Humans don’t explore blindly.
When entering a new environment, we use prior experience to infer what might lie beyond what we can see and plan ahead.
What if robots could do the same?
Introducing MAGICIAN, our #CVPR2026 Oral paper on long-term planning for active mapping
Introducing AirVis Studio:
Turn any video into a 3D digital twin ( Gaussian Splats ) — entirely on your Mac for free.
Local. Private. Offline.
Drop a video (even 360°) → Run → View and Share.
Your spaces, yours to keep.
Introducing D4RT: A unified AI model for 4D scene reconstruction and tracking across space and time. 🎯 Catch the demo with Skanda Koppula at 12 pm at our #CVPR2026 Google booth kiosk! https://t.co/p6SclNe1zi @GoogleDeepMind
Google's new algorithm just shrunk 31GB of memory down to 4GB 🤯
TurboVec is a new open-source tool that stores the data your AI app searches through, using 16x less memory.
It runs on Google's TurboQuant, which skips the slow setup step every other tool needs.
→ Faster search than the popular alternative (FAISS)
→ Works on both Mac and standard servers
→ Narrow results to exactly what you want
→ Plugs straight into LangChain and LlamaIndex
Your data never leaves your machine. Runs fully offline, works with Python out of the box.
100% Open Source.
Google releases Gemma 4 QAT. ✨
You can now run Gemma 4 at 3x less memory with near original performance.
Quantization-Aware Training (QAT) makes it possible to run Gemma 4 26B-A4B on 16GB RAM.
GGUFs: https://t.co/wQgEocxUId
QAT Guide: https://t.co/Nsm1yeGEHx
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇
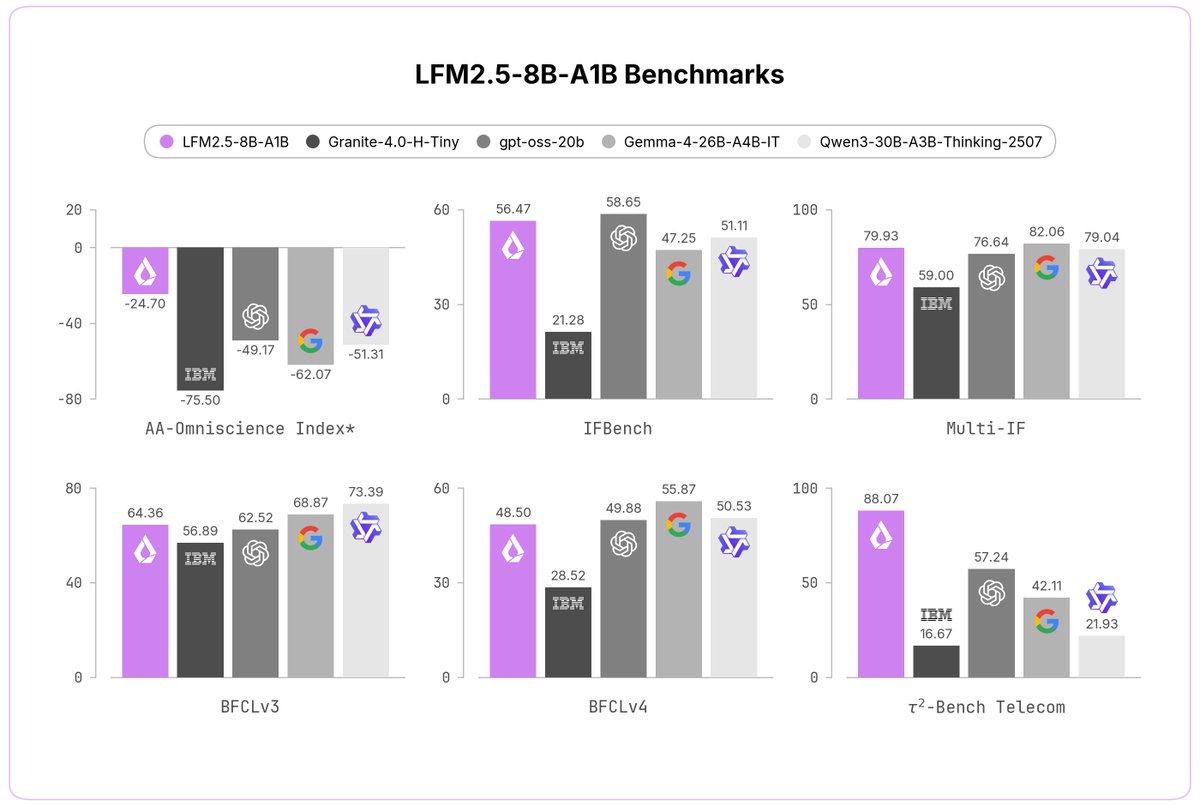
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens + large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
i just beat @GoogleDeepMind's turboquant
introducing Shard. 10x KV cache compression on Llama-3.1-8B. zero quality loss
- 10x @ 8K context, 11.2x @ 32K
- NIAH recall 1.000 across 4K-32K
- LongBench Δ ≈ 0 vs FP16
turboquant tops out at 4-6x at the same quality. we doubled it.
