What if an LLM could update its own weights?
Meet SEAL🦭: a framework where LLMs generate their own training data (self-edits) to update their weights in response to new inputs.
Self-editing is learned via RL, using the updated model’s downstream performance as reward.
🤖 We introduce Ambient Diffusion Policy, a simple and principled method for training policies with suboptimal data in robotics.
Suboptimal data is everywhere in robotics…
❌ Data filtering is wasteful
❌ Co-training learns both good and bad features
✅ Ambient Diffusion Policy selectively learns useful features via noise-dependent data usage
👇🧵(1/5)
World-Action Models (WAMs) have become the second dominant recipe for robot foundation models, next to classical VLAs.
So where do they come from, and how do they compare vs VLAs?
I wrote an small overview of the WAM landscape, with some personal takes:
https://t.co/6S4gH9tWTt
Your RL post-training may be sabotaging your LLM’s test-time scaling!
Conventional RL pretends that you can collapse all reward signals *upfront* into a single *scalar reward*.
We introduce Vector Policy Optimization (VPO), which natively maximizes *vector-valued* rewards, boosting test time search performance, even on the original scalar.
The computational abstractions humans developed are great for building architectures, however they’re not necessarily the right abstractions for kernels. Han shows why 🔥
LLM training is built on fast MatMuls. But many surrounding ops still run as memory-bound kernels.
CODA reparameterizes them to hide in the matmul’s shadow, fused into its epilogue before results leave the chip.
Bonus: LLMs can write fast CODA kernels too (approaching SoLs).
Pulkit and I had many chats since the start of my PhD of how models should intimately understand force and physics. I always thought this is the right technical bet to make and now Pulkit + Team is paving the path to bring this to life!
Eka means unity -- “one,” in Sanskrit and “first” in Finnish.
We’re building intelligence for the physical world in its native language: forces.
Until now, robotics faced a tradeoff — generality or speed. The real world requires both. Robotics also faced a data problem.
Our Vision–Force–Action (VFA) model — the first of its kind — breaks the generality-speed tradeoff and the data barrier.
It's a new foundation uniting performance, generality, and safety for putting capable robots in everyone's hands.
Today, I am excited to share our journey of pushing robots beyond human limits.
Today, dexterity becomes scalable.
Today, I welcome you to the Era of Eka.
Co-founded with @haarnoja, and so thrilled and grateful to be working with a dream team at @EkaRobotics.
Learn more: https://t.co/QYQ6x2Etyi
Big vote for animals this week. On Thursday, the House will likely vote on whether to strike the Save Our Bacon Act from the farm bill.
Rep. Luna (R-FL) is leading a bipartisan amendment to strike the Act, which would wipe out state laws banning the sale of pork from crated pigs.
Pork industry lobbyists are already hard at work against her. They're counting on no one speaking up for the pigs. Prove them wrong.
Call the House at 202-224-3121. Give them your zip code and they'll connect you to your member's office. Ask them to vote YES on the Luna Amendment to remove the Save Our Bacon Act from the farm bill.
