@willccbb Good observation! If you hover over the grayed out model names, we try to explain the caveat that we produce data examples according the 6 grayed out frontier models' failures (including llama 405B and GPT 4o). So the benchmark is biased against these grayed models.
Introducing MultiChallenge by @scale_AI - a new multi-turn conversation benchmark. Current frontier LLMs score under 50% accuracy (top: 44.93%). The new Gemini 2.0 Flash model launched today has also been included to our SEAL leaderboard.
📄 Paper: https://t.co/9ok0yYNEO0
🏆Leaderboard: https://t.co/ubvpY6cPeb
🚀 Introducing the SEAL Leaderboards! We rank LLMs using private datasets that can’t be gamed. Vetted experts handle the ratings, and we share our methods in detail openly!
Check out our leaderboards at https://t.co/bRdTbIMd20!
Which evals should we build next?
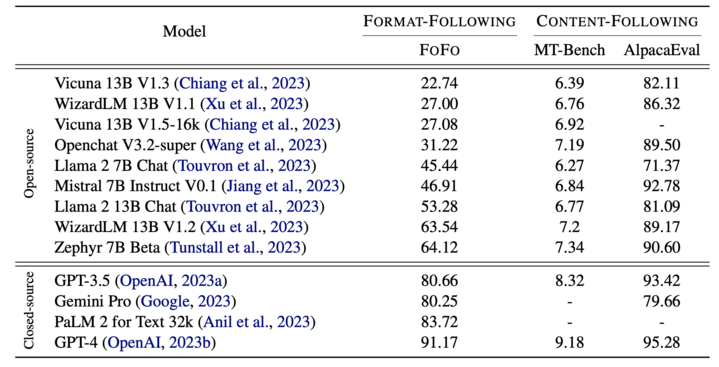
Excited to share our brand new LLM evaluation benchmark 🐠FoFo🐠 on format-following!
🐠FOFO🐠 is a pioneering benchmark for evaluating large language models’ (LLMs) ability to follow complex, domain-specific formats, a crucial yet under-examined capability for their application as AI agents.
Link: https://t.co/qBETnrar8r
Our evaluation across both open-source (e.g., Llama 2, WizardLM) and closed-source (e.g., GPT-4, PALM2, Gemini) LLMs highlights three key findings:
1. open-source models significantly lag behind closed-source ones in format adherence;
2. LLMs’ format-following performance is independent of their content generation quality;
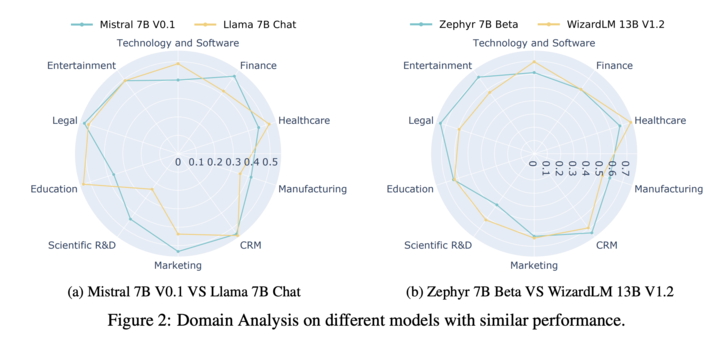
3. LLMs’ format proficiency varies across different domains.
These observations suggest two key points:
i) The format-following capacity of LLMs appears independent of their content-following capacity shown in AlpacaEval and MT-Bench, and may necessitate specialized alignment fine-tuning beyond the conventional instruction-tuning of open source LLMs.
ii) Format-following capacity is not universally transferable across domains, highlighting the potential utility of our benchmark as a guiding and probing tool for selecting domain-specific AI agent foundation models.
Code LLaMA is finally here. Congrats to @MetaAI@ylecun@syhw, etc..
