Excited to share last summer's work at Google Research!
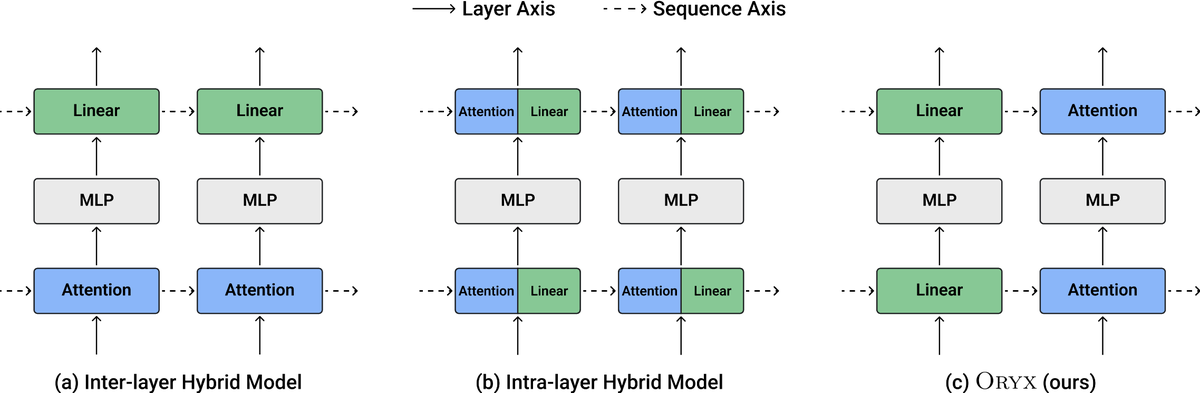
Most hybrid models today are static: each token sees the same interleaved pattern of your favorite linear model and attention.
Oryx instead varies the model used across the sequence through shared representations.
1/
We are taking a big step towards scaling LLMs that can unlearn on demand.
Cleanly deleting data from LLMs has proven impossible: training entangles every source in shared weights.
NULLs (Natively Unlearnable LLMs) escapes this, keeping millions of sources individually deletable in a 1B-parameter model trained on web data. (1/8)
1/ To retain post-training capabilities after further fine-tuning, mix that data into pretraining.
The effect can be invisible until fine-tuning begins; early exposure may not help post-training performance, but it changes what persists.
How a model learns a task matters.
New paper! https://t.co/1ETmDt0ZB8
This tackles a puzzle we found during the training of Olmo 3: how could two models with nearly identical short-context performance (and trained on the same data!) behave completely differently after long context extension?
🤖 What would LMArena for robotics look like?
Introducing RobotArena ∞
We turn real videos into simulated environments and evaluate robot policies at scale using VLM scoring + human preferences
A scalable benchmark for robot generalists
🔗 https://t.co/E74fjWvlG3
Details 🧵👇
Models are typically specialized to new domains by finetuning on small, high-quality datasets.
We find that repeating the same dataset 10–50× starting from pretraining leads to substantially better downstream performance, in some cases outperforming larger models. 🧵
1/
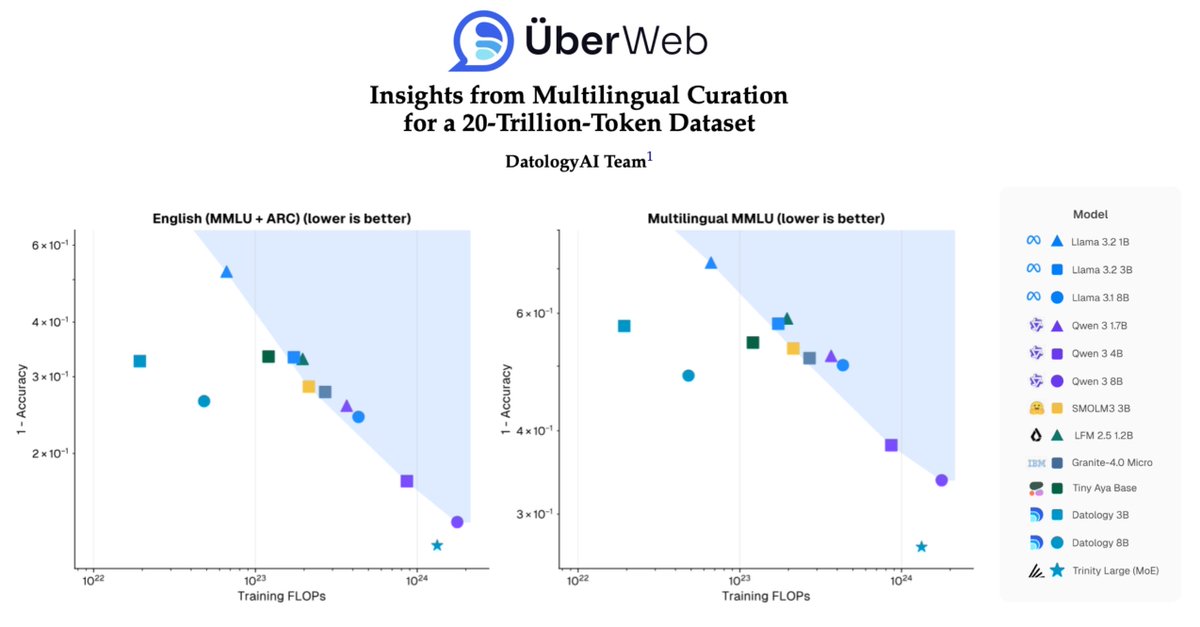
We’ve released a report on our work on multilingual data curation @datologyai.