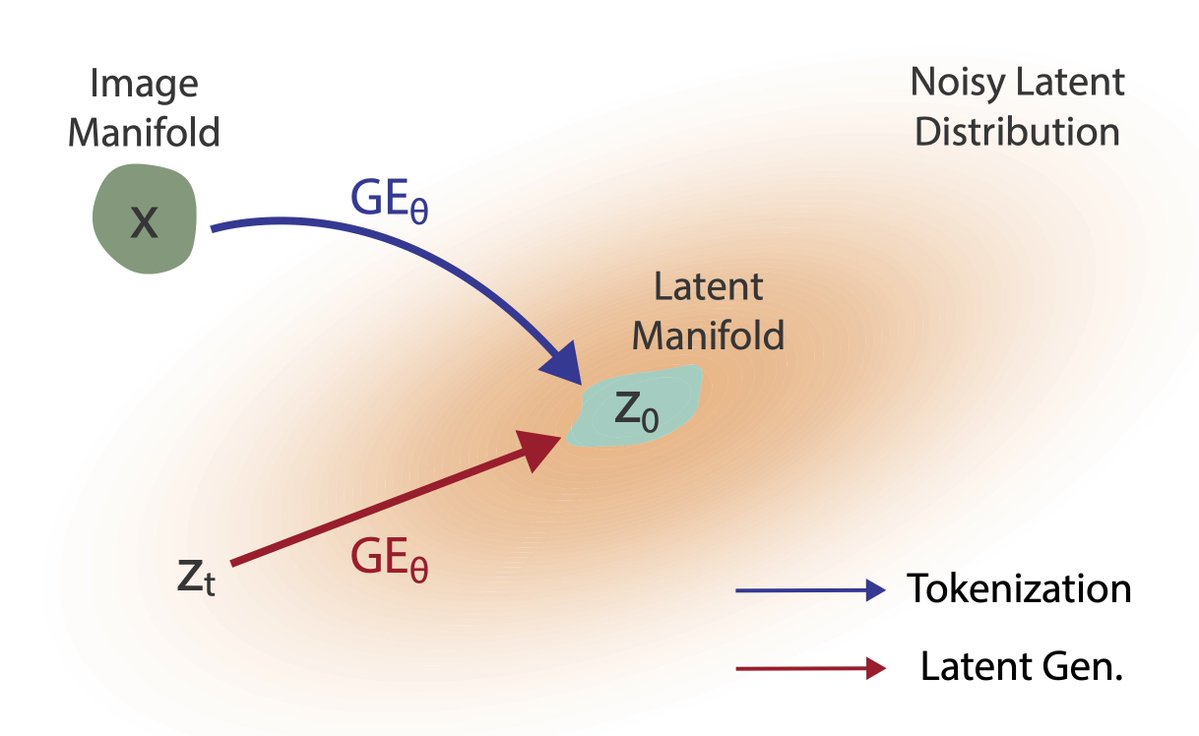
Tokenization & Generation power Large Models. But are they really separate?
Tokenization=Generation under strong observability
UNITE: An end-to-end training framework where one shared Generative Encoder (GE) performs both token. & latent denoising
Paper: https://t.co/8idMdy123h
Introducing M²RNN: Non-Linear RNNs with Matrix-Valued States for Scalable Language Modeling
We bring back non-linear recurrence to language modeling and show it's been held back by small state sizes, not by non-linearity itself.
📄 Paper: https://t.co/AS8e2tNrRa
💻 Code: https://t.co/LMvBcI22Du
🤗 Models: https://t.co/NCmjrpNriq
Similar thought.
Next-token prediction feels statistical: perplexity / shannon-entropy minimization. But creativity / science may require: finding compact generative structures, then exploring in that space. Closer to algorithmic complexity? More Kolmogorov than Shannon.
Hard problems require more than bigger models, they require effective exploration at test time. 💡
@aviral_kumar2 will present new approaches for training LMs to scale test-time exploration, including solving IMO-level math problems. 🏅
🗓️ March 19, 4pm ET
@scaleml
Very cool work by Seungwook! Would be interesting to see if the neural cellular automata pre training results in additional capabilities that natural language training alone can’t produce.
Can language models learn useful priors without ever seeing language?
We pre-pre-train transformers on neural cellular automata — fully synthetic, zero language. This improves language modeling by up to 6%, speeds up convergence by 40%, and strengthens downstream reasoning.
Surprisingly, it even beats pre-pre-training on natural text!
Blog: https://t.co/Pni0RsIcxL
(1/n)
As context windows grow 📈, continual learning matters more!
