introducing Dex, the first agent system with full operational context and a self-updating knowledge base
karpathy's llm knowledge base on steroids
Dex ingests raw events from every app in your workspace. every slack message, email, meeting, browser session, task update compounds into one living knowledge base. background agents continuously monitor and enhance it while you sleep so your agents get smarter every day
try now at joindex [dot] com
Introducing Dex: the self-driving workspace for operators.
Dex is the first agent system with full operational context and a self-updating knowledge base.
Every datapoint from your workspace is ingested, synced, and structured into compounding context for agents to take action.
Comment "DEX" or tag @dexbythirdlayer access.
First 1,000 sign-ups get 7 days free.
After, join our rolling waitlist.
Sign up at joindex [dot] com for a fun surprise.
How dex works (threads)
four weeks before YC demo day, we killed what we'd been building. it had a 50% CMO response rate, but we couldn’t stop thinking about an idea that nobody had a name for yet…
10,000+ downloads later, that idea is Dex.
speaking at a panel moderated by @BainCapVC this thursday on predictive + proactive interfaces with @kneureither, @justoutquan, and Jenning Chen. rsvp in comments
Someone is going to build a worldclass “Brain” for enterprises & make a stupid amount of money.
Why? As @da_fant said, “coding w ai is solved bc all context is in the git repo. knowledge work is difficult bc context is spread out. an ai system that creates a git repo w all context for a knowledge worker will be able to 100% automate the work.”
When companies talk about being data ready for AI, this is what they’re implicitly saying.
Engineering has been prepared for this moment for a long time because of the deterministic nature of code, the centralization/versioning of data (read: GitHub), and AI tools that are largely build by engineers for engineers.
But for the rest of white collar work, there’s a TON of catching up to do to properly harness the power of the technology.
The big challenge here, and why no one has truly cracked the code for "an ai system that creates a git repo w all context for a knowledge worker" is because unlike code, most knowledge is 1) distributed, 2) unstructured, and 3) unverifiable.
It's distributed: transcripts live in Granola. Documents in Notion. Customer Data in Hubspot. ERP. Emails. Slack messages. Random spreadsheets. SOP docs. Etc. Etc.
Building an ingestion engine that connects to all of your disparate data sources and auto-updates based on the shelf-life of the data is the first, and frankly, easiest step of the process.
Next, it's unstructured: let's say I want to create a proposal for a potential client. To nail the proposal, I want it to pull important information from a variety of sources. The specific asks & background from our initial sales call. Previous proposals to anchor ourselves to a proven format. And completed sprint boards from Linear, so the pricing & timeline in the document is grounded in truth.
Whether it's a thoughtful filesystem (a la Obsidian) or an OpenClaw-esque memory structure, the brain needs to be great at self-organizing in a thoughtful schema. This is very hard, especially if you want to build a generalizable brain that can be shaped to an array of different enterprises.
And finally, most knowledge is unverifiable: writing a function, running a unit test, and seeing if the code works is easy. It works or it doesn't. Using AI to accelerate your content creation process is highly subjective. What is a good/bad idea? Is the content in your voice or not? Does it feel like slop or novel? Answering these questions are both difficult and non-verifiable.
That same system described above doesn't just have to be great at organizing & forming coherent relationships, but it also has to be great at self-improving based on feedback from the user. Memory systems (like those introduced by OpenClaw) are great to a point, but as you scale the corpus of data within your company's brain, things like compaction and cleaning become wildly important to avoid the needle in the haystack problem.
Someone is going to figure out how to solve this problem, and when they do, not only will they make a shit ton of money, but they'll be robinhood for knowledge workers, enabling non-engineers to enjoy the sort of leverage that only technical folks have felt for the last few years.
introducing Dex, the first agent system with full operational context and a self-updating knowledge base
karpathy's llm knowledge base on steroids
Dex ingests raw events from every app in your workspace. every slack message, email, meeting, browser session, task update compounds into one living knowledge base. background agents continuously monitor and enhance it while you sleep so your agents get smarter every day
try now at joindex [dot] com
Introducing Dex: the self-driving workspace for operators.
Dex is the first agent system with full operational context and a self-updating knowledge base.
Every datapoint from your workspace is ingested, synced, and structured into compounding context for agents to take action.
Comment "DEX" or tag @dexbythirdlayer access.
First 1,000 sign-ups get 7 days free.
After, join our rolling waitlist.
Sign up at joindex [dot] com for a fun surprise.
How dex works (threads)
Introducing Dex: the self-driving workspace for operators.
Dex is the first agent system with full operational context and a self-updating knowledge base.
Every datapoint from your workspace is ingested, synced, and structured into compounding context for agents to take action.
Comment "DEX" or tag @dexbythirdlayer access.
First 1,000 sign-ups get 7 days free.
After, join our rolling waitlist.
Sign up at joindex [dot] com for a fun surprise.