tl;dr: We shift the performance–compute Pareto frontier for multilingual models. Entirely by improving data quality and composition.
arxiv: https://t.co/bLv8IySa8G
blog: https://t.co/sczLujHj42
🌎Making your model multilingual doesn't have to sacrifice English performance—you just need better data.
@agcrnz, @RicardoMonti9, and I have been working on curating the best possible multilingual data with the team @datologyai, and it works! Check out the results 👇
1/ People often think better multilingual models must come at the cost of English performance. Not true. The constraint isn’t capacity, it’s data quality, and we can fix it.
Today @datologyAI shares ÜberWeb: a year of multilingual curation lessons, scaled to 20T+ tokens.
Can LLMs accurately aggregate information over long, information-dense texts? Not yet…
We introduce Oolong, a dataset of simple-to-verify information aggregation questions over long inputs. No model achieves >50% accuracy at 128K on Oolong!
@universeinanegg@yoavgo Training objective mismatch in post training : Language models being unable to output ‘I don’t know’- https://t.co/WauaH9HuiZ; Very vaguely - the model just picks the closest embedding. This explains the repetition and retrying until the token budget runs out.
I'll be joining the faculty @JohnsHopkins late next year as a tenure-track assistant professor in @JHUCompSci
Looking for PhD students to join me tackling fun problems in robot manipulation, learning from human data, understanding+predicting physical interactions, and beyond!
There’s been a lot of work on unlearning in LLMs, trying to erase memorization without hurting capabilities — but we haven’t seen much success.
❓What if unlearning is actually doomed from the start?
👇This thread explains why and how *memorization sinks* offer a new way forward.
LLMs lose diversity after RL post-training, and this hurts test-time scaling & creativity.
Why does this collapse happen, and how can we fix it?
Our new work introduces:
🔍 RL as Sampling (analysis)
🗺️ Outcome-based Exploration (intervention)
[1/n]
Outcome-based Exploration for LLM Reasoning
Mitigating reduction of diversity due to RL involves using UCB on answers. There are many studies on this recently (https://t.co/ez9BWWS2lB) and it could be important especially for creative tasks.
1/So much of privacy research is designing post-hoc methods to make models mem. free.
It’s time we turn that around with architectural changes. Excited to add Memorization Sinks to the transformer architecture this #ICML2025 to isolate memorization during LLM training🧵
@abitha___ will be presenting our work on training language models to predict further into the future beyond the next token and the benefits this objective brings.
https://t.co/NkbkkuczfZ



































![yus167's tweet photo. LLMs lose diversity after RL post-training, and this hurts test-time scaling & creativity.
Why does this collapse happen, and how can we fix it?
Our new work introduces:
🔍 RL as Sampling (analysis)
🗺️ Outcome-based Exploration (intervention)
[1/n] https://t.co/N1YbdjFWeS](https://pbs.twimg.com/media/G0ksIpNWQAAW0Mf.jpg)





















