into one installable bundle. New team members get the full setup on day one.
→ LSP: language server protocol gives Claude symbol-level precision. It follows function definitions across files instead of pattern-matching on text.
→ MCP Servers: connect Claude to internal tools, databases, ticketing systems, and APIs it can't reach on its own.
→ Subagents: spin up a separate Claude instance to explore a subsystem while your main agent keeps editing. Parallel work, isolated context.
Most guides teach you the chat interface. The harness is where the real configuration happens.
Anthropic published the full breakdown this week. The teams getting the most out of Claude Code aren't writing better prompts. They're building better harnesses.
Follow @godofprompt for more breakdowns like this.
Just released my new /lesson-generator skill.
Use it with your agent to learn anything:
- generate lessons/courses on any topic
- include nano-banana images with my /image-generator skill
- present the course as an HTML artifact
And it's also available to use in our academy.
SpaceX: "The Starlink team is exploring using Starlink to enable high bankdwith connectivity around the Moon; Traditionally, deep space comms have relied on radio frequency transmission. This new design would use lasers to relay data back to Earth. Deploying that technology around the Moon could connect it with hundreds of terabits of capacity. This could enable Gigabit connectivity anywhere on the lunar surface."
🤯
⚡ NASA releases closest image ever taken of Jupiter.
This is a real photograph of Jupiter, not a painting.
What looks like delicate brushstrokes are actually Earth-sized cyclones captured by the Juno spacecraft from just 4,400 miles above the gas giant’s surface.
Cool idea from Nous Research.
What if you could speed up long-context pretraining with a subquadratic wrapper that you remove before deployment?
That is the idea behind Lighthouse Attention.
The method wraps ordinary SDPA with a hierarchical, gradient-free selection layer that compresses and decompresses queries, keys, and values symmetrically, preserving left-to-right causality.
Crucially, it can be removed near the end of training in a short recovery phase, so the deployed model still runs vanilla attention with no architectural cost at inference.
Preliminary LLM experiments report faster total training time and lower final loss than full-attention baselines.
Why does it matter?
Most efficient-attention work either changes the deployment-time architecture or pays a quality tax to do so. A training-only wrapper that survives a clean recovery phase sidesteps both. If it scales, this becomes an important training-time speedup for long-context pretraining.
Paper: https://t.co/9g5Ldnb1rV
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
The sum of the first 144 digits in the sequence of π equals 666, a figure often associated with "the number of the Beast". Interestingly,
144 = (6+6) x (6+6)
Instead of watching a movie, Learn how Andrej Karpathy (@karpathy), OpenAI co-founder, ex-Tesla AI, "vibe coding" creator explains why Claude Skills, MCP servers, and AI agents are past the hype and are now the new baseline for building in just 262 minutes ↓
FREE Math Book.
"Calculus Made Easy," originally published in 1910 by Thompson, is a beloved classic that demystifies calculus with the playful motto: "What one fool can do, another can." He wrote the book to make the subject accessible and fun for beginners, using plain English, everyday analogies, and a light touch: famously declaring that the mysterious "d" in differentials is just "a little bit of x." It has inspired generations (including Richard Feynman and Martin Gardner) and remains in print over a century later precisely because it proves calculus doesn't have to be intimidating.
The book focuses on intuition and key concepts rather than intricate formulas, using a common sense approach with simple language and examples. It explains fundamental ideas like differentiation and integration for all to understand.
Link: https://t.co/pG9vK1Ixq8
8 RAG architectures for AI Engineers:
(explained with usage)
1) Naive RAG
- Retrieves documents purely based on vector similarity between the query embedding and stored embeddings.
- Works best for simple, fact-based queries where direct semantic matching suffices.
2) Multimodal RAG
- Handles multiple data types (text, images, audio, etc.) by embedding and retrieving across modalities.
- Ideal for cross-modal retrieval tasks like answering a text query with both text and image context.
3) HyDE (Hypothetical Document Embeddings)
- Queries are not semantically similar to documents.
- This technique generates a hypothetical answer document from the query before retrieval.
- Uses this generated document’s embedding to find more relevant real documents.
4) Corrective RAG
- Validates retrieved results by comparing them against trusted sources (e.g., web search).
- Ensures up-to-date and accurate information, filtering or correcting retrieved content before passing to the LLM.
5) Graph RAG
- Converts retrieved content into a knowledge graph to capture relationships and entities.
- Enhances reasoning by providing structured context alongside raw text to the LLM.
6) Hybrid RAG
- Combines dense vector retrieval with graph-based retrieval in a single pipeline.
- Useful when the task requires both unstructured text and structured relational data for richer answers.
7) Adaptive RAG
- Dynamically decides if a query requires a simple direct retrieval or a multi-step reasoning chain.
- Breaks complex queries into smaller sub-queries for better coverage and accuracy.
8) Agentic RAG
- Uses AI agents with planning, reasoning (ReAct, CoT), and memory to orchestrate retrieval from multiple sources.
- Best suited for complex workflows that require tool use, external APIs, or combining multiple RAG techniques.
👉 Over to you: Which RAG architecture do you use the most?
_____
Share this with your network if you found this insightful ♻️
Find me → @akshay_pachaar ✔️
For more insights and tutorials on LLMs, AI Agents, and Machine Learning!