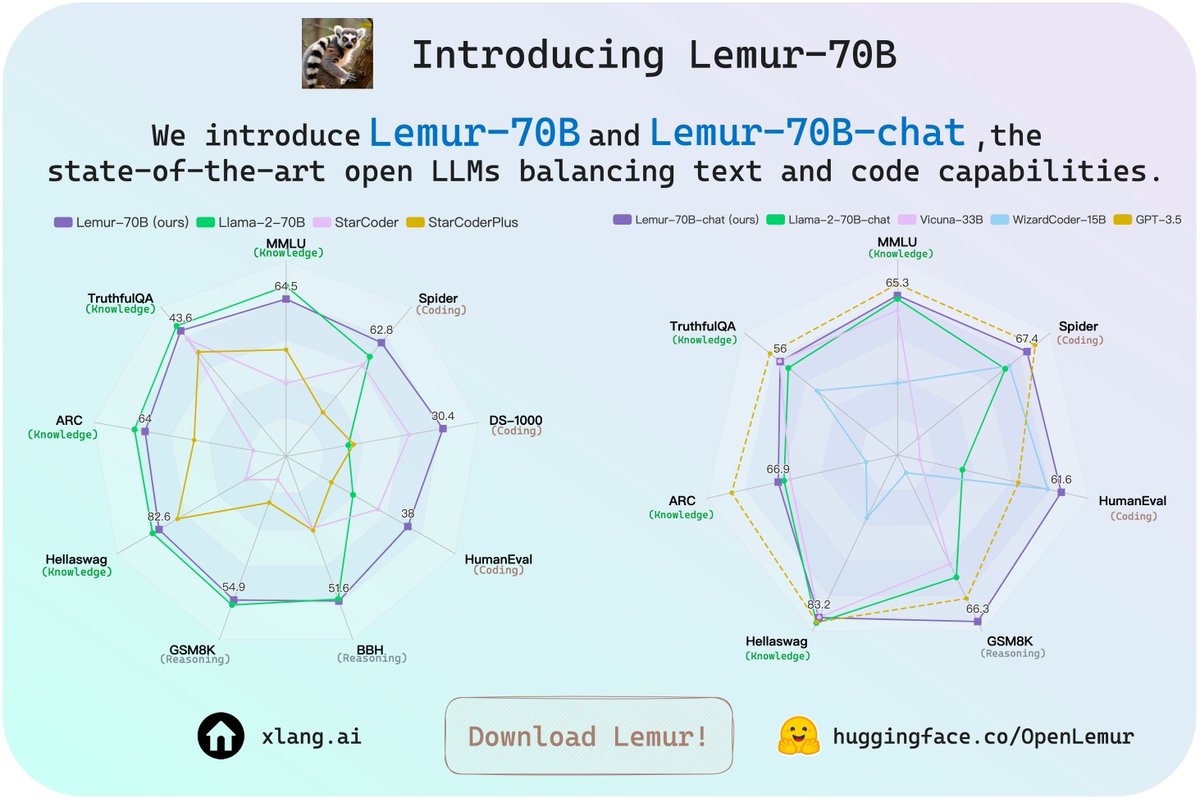
And we'd like to introduce the finetuned llama2-70B model -- 🐒Lemur-70B🐒 again😉, a complement to Code LLaMA (7B, 13B, 34B) and maintains strong performance in text tasks.
Code: https://t.co/MburXL8pC4
🧵Lemur-70B-chat stands out as the top-performing open-source LLM, rivaling ChatGPT across a broader spectrum of tasks when compared to other available open-source LLMs.
1/6 Open LLMs have traditionally been tailored for either 📚text or 💻code, with limited ability to effectively balance both.
🚀 Introducing #Lemur70B! 🚀: the SOTA open LLM balancing 📚text & 💻code capabilities
🤗Model: https://t.co/BPp7Tn2WsV
📖Blog: https://t.co/LAPYhd7IcZ
1/6 Open LLMs have traditionally been tailored for either 📚text or 💻code, with limited ability to effectively balance both.
🚀 Introducing #Lemur70B! 🚀: the SOTA open LLM balancing 📚text & 💻code capabilities
🤗Model: https://t.co/BPp7Tn2WsV
📖Blog: https://t.co/LAPYhd7IcZ
@adad8m I played with chatGPT on some basic physics questions, such as , "one person standing on a train heading west with speed 100 km/h, throws a ball to east with speed 100 km/h, what is the speed of the ball to a stationary observer on ground? " chatGPT fails a lot on these questions
I can't imagine being a woman in CS seeing this week's news. I feel shocked and devastated. Foremost for the victims. But also for all the other women who have to put their guard up higher, doubting the authenticity of the professional attention they receive. You deserve better.
The worst ever feature introduced online is the automatic redirection to localized websites. How can I convince the world that I don’t want them to turn into Finnish?