Exciting to see the launch of the NVIDIA Isaac GR00T Reference Humanoid Robot. Open, research-focused humanoid platforms can help accelerate progress across the robotics community. Looking forward to the innovations this enables. A great contribution from NVIDIA Robotics!
NVIDIA announces the first open humanoid robot reference design built for robotics research.
The NVIDIA Isaac GR00T Reference Humanoid Robot combines the @UnitreeRobotics H2 humanoid robot, @SharpaRobotics Wave five-fingered hands for dexterous manipulation, Jetson Thor onboard compute, and Isaac GR00T open software and models, giving researchers a full-stack platform from data capture to model deployment.
Read the #NVIDIAGTC Taipei announcement: https://t.co/ZsT3qQKucb
Excited to be at #ICRA2026 in Vienna this week 🇦🇹 -- I'll be presenting SCOUT as a spotlight talk at the Rigorous Robot Perception workshop on June 01 at VIP Lounge C, and SceneComplete as an Oral talk today (June 02 at TuAT3.5).
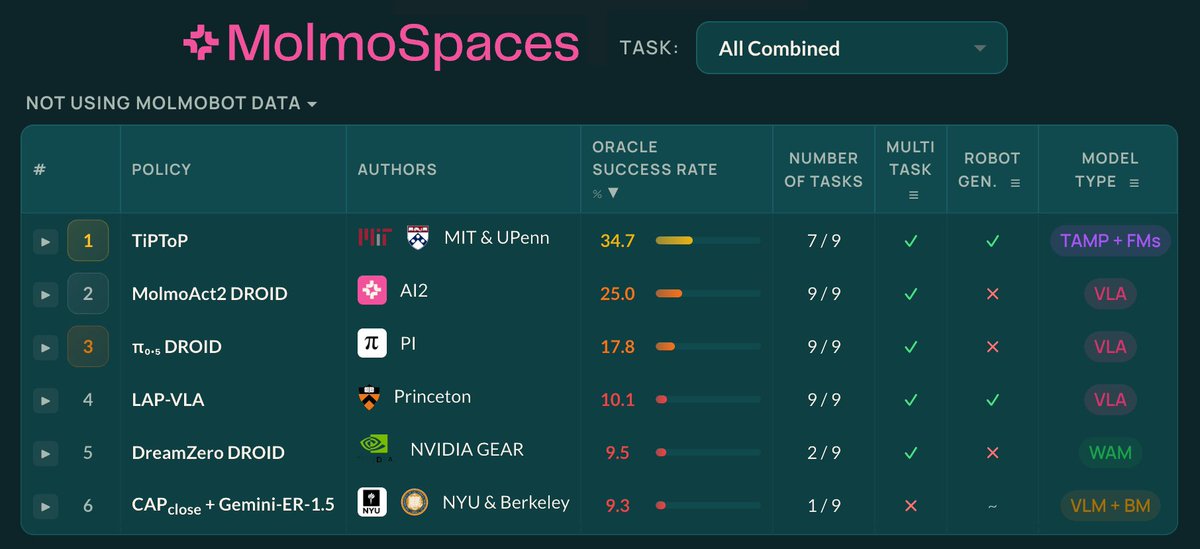
𝗧𝗶𝗣𝗧𝗼𝗣 𝗶𝘀 #𝟭 𝗼𝗻 𝗠𝗼𝗹𝗺𝗼𝗦𝗽𝗮𝗰𝗲𝘀! Outperforming VLAs including MolmoAct2 and π₀.₅, and WAMs like DreamZero
It's the only method that uses inference-time search and 𝙯𝙚𝙧𝙤 robot data. We didn't do any benchmark-specific tuning.
We ran TiPToP on MolmoSpaces and achieved SOTA! And we wrote an X article thing to discuss details - excited to hear any questions/comments!
Check out the leaderboard here: https://t.co/fmWCS50Ich.
