Thrilled to see our partner @CancerSupportHQ at ASCO this year! We’re also excited to join the oncology community in Chicago and connect around what’s next in cancer care.
Cancer Support Community will be at ASCO next week, joining patient advocates, researchers, and community partners to elevate the voices and needs of people impacted by cancer.
We look forward to seeing you there!
We’re proud to partner with @thesnowleague on Crash Patch, a first-of-its-kind helmet sticker designed to turn red when an athlete or rider may have taken a major hit.
Built to respond to impacts of 75G or more, Crash Patch helps identify potentially dangerous blows in real time.
Thank you @fastcompany for highlighting its potential.
https://t.co/seBvnpigzA
AI that actually works in pharma? Yes✅
Featured in @MMMnews: Klick Guardrail is helping teams ask smarter MLR questions earlier.
“Klick Guardrail is a glass-box AI tool, so it shows its decision-making and makes it easy to validate responses.” says BJ Jones, NewAmsterdam Pharma & Klick Prize Jury Member.
Read the top AI tools shaping the industry: https://t.co/2kdhqoCOzc
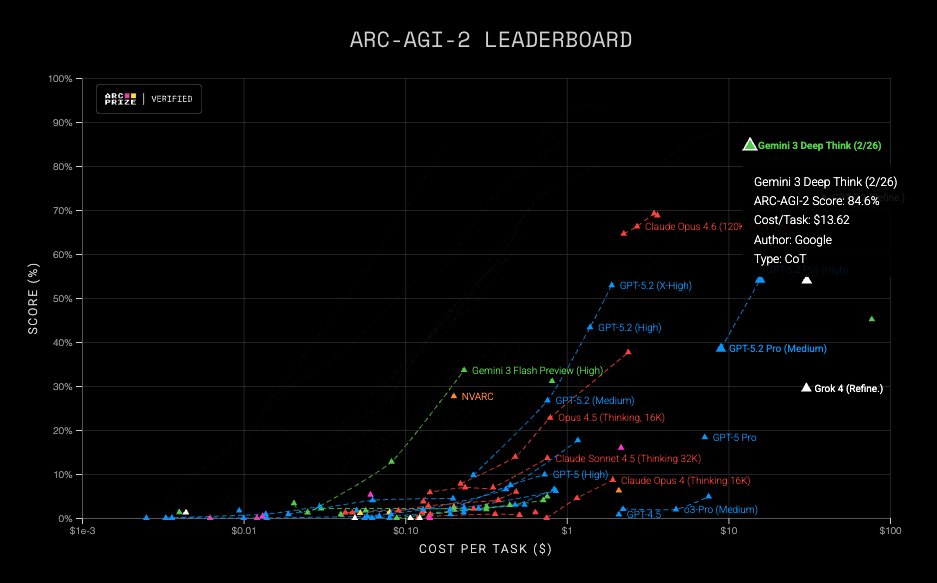
Built for challenging STEM work, Google's Gemini 3 Deep Think gives life science companies a powerful new option alongside GPT-5.2 Pro for research tasks. It set a new high on benchmarks like ARC-AGI-1 and -2 while dropping costs up to 420X in just over a year.—@_simonsmith
AI has seen capabilities increase and costs decline exponentially. We now see that trajectory for speed, with OpenAI previewing a new coding model with >10X the tokens per second of competing models. Expect everything you do with AI to get faster.—@_simonsmith