@tianyuanzhang99 will present how to scale test-time training for effectively infinite context ♾
🗓️ Feb 19, 3pm ET
@scaleml
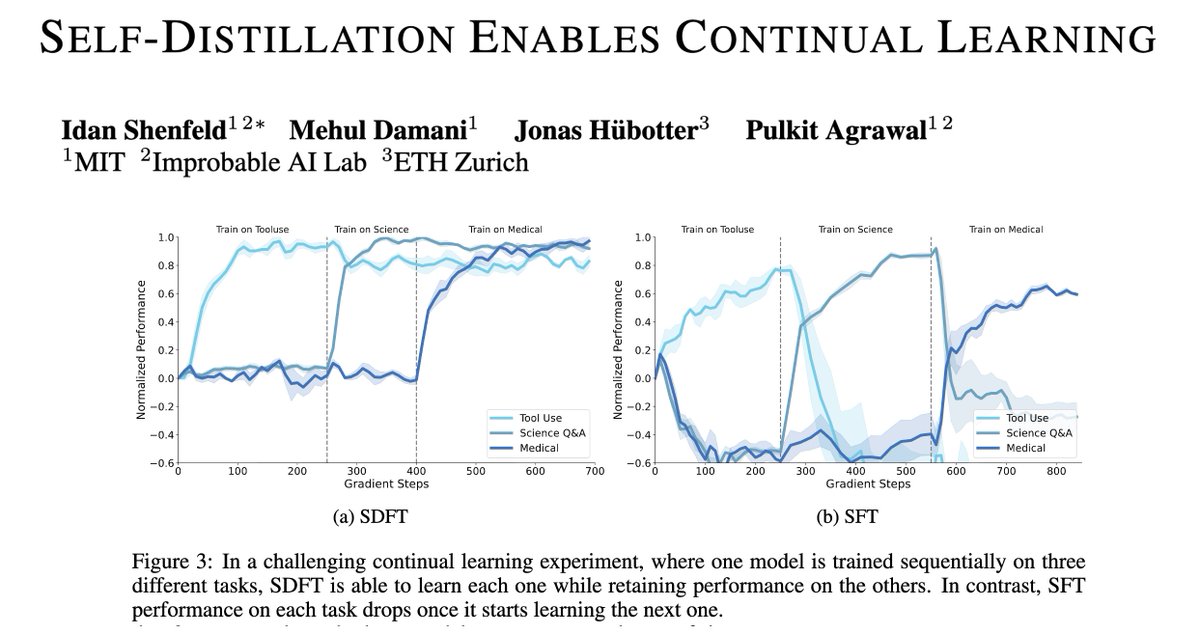
People keep saying 2026 will be the year of continual learning.
But there are still major technical challenges to making it a reality.
Today we take the next step towards that goal — a new on-policy learning algorithm, suitable for continual learning!
(1/n)
RL for reasoning often rely on verifiers — great for math, but tricky for creative writing or open-ended research.
Meet RARO: a new paradigm that teaches LLMs to reason via adversarial games instead of verification.
No verifiers. No environments. Just demonstrations. 🧵👇
Next Tuesday, @shannonzshen will present hybrid chain-of-thought, a method that mixes latent and discrete tokens during decoding 🔥
🗓️ Nov 25, 3pm ET
@scaleml
Why do deep learning optimizers make progress even in the edge-of-stability regime? 🤔
@alex_damian_ will present theory that can describe the dynamics of optimization in this regime!
🗓️ Nov 17, 3pm ET
@scaleml
Everyone’s talking about Kimi K2 Thinking and its impressive performance.
No full report yet, but judging from Kimi K2\1.5 reports, it likely uses Policy Mirror Descent - an RL trick that’s quietly becoming standard in frontier labs.
Let’s break down what it is:
in our new post, we walk through great prior work from @agarwl_ & the @Alibaba_Qwen team exploring on-policy distillation using an open source recipe: you can run our experiments on Tinker today!
https://t.co/7nkW8YgT7K
i'm especially excited by the use of on-policy distillation to enable new "test-time training" personalization methods, allow the model to learn new domain knowledge without regressing on post-training capabilities
Very interest! We could use RLMs for complex reasoning problems where models are solving sub-problems in parallel unlocking a new dimension of scaling!