TiPToP is also fully-open and should take <1hr of setup: try it yourself here: https://t.co/RA7LmTEHT9
PhDone and officially a robot doctor!
Thanks to incredible advisors Leslie and Tomás @MIT_LISLab and my secret bonus advisor @tomssilver - I’m so so lucky to have gotten to do research with them.
I’m excited to keep working on making useful generalist robots a reality 🤖🚀
We've released the TiPToP code open source! 🚀
We put a lot of effort into making this easy to run, install and build on. You can get it running on your DROID setup in under an hour. No training data needed. No demonstrations. Just type in what you want your robot to do 🤖💬
You can also adapt it to new embodiments with minimal effort. Give it a try and let us know what you think!
💻 Code: https://t.co/djwCNAafL4
📖 Docs: https://t.co/BA5pJuuLVA
Imagine you told a robot to "find your car keys" in your apartment and it looked around, opened a drawer, and retrieved them for you.
As a step towards that, I adapted TiPToP to run on the RBY1 humanoid in our lab! Here's an example instruction it follows: "Put the green block on the blue plate and the yellow block on the magazine."
TiPToP helps plan over the right arm + single torso joint, but it's easy to unlock more joints -- even the base wheels -- for more expressive, real-world tasks.
Humans find objects without thinking twice. One day, robots will too! 🤖
Everyone is scaling VLAs with more robot data.
TiPToP shows another path.
No robot training, no policy learning.
Just RGB + language → 3D scene → GPU TAMP planner → trajectory.
Foundation models + planning alone can run real manipulation tasks.
State-of-the-art robot policies often need hundreds of hours of data. What if we needed none?
Introducing TiPToP: a manipulation system that zero-shots open-world tasks from pixels and language using vision foundation models and GPU-parallelized Task and Motion Planning (TAMP).
It was a pleasure to be back at @MIT to present at the #Robotics Seminar! Great to see all the exciting work happening there. Thanks so much @GioeleZardini for hosting me!
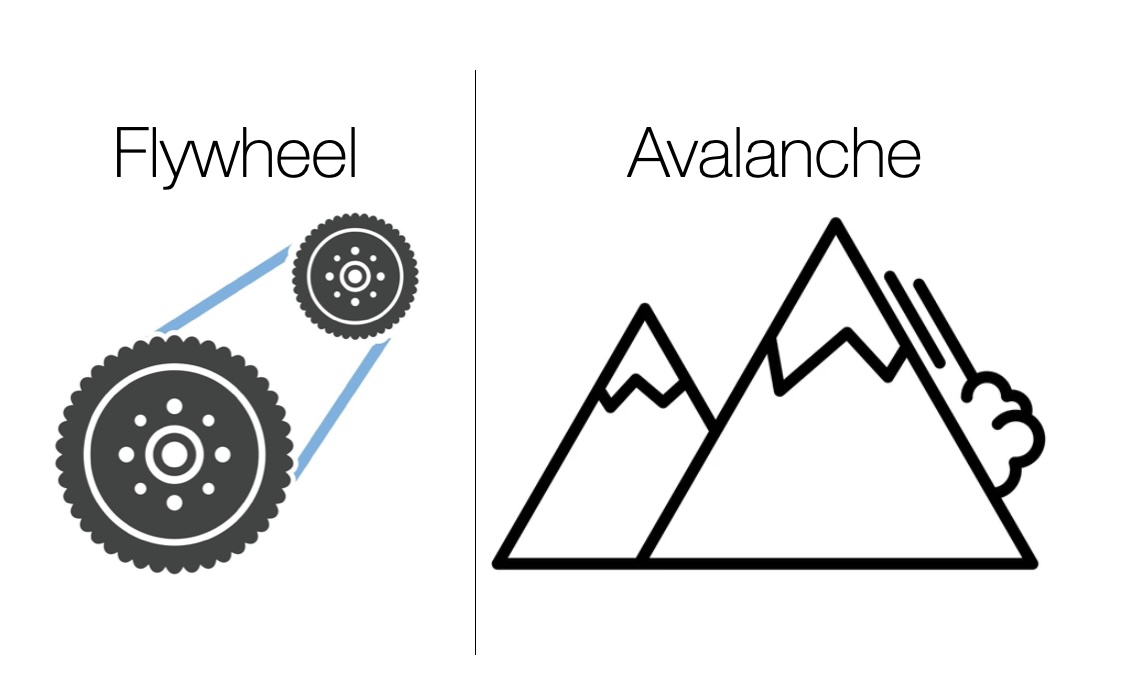
Data Flywheel -> Data Avalanche: Thx to Leslie Kaebling and @Pulkitology Agrawal for suggesting "avalanche" as a better metaphor than "flywheel" for combining model-free + model-based methods to bootstrap a specific robot task to bootstrap & amplify on-policy data collection.