The new GLM-5 model from China's Z .ai would have been SOTA just a few months ago. Even if your company avoids Chinese models, their relentless progress pressures US AI labs to accelerate offering faster, cheaper, more capable ones to stay ahead.—@_simonsmith
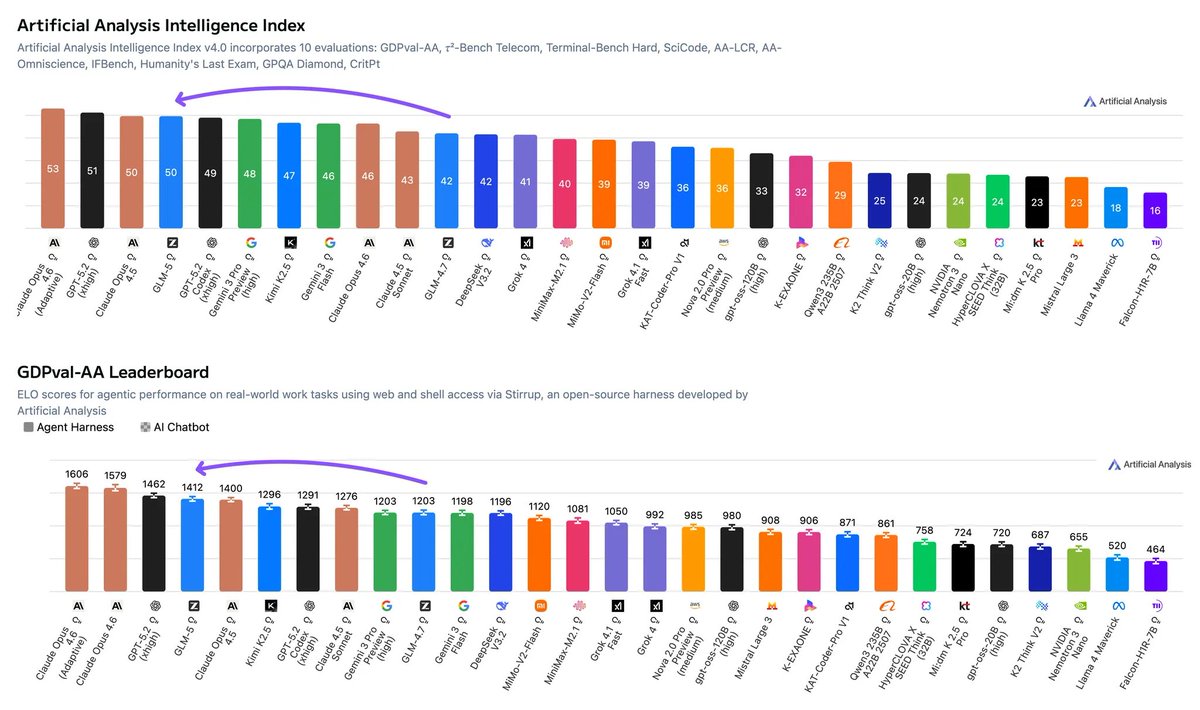
GLM-5 is the new leading open weights model! GLM-5 leads the Artificial Analysis Intelligence Index amongst open weights models and makes large gains over GLM-4.7 in GDPval-AA, our agentic benchmark focused on economically valuable work tasks
GLM-5 is @Zai_org's first new architecture since GLM-4.5 - each of the GLM-4.5, 4.6 and 4.7 models were 355B total / 32B active parameter mixture of experts models. GLM-5 scales to 744B total / 40B active, and integrates DeepSeek Sparse Attention. This puts GLM-5 more in line with the parameter count of the DeepSeek V3 family (671B total / 37B active) and Moonshot’s Kimi K2 family (1T total, 32B active). However, GLM-5 is released in BF16 precision, coming in at ~1.5TB in total size - larger than DeepSeek V3 and recent Kimi K2 models that have been released natively in FP8 and INT4 precision respectively.
Key takeaways:
➤ GLM-5 scores 50 on the Intelligence Index and is the new open weights leader, up from GLM-4.7's score of 42 - an 8 point jump driven by improvements across agentic performance and knowledge/hallucination. This is the first time an open weights model has achieved a score of 50 or above on the Artificial Analysis Intelligence Index v4.0, representing a significant closing of the gap between proprietary and open weights models. It places above other frontier open weights models such as Kimi K2.5, MiniMax 2.1 and DeepSeek V3.2.