read more: https://t.co/PAV5WdAzN6
@kirrithan
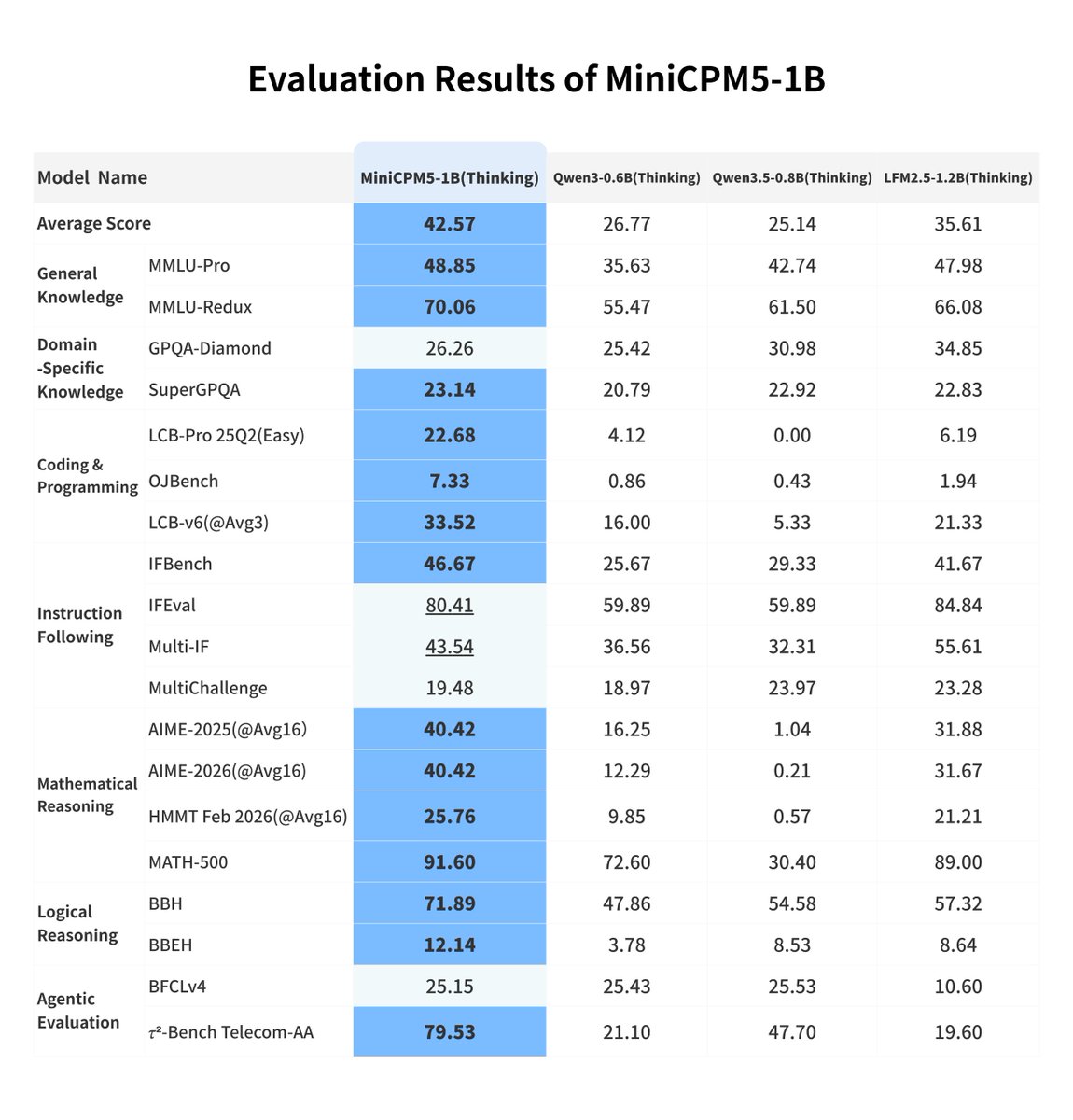
MiniCPM5-1B is now live — the strongest open‑source base model under 2B.🚀🚀
🔥 Ranks #1 on the Artificial Analysis (AA) index for small models, scoring 17.9 to beat the 2B-scale Qwen3.5-2B (16.3).
⚡ Comprehensively surpasses Qwen3.5-0.8B and LFM2.5-1.2B-Thinking in knowledge, math, coding, and tool use.
🏗️ INT4 weights = just ~0.5GB — runs on phones, browsers, laptops.
👾 Powers fully offline AI “Desktop Pet” — no cloud, no GPU cluster.
Try the model here:
🤗 Hugging Face: https://t.co/jYRKhRYe48
💻 GitHub: https://t.co/zaffsLsx5m
🔭 Modelscope: https://t.co/mkOlyKNr2n
🚀 BitCPM-CANN by ModelBest × @Tsinghua_Uni × OpenBMB is here — and it's not about stacking parameters.
Memory costs are skyrocketing. Hardware constraints are tightening. Edge AI needs smarter solutions — and BitCPM-CANN delivers!🎉
✅ Edge-ready: 8B model runs smoothly on mobile, PC, and automotive devices. Combined with MoE, even 100B->60B scale models could fit on terminal hardware.
✅ Memory-efficient: ~6× lower memory footprint vs. BF16 — unlock significantly more model capacity without adding physical RAM. No new chips required.
✅ Natively built on Ascend: The first 1.58-bit training pipeline completed end-to-end on Huawei Ascend 910B — from quantization kernels to the full training stack. Not a port. Built natively on Ascend from day one.
✅ Full model family, fully verified, 0.5B–8B: Each model is fully aligned with its full-precision counterpart, covering 11 benchmark tasks with 95–97% (1B-8B) retention compared to full-precision MiniCPM4. Open-source and fully reproducible — from research to deployment, you can run any size confidently.
BitCPM-CANN isn’t just a model — it’s the result of years of engineering rigor, turning complex research into something you can actually deploy.
Open-source, 0.5B to 8B. Try it now!👇
🤗 Hugging Face:
https://t.co/f4n9gAxjUD
🔭 ModelScope:
https://t.co/Ezj5ATsyrf
Python can now render 3D flood scenes.
In this Valencia map I used OSM buildings, streets, and parks with a synthetic flood layer to show the capability: water, terrain, and urban geometry in one readable scene.
Built with forge3d: https://t.co/IvUfbpSVPo
Spent Friday night testing @Apple ‘s new open-source ml-lito image-to-3D model running locally on Apple Silicon via Metal. No cloud, API, or uploads. Getting it working was harder than expected but got there. 👇👇👇@AppleEDU
https://t.co/D9DCX4vvwr
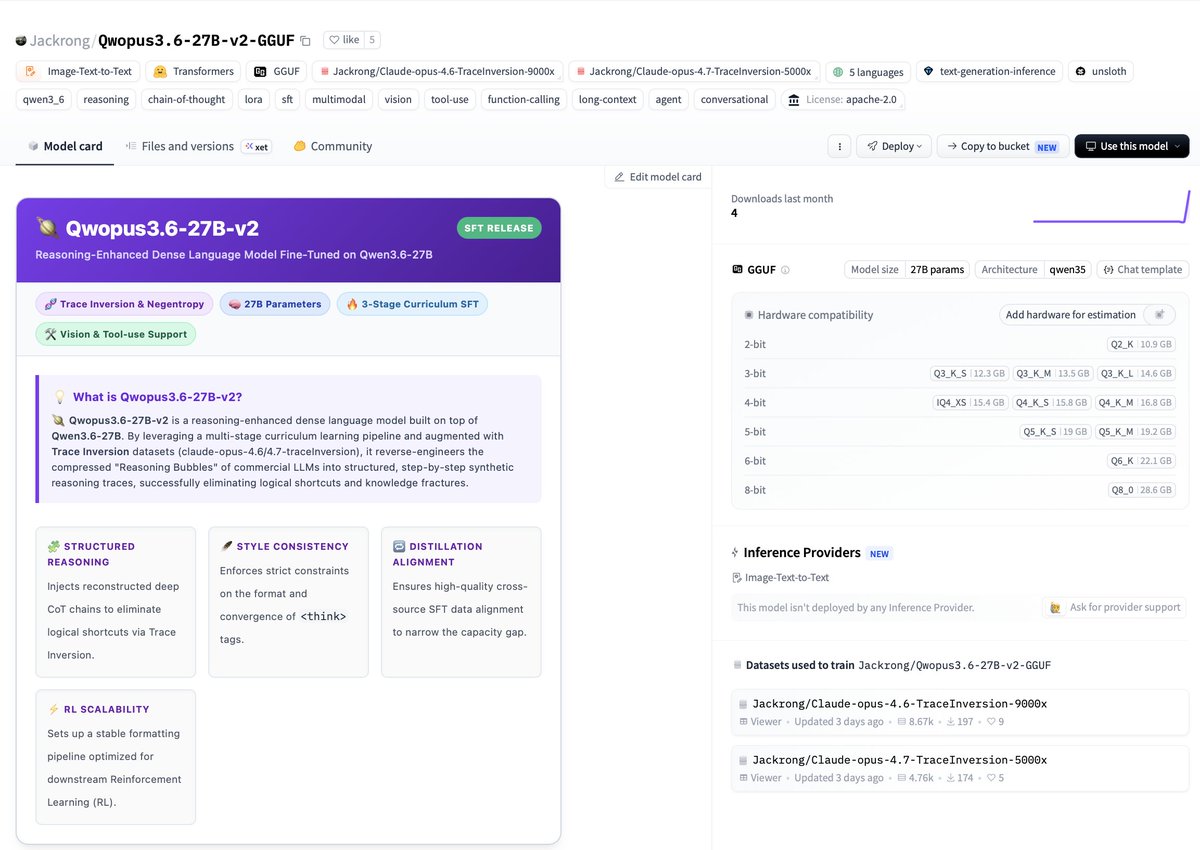
🚨BREAKING QWOPUS 3.6 27B IS FULLY LIVE!
SOTA QWEN 3.6 27b + Opus IS HERE!!!!
🚀Agentic coding GOATED: 75.25% (152/202) on SWE
🤯