This one has been a long time coming: today we’re introducing MEM, an approach for giving VLAs short-term and long-term memory.
Memory is such an obvious capability, but adding it isn’t easy (most VLAs today are memory-less). A short thread on challenges, solutions, and the new capabilities MEM unlocks for us.
These choices are actually a bit orthogonal. Long vs short episodes mostly depends on your teleop success rate on long episodes --> if you frequently make mistakes in teleop, it's better to chunk a long task into shorter episodes.
Re one task for everything vs subtask conditioning: the latter can potentially give you more generalization (see eg pi07 results), but requires training a high-level policy that picks subtasks at inference time, which can introduce one more source of errors. So I would suggest starting with simple one-task-for-all as baseline, and only after try the HL/LL design!
Excited to be in Rio this week to present RETAIN (w/ @zhiyuan_zhou_ , @ajwagenmaker, @KarlPertsch, and @svlevine) at #ICLR2026! 🇧🇷
Saturday 10:30 AM – 1:00 PM at P3-#1208.
Project Page: https://t.co/L8zoMKzUK1
https://t.co/y8GW4qhEeC.
Happy to share some new results! π0.7 comes with memory, and algorithmic advances to pull out more performance and generalization from diverse training data! Check it out!
Our newest model, π0.7, has some interesting emergent capabilities: it can control a new robot to fold shirts for which we had no shirt folding data, figure out how to use an appliance with language-based coaching, and perform a wide range of dexterous tasks all in one model!
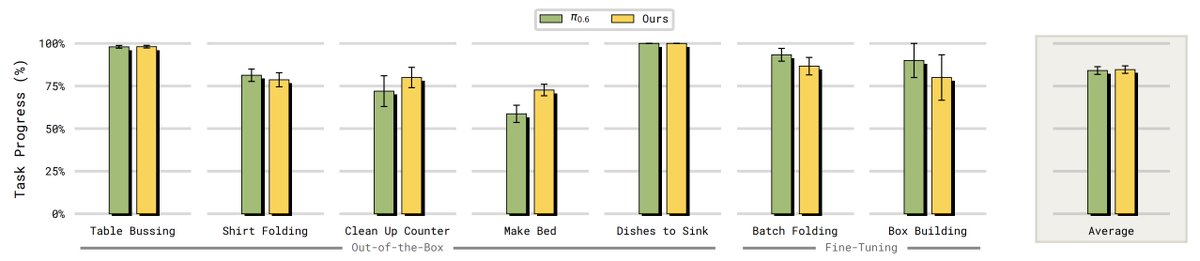
We developed an RL method for fine-tuning our models for precise tasks in just a few hours or even minutes. Instead of training the whole model, we add an “RL token” output to π-0.6, our latest model, which is used by a tiny actor and critic to learn quickly with RL.
Jup, tho off the shelf VLMs today are often not well suited as HL policies for more complex tasks (many papers have shown this, they struggle with finegrained interaction understanding, failures etc) and robot fine tuned models so far need to be taught to remember explicitly. Agree tho that in the future this will hopefully be bridged
Many real-world tasks require memory to be successful. Yet, most robots don’t have any form of memory. Today, we are going to change that. We developed a system called MEM that introduces memory into VLAs on multiple scales
We equipped PI policies with memory!
And taught our robots to do long-horizon real world tasks such as preparing the items for a recipe, cooking a grilled cheese and cleaning the kitchen!
We’ve developed a memory system for our models that provides both short-term visual memory and long-term semantic memory.
Our approach allows us to train robots to perform long and complex tasks, like cleaning up a kitchen or preparing a grilled cheese sandwich from scratch 👇
This was one of the longest-running research projects at pi — adding memory to your models stretches all parts of your infra and needs innovation on the whole stack.
The project started as @HomerWalke's internship project with @DannyDriess, but had lots of help from countless people at pi to get over the finish line. Special shoutout to @marceltornev who worked tirelessly to teach our models the long-horizon behaviors you saw in the videos above!
For more details, check out our blog & paper: https://t.co/9gCOS8sfiV
This one has been a long time coming: today we’re introducing MEM, an approach for giving VLAs short-term and long-term memory.
Memory is such an obvious capability, but adding it isn’t easy (most VLAs today are memory-less). A short thread on challenges, solutions, and the new capabilities MEM unlocks for us.
Finally, many prior works have reported that policies get *worse* on dexterous tasks when adding memory (because of spurious correlations, causal confusion etc). We find that by equipping pi06 with MEM and training it on our most diverse data mix, we can match pi06 performance on tasks that do not require memory (while clearly outperforming on memory tasks).
This is IMO one of the biggest results here: we have a recipe for adding memory to VLAs without significant tradeoffs, both in terms of latency and performance!
🧵(6) DROID Eval
CoVer-VLA achieves 14% gains in task progress and 9% in success rate on the challenging red-team PolaRiS benchmark. In the pan cleaning task, π₀.₅ shows incorrect intent, grasping the pan handle. In contrast, CoVer-VLA correctly uses sponge to scrub the pan.
Very exciting to see first steps of our models doing useful things in the world!
Thanks to Ultra and Weave for being great partners in these deployments!
General-purpose AI models are behind some of the most exciting applications we now can't live without. We envision that an analogous “physical intelligence layer” built with models like π0.6 will similarly spur a new wave of applications for the physical world.
We’ve recently begun working with a handful of companies that have deployed their robots to do real-world, useful things.
https://t.co/udVO9fV0PH