➤ GLM-5 achieves the highest Artificial Analysis Agentic Index score among open weights models with a score of 63, ranking third overall. This is driven by strong performance in GDPval-AA, our primary metric for general agentic performance on knowledge work tasks from preparing presentations and data analysis through to video editing. GLM-5 has a GDPval-AA ELO of 1412, only below Claude Opus 4.6 and GPT-5.2 (xhigh). GLM-5 represents a significant uplift in open weights models' performance on real-world economically valuable work tasks
➤ GLM-5 shows a large improvement on the AA-Omniscience Index, driven by reduced hallucination. GLM-5 scores -1 on the AA-Omniscience Index - a 35 point improvement compared to GLM-4.7 (Reasoning, -36). This is driven by a 56 p.p reduction in the hallucination rate compared to GLM-4.7 (Reasoning). GLM-5 achieves this by abstaining more frequently and has the lowest level of hallucination amongst models tested
➤ GLM-5 used ~110M output tokens to run the Intelligence Index, compared to GLM-4.7's ~170M output tokens, a significant decrease despite higher scores across most evaluations. This pushes GLM-5 closer towards the frontier of the Intelligence vs. Output Tokens chart, but is less token efficient compared to Opus 4.6
Key model details:
➤ Context window: 200K tokens, equivalent to GLM-4.7
Multimodality: Text input and output only - Kimi K2.5 remains the leading open weights model to support image input
➤ Size: 744B total parameters, 40B active parameters. For self-deployment, GLM-5 will require ~1,490GB of memory to store the weights in native BF16 precision
➤ Licensing: MIT License
Availability: At the time of sharing this analysis, GLM-5 is available on Z AI's first-party API and several third-party APIs such as @novita_labs ($1/$3.2 per 1M input/output tokens), @gmi_cloud ($1/$3.2) and @DeepInfra ($0.8/$2.56), in FP8 precision
➤ Training Tokens: Z AI also indicated it has increased pre-training data volume from 23T to 28.5T tokens