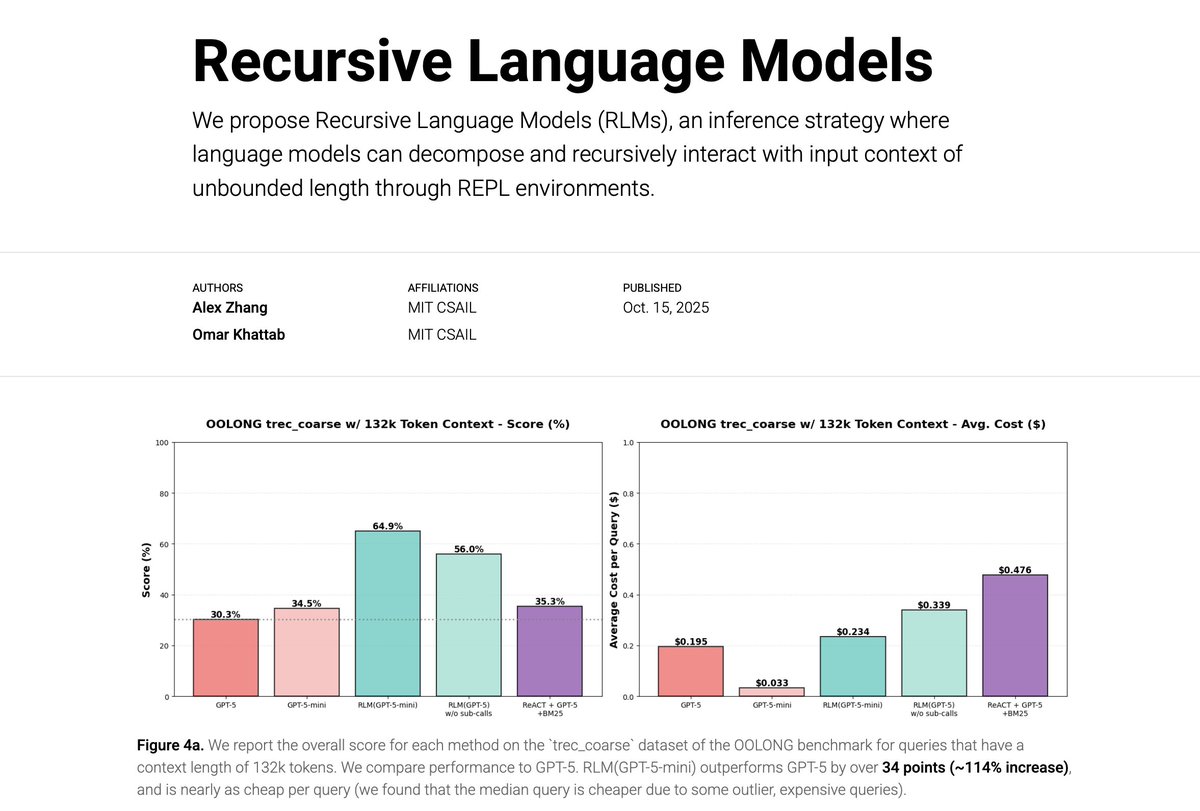
What if scaling the context windows of frontier LLMs is much easier than it sounds?
We’re excited to share our work on Recursive Language Models (RLMs). A new inference strategy where LLMs can decompose and recursively interact with input prompts of seemingly unbounded length, as a REPL environment.
On the OOLONG benchmark, RLMs with GPT-5-mini outperforms GPT-5 by over 110% gains (more than double!) on 132k-token sequences and is cheaper to query on average.
On the BrowseComp-Plus benchmark, RLMs with GPT-5 can take in 10M+ tokens as their “prompt” and answer highly compositional queries without degradation and even better than explicit indexing/retrieval.
We link our blogpost, (still very early!) experiments, and discussion below.
VLAs have become the fastest-growing subfield in robot learning. So where are we now?
After reviewing ICLR 2026 submissions and conversations at CoRL, I wrote an overview of the current state of VLA research with some personal takes:
https://t.co/OMMdB1MHtS