How dex works (threads)
whoa this is actually fucking sick, a self-improving ai you can use yourself right now (for any task)
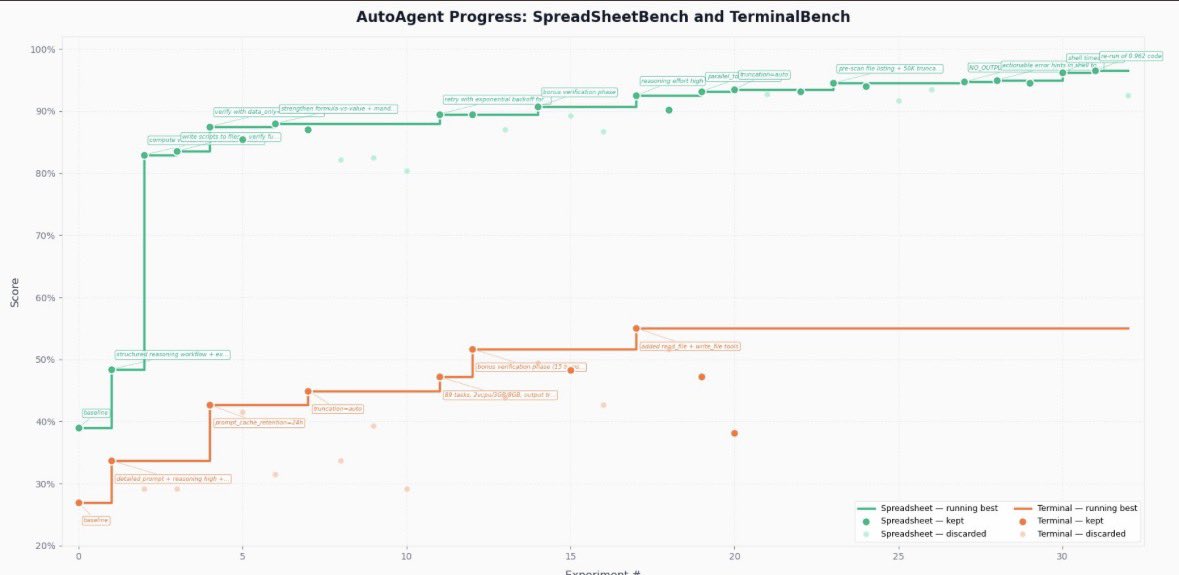
dude created an ai agent that autonomously upgraded itself to #1 across multiple domains in < 24 hours…. then open sourced the entire thing
but here’s why it actually works:
- agents fucking suck, not because of the model, because of their harness (tools, system prompts etc)
- Auto agent creates a Meta agent that tweaks your agents harness, runs tests, improves it again - until it’s #1 at its goal
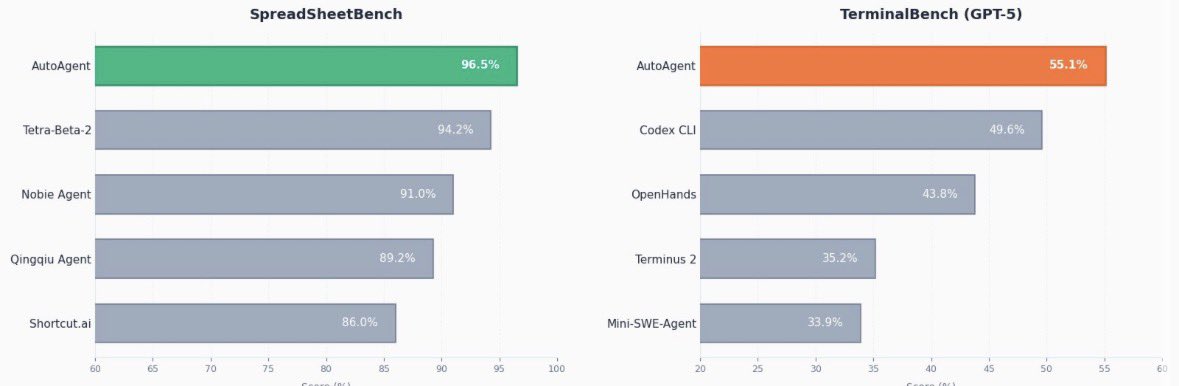
- best part: you can set this up for ANY task. in this article he uses it for terminal bench (code) and spreadsheets (financial modelling) - it topped rankings for both :)
- secret sauce: he used THE SAME MODEL to evaluate the agent - claude managing claude = better understanding of why it failed and how to improve it
humans were the fucking bottleneck and this not only saves you a load of time, it’s just a better way to train them for domain specific tasks
seriously check it out
Neat project + post. This line of work is making me think of harnesses as transient reasoning scaffolds. Reminds me of earlier “XoT as intermediate structure” work (SatLM, Program-of-Thought, Tree-of-Thought, etc.), but now in an agentic regime with much more room for optimization.
I keep wondering about this idea of meta-optimization: how broad should we expect that optimization to get? Should a meta-agent mostly do local search over prompts/tools/hyperparameters, or should it sometimes pursue riskier, longer-horizon interventions? Wilder example, but if we pointed something like AutoResearch at "coding", should we expect it to rediscover higher-level workflows or abstractions akin to Claude Code?
My guess is that “meta” agents, or even deeper recursive optimizers, will tend to favor local improvements over sweeping pipeline redesigns. Very targeted and precise changes, even when broader features might help in the long run. Measuring that “meta-scope”, where do agents spend their time optimizing these harnesses, seems worth studying.
imo the meta-optimization + emergent features are the future of agent engineering. you don't know which concepts the model actually operates on (reminds me of polysemantic neurons), so it ends up improving its harness in ways you'd never hand-engineer
pretty cool huh
point AutoAgent at a task domain with evals.
24 hours later it has domain-specific tooling, verification loops, and orchestration logic.
all discovered autonomously.