Marin is using quantile balancing from @Jianlin_S (who developed RoPE, which was also a good idea) to train our current 1e23 FLOPs MoE. The idea is elegant: assigning tokens to experts by solving a linear program. No hyperparameters to tune. Yields stable training.
Vince Zampella redefined the modern FPS benchmark quality under unfavorable circumstances repeatedly, and is unquestionably a true legend in the entire gaming industry. Rest in peace.
I cannot believe I am writing this.
Vince Zampella, a titan of the video game industry, the co-creator of Call of Duty and co-founder of Respawn Entertainment, not to mention a dear friend, died in a car crash yesterday in Los Angeles.
Sergey going back into founder mode has had significant positive impact on GDM GenAI projects, because he can (and did) short-circuit all the BigCo bullshit researchers kept bumping into.
Now the funny part which I didn't know, is that this was triggered by an OpenAI guy, Dan!
@youjiaxuan I think despite far from perfect, the way in which Huggingface tags are used by automation tools and resource maintainers presents a good near term hack. Objective metrics like model size, dataset size, topic tags (e.g. pretraining vs RL) can help bucket the expectations better.
Diffusion will obviously work on any bitstream.
With text, since humans read from first word to last, there is just the question of whether the delay to first sentence for diffusion is worth it.
That said, the vast majority of AI workload will be video understanding and generation, so good chance diffusion is the biggest winner overall.
Also means that the ratio of compute to memory bandwidth will increase.
The reverse KL → mode seeking, forward KL → mode covering principle does not necessarily work in LLM RL. Actually, it is possible for both KL regularizations to not promote low support samples.
@DimitrisPapail@JustinLin610@SchmidhuberAI That OG world model paper from David Ha is so cool before the foundation models existed, the follow ups like PlaNet, Dreamer, SimPLe had a good run
@dejavucoder If the students are claiming that those classes are useless, those students are either too good or too bad. Either way they are in the wrong place. For the less equipped, these and the NYU ones are super insightful if you pay close attention to their message and think deeply.
I'm convinced that people with all the extremely bull take on RL after sutton's interview have never touched data directly, and simply don't know the importance of data.
"Data is so very important" and "RL is the only way" is secretly mutually exclusive statement.
Remember how many IMO winners google hired to label data to get IMO gold?
Really happy to see people reproducing the result that LoRA rank=1 closely matches full fine-tuning on many RL fine-tuning problems. Here are a couple nice ones:
https://t.co/x7hcgNL3Bd
https://t.co/5JyKuKd9wS
@eliebakouch Orthogonality plays so many important roles in past optimization centered works. Coordinate descent, mean field variational bayes, vanilla gibbs sampling all had similar vibes like this, each motivated slightly differently ofc.
Unfortunate reality: most open-source LLM servers (e.g. Together) don’t offer cache-hit discounts, while closed providers like OpenAI do. DeepSeek does discount, but most third-party servers don't.
Closed models can end up much cheaper than open ones :(
Lower bound on the variance of any unbiased estimator is greater or equal to the inverse of the Fisher information with equality holding iff the parametric distribution is an exponential family.
Independently discovered by Fréchet, Darmois, Cramér and Rao
https://t.co/PlTXV0z0vL
Jeffreys centroid minimizes the average symmetrized Kulback-Leibler divergence (SKLD) of a population.
Centroid not in closed form...
We propose Jeffreys-Fisher-Rao center as a proxy of Jeffreys centroid = Fisher-Rao midpoint of sided KL centroids
https://t.co/zHQgrhWbu0
Looking at the thread. The common frame to look at the more general phenomenon involves an eigenproblem of the form Oƒ = λƒ, where the operator O encodes either: a symmetry (translations, rotations, general group transformations), or a
a statistic (e.g. covariance, correlation),
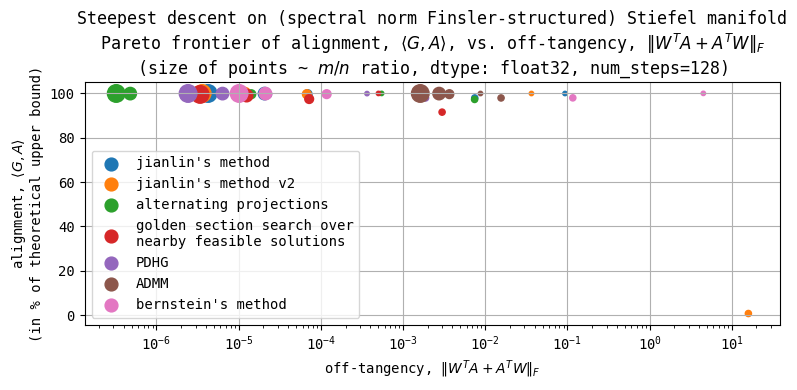
I've finally solved steepest descent on Finsler-structured (matrix) manifolds more generally. This generalizes work by me, @jxbz, and @Jianlin_S on Muon, Orthogonal Muon, & Stiefel Muon.
---
The general solution turned out to be much simpler than I thought. And it should generalize to any combination of (underlying manifold, Finsler norm) and any number of extra constraints on the updates so long as the feasible set for each constraint is convex.
---
I now consider this class of problems as sufficiently solved (by my definition of 'solved') and thus I'm moving on to other things I'm interested about.
I kept doing this at every single company I stayed at and it really takes the right kind of audience to truly appreciate its firepower at just right moments. An incredible skill I wish most people would have, surprisingly quite rare in the SV bubble.
.@pmarca: "The person who writes down the thing has tremendous power."
In most companies, almost no one does it.
If you can turn chaos into a coherent plan on paper, people will follow your lead, whether you have the title or not.