BREAKING: Microsoft just showed that the hardest part of AI research can't be automated yet.
An AI agent replicated 3 weeks of expert work in 1 day. But it plateaued at 70% quality. The jump to 100% required a human to look at failure patterns and make a structural decision the AI kept missing.
The last 30% is still a human job.
Microsoft Research built an AI system that evaluates whether computer-use agents actually completed their tasks.
Think of it as an automated judge that watches an AI browse the web and decides: did it succeed or fail?
Getting this right matters a lot.
If your judge is wrong, every benchmark score you've ever seen is wrong.
Every training signal your agent learned from is corrupted.
The existing judges WebVoyager and WebJudge had false positive rates above 45% and 22% respectively.
That means nearly half of all failed agent tasks were being marked as successes.
Microsoft's human expert spent 3 weeks iterating to fix this.
Across 32 experiments, he discovered four structural design principles that brought the false positive rate down to near zero.
Then Microsoft gave an AI agent the same starting point and the same goal.
> The AI finished in 1 day.
> It hit 70% of the human expert's quality.
> Then it stopped improving.
The gap between where the AI plateaued and where the human landed came down to one thing:
→ The AI made incremental edits — tightening thresholds, adjusting language for individual failure cases
→ The human made structural bets — looking at hundreds of failures and inventing new scoring categories
→ The AI's edits were conservative and safe — never increasing false positive rate
→ The human's biggest gains came from opinionated, high-level rules that required judgment, not data
→ One human insight alone — "separate nitpicks from critical failures" — drove a step-function jump the AI never discovered
The AI was given the same principles the human used.
It had the same experimental infrastructure.
It ran the same tests and committed changes to version control just like the human did.
But when the human saw an agent get penalized for rounding $5.95 to $6, he derived a general rule.
The AI saw the same failure and tightened the language for that specific case.
One approach scales. The other doesn't.
There is a twist though.
When the AI was given the human's best work as a starting point, it actually surpassed the human expert.
It found improvements the human couldn't find through fine-grained optimization of an already-strong foundation.
The lesson: human expertise and AI optimization play completely different roles.
Humans are essential for discovering the core structural principles.
AI is better at the fine-grained tuning that extracts the remaining performance once those principles exist.
The current framing of "AI replaces human researchers" misses this entirely.
The real workflow is: human does the hard structural thinking, AI does the exhaustive optimization on top.
The last 30% isn't a gap that closes with more compute or a stronger model.
It closes with judgment.
And judgment, for now, still belongs to the human.
I'm not vibing with the GPT-5.2 based Deep Research at all—it's basically useless compared to Gemini’s. The reports are barely readable, surface-level, and just a basic summary at best.
OpenAI needs to do something about this.
Whoever worked on GPT-5.4's writing abilities: I would love to learn more about how the model improved so much here, and what went wrong before it. GPT-5.4 has a mastery of language and writing styles that feels like a leap over prior OpenAI reasoning models. It's also witty.
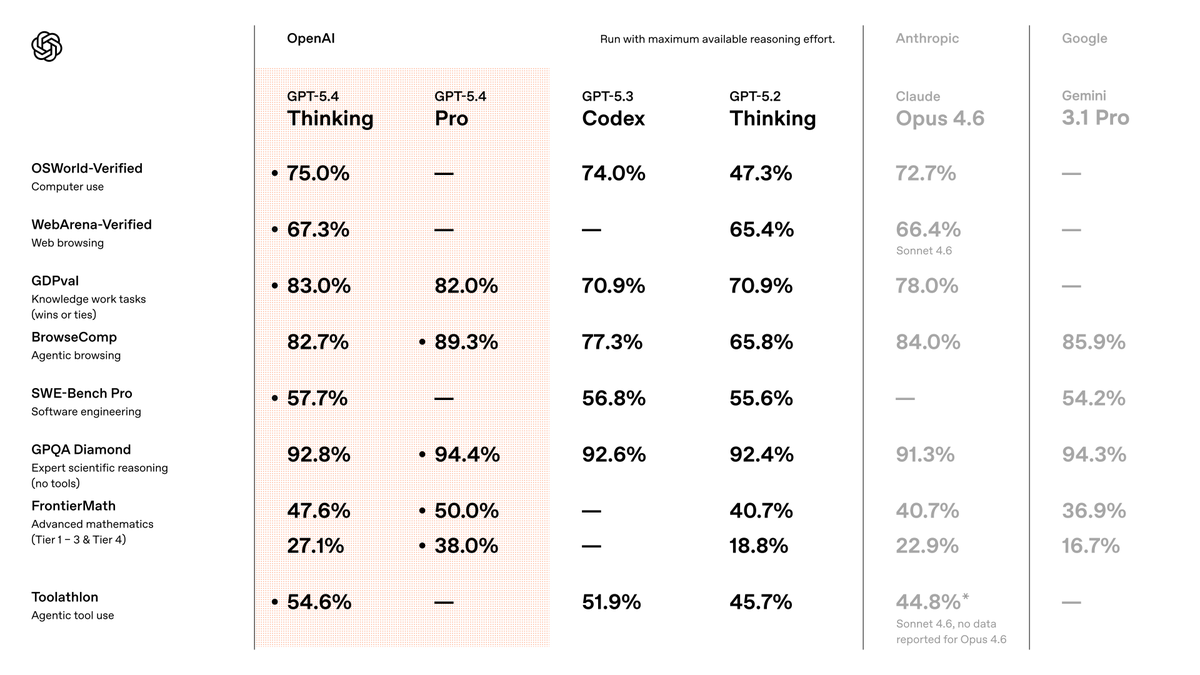
GPT-5.4 Thinking and GPT-5.4 Pro are rolling out now in ChatGPT.
GPT-5.4 is also now available in the API and Codex.
GPT-5.4 brings our advances in reasoning, coding, and agentic workflows into one frontier model.
GPT-5.4 leak: 2M token context + persistent state = KV cache explosion
This is the Memory Wars in real time
HBM for weights. SRAM for latency-critical inference. Optical interconnects to bind it all
The bifurcation I’ve been writing about isn’t theoretical anymore.
ChatGPT’s Agent Mode needs to be re-invented. It’s basically useless at this state. Deep Research is much better but not agentic enough. Ironically, the thinking model itself is quite agentic.
@GaryMarcus When everyone else is cheering and looking forward to something new, you stand on the sidelines, looking on coldly and saying it’s all an illusion. That may make you look clever, but that’s all; you contribute nothing to the situation, and your insight has no value whatsoever.
@GaryMarcus When everyone else is cheering and looking forward to something new, you stand on the sidelines, looking on coldly and saying it’s all an illusion. That may make you look clever, but that’s all; you contribute nothing to the situation, and your insight has no value whatsoever.