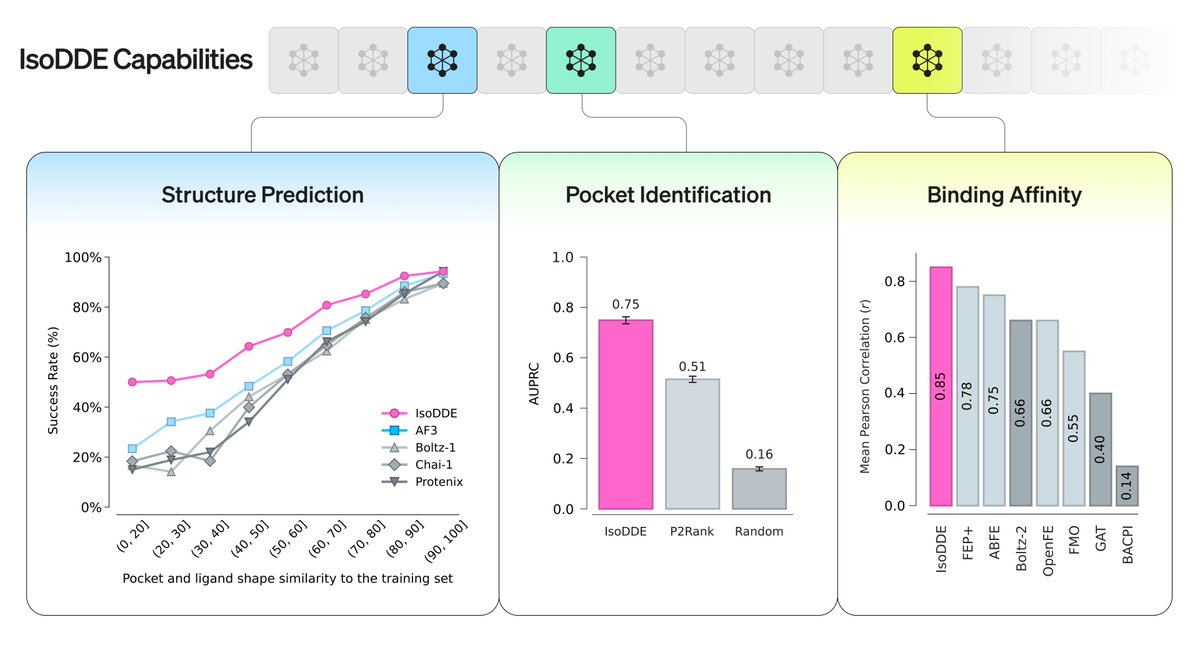
Google DeepMind offshoot Isomorphic Labs has announced advances that increase the proportion of AI-generated drugs likely to be safe and effective. For life science companies, this could reduce wasted time on low-quality candidates and shorten time to market.—@_simonsmith
Today we share a technical report demonstrating how our drug design engine achieves a step-change in accuracy for predicting biomolecular structures, more than doubling the performance of AlphaFold 3 on key benchmarks and unlocking rational drug design even for examples it has never seen before.
Head to the comments to read our blog.
With the start of ads in ChatGPT, we'll learn alongside OpenAI how ads in chatbots will work. Health ads are currently excluded, so pharma marketers will need to watch from the sidelines for now.—@_simonsmith
We’re starting to roll out a test for ads in ChatGPT today to a subset of free and Go users in the U.S.
Ads do not influence ChatGPT’s answers. Ads are labeled as sponsored and visually separate from the response.
Our goal is to give everyone access to ChatGPT for free with fewer limits, while protecting the trust they place in it for important and personal tasks.
https://t.co/zwETrWOnTr
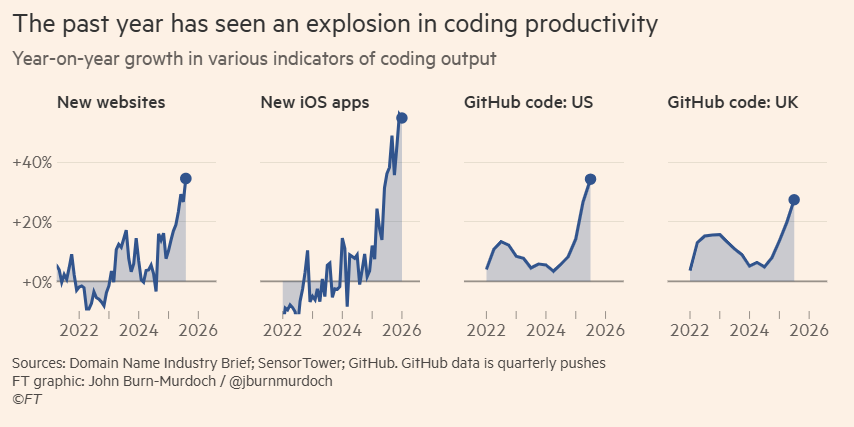
Following the release of powerful AI coding models and agentic harnesses, there's been a quantifiable explosion in software productivity. As the models and harnesses improve for other types of knowledge work, life science companies should prepare for similar gains.—@_simonsmith
Both OpenAI and Anthropic released updated models as the AI race shifts to agentic and coding abilities that drive recursive self-improvement of products and models. The pace of releases is also increasing: OpenAI's prior release was December, Anthropic's November.—@_simonsmith
It's Christmas morning: @OpenAI and @AnthropicAI shipped new models on the same day!
We tested GPT 5.3 Codex vs. Opus 4.6 head-to-head.
Verdict: the models are converging.