Reasoning over long horizons would allow robots to generalize better to unseen environments and settings zero-shot. One mechanism for this kind of reasoning would be world models, but traditional video world models still tend to struggle with long horizons, and are very data intensive to train. But what if instead of predicting images about the future, we predicted just the symbolic information necessary for reasoning?
@nishanthkumar23 tells us about Pixels to Predicates, a method for symbol grounding which allows a VLM to plan sequences of robot skills to achieve unseen goals in previously unseen settings.
To find out more, watch episode #44 of RoboPapers with @micoolcho and @chris_j_paxton now!
Full episode dropping soon!
Geeking out with @nishanthkumar23 on From Pixels to Predicates: Learning Symbolic World Models via Pretrained Vision-Language Models https://t.co/sOYPeROO6F
Co-hosted by @micoolcho@chris_j_paxton
World models hold a lot of promise for robotics, but they're data hungry and often struggle with long horizons.
We learn models from a few (< 10) human demos that enable a robot to plan in completely novel scenes!
Our key idea is to model *symbols* not pixels 👇
Check out Leslie Kaelbling's #RLC2025 Keynote where she talks about some new pespectives and a number of new works from the group: https://t.co/fzTDhaFp2j
We're excited for #RLC2025! If you're at the conference, be sure to catch our PI Leslie Kaelbling's keynote on "RL: Rational Learning" from 9-10 in CCIS 1-430. Leslie will talk about some new perspectives + exciting new results from the group: you won't want to miss it! 🤖
#ICRA2025 🤖 I spent 3 years of PhD making efficient long-horizon manipulation planning algorithms. VLMs ultimately provide the essential common-sense and horizon-reduction benefits.
❗VLMs can generate plausible robot task plans, but actions may not be feasible for robots due to reachability and obstacles. 🤝 So we use a TAMP planner to take in the next VLM-generated subgoal and plan for actions and trajectories.
📈 VLM-TAMP successfully solves cooking problems that require 30-50 actions and interact with 20+ objects. Excited to present it on Thursday!
https://t.co/aHYLnbHOZW
Can we teach a robot its limits to do chores safely & correctly? 🧵
To help robots execute open-ended, multi-step tasks, MIT CSAIL researchers used vision models to see what’s near the machine & model its constraints. An LLM sketches up a plan that’s checked in a simulator to ensure it’s safe & realistic, potentially aiding household robots: https://t.co/op3ULl7oaj
Curious to hear about creating generalist robots from leaders in the field? Don’t miss our panel “Representations for Generalist Robots” (4-5pm) @corl_conf LEAP workshop! Feat. @chelseabfinn@animesh_garg Vincent Vanhoucke @Marc__Toussaint@sidsrivast and Leslie Kaelbling!
🚀Excited to share SceneComplete: an open-world 3D scene completion system for constructing a complete, segmented 3D model of a scene from a single RGB-D image.🖼️🤖
SceneComplete enables dexterous grasping and robust robot manipulation in highly cluttered scenes - a short 🧵