Dreading your @AnthropicAI API bills? We just ran a benchmark of equivalent open source models on @LilacML and GLM 5.1 came on top even for the most tedious tasks.
Read our blogpost here.
https://t.co/0f15TuvNBC
Folks at @LilacML are onto something!
Introducing the Monastery for AI-native founders.
A single builder can now outperform a publicly traded company.
$2 million. 12 weeks. Do the impossible.
Cache pricing is in 🎆 for GLM 5.1 and Kimi K2.5!
Lowest cost in the industry at the highest throughput for shared endpoints.
Read more at: https://t.co/kZAP2maasv
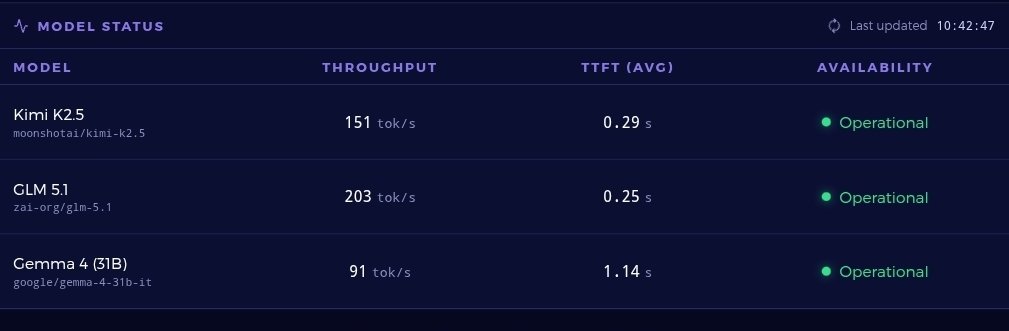
Real time status now available to all on our endpoints -- see it by hitting https://t.co/s0YDdrFTkj or go to our website: https://t.co/KfCKzCiRFu
Fast Throughout, Low Latency, Low Price!
GLM 5.1 and Kimi K2.6 are now included in the subscription, including their Thinking variants.
For these two model families, input tokens count 2x against included-input limits (for example, 1M input tokens on GLM 5.1 or Kimi K2.6 uses 2M included-input tokens).