Here’s what we found 🧵
https://t.co/GO4ILwQ2er
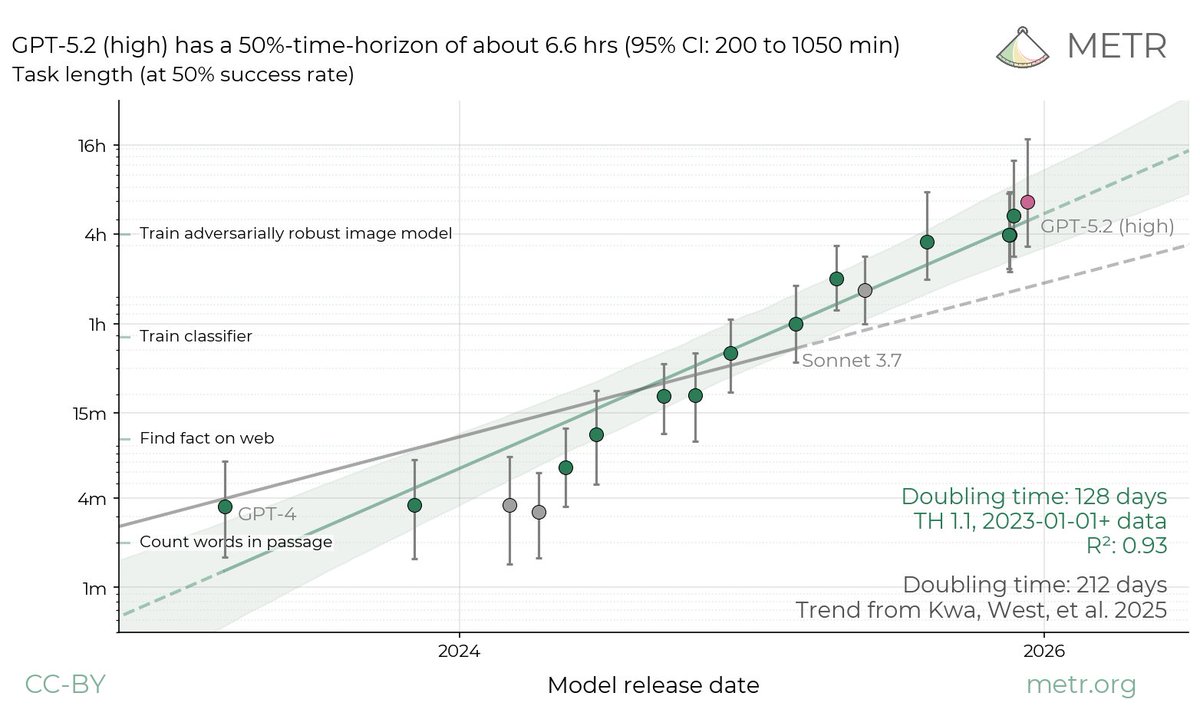
The duration that AI models can work autonomously is rapidly increasing, opening ever more use cases. In its latest time horizon update, METR finds GPT-5.2 capable of 6.6 hours of human-equivalent work. This is doubling about every 4 months, up from every 7.—@_simonsmith
We estimate that GPT-5.2 with `high` (not `xhigh`) reasoning effort has a 50%-time-horizon of around 6.6 hrs (95% CI of 3 hr 20 min to 17 hr 30 min) on our expanded suite of software tasks. This is the highest estimate for a time horizon measurement we have reported to date.
ChatGPT launched an era of turn-by-turn AI assistance. Now we're moving to delegation. OpenAI's new Codex app lets you oversee multiple agents working in parallel across tasks and projects. The next era will be one human to many agents, not one to one.—@_simonsmith
With the Codex app you can:
- Multitask effortlessly: Work with multiple agents in parallel and keep agent changes isolated with worktrees
- Create & use skills: package your tools + conventions into reusable capabilities
⁃ Set up automations: delegate repetitive work to Codex with scheduled workflows in the background
Some people resist using AI because of its jagged intelligence. A new commentary in Nature argues that the imperfect, nonhuman general intelligence we have is still generally intelligent, if alien. So we should leverage its strengths, even knowing its weaknesses.—@_simonsmith
A pretty bold commentary in Nature written by linguists, computer scientists and philosophers declaring "by reasonable standards, including Turing’s own, we have artificial systems that are generally intelligent. The long-standing problem of creating AGI has been solved."
This week, Klick Wire turns 14! 🎉 For 14 years, with 700 issues and counting, we’ve been sharing the digital health stories that help teams stay informed, grounded, and ready for what’s next—thanks to the readers who’ve made it part of their Monday routine.
👉 This week’s Klick Wire is live here: https://t.co/924AWDrkwH
A key 2026 trend to watch: increasing AI agent autonomy. The rapid rise of agent social network Moltbook previews what's coming. Today it's entertainment, but soon agent-to-agent interactions and transactions will dominate the web.—@_simonsmith
Ever wonder how much your Zoom background might be saying about you?
A Klick Labs study was recently featured in @PsychToday 🧠. The article explores how people are perceived during video calls, and how subtle details (like what’s behind you on screen) can shape first impressions more than we realize.
Check it out: https://t.co/cRJLewtmka
As marketers consider AI's impact on user behavior, an emerging medium to watch is playable, generated worlds. With Google making Project Genie available for the first time, we'll better understand how they work, and how brands might use them to reach audiences.—@_simonsmith
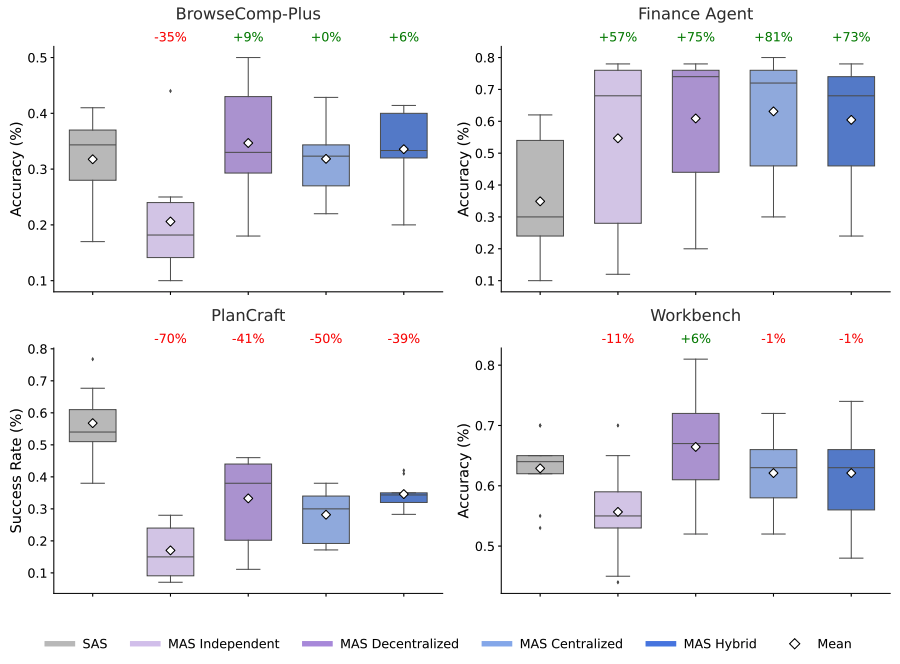
As businesses increasingly use multi-agent swarms, new research from Google shows the importance of a coordinator agent and identifies when parallelization beats sequential execution and vice-versa. Important insights for using agents to do real work.—@_simonsmith
A common heuristic in LLM agent design—"more agents is better"—might be wrong.
Across 180 configurations, we find multi-agent coordination is task-contingent: +81% on parallelizable tasks (finance), but -70% on sequential ones (planning). Architecture-task alignment matters more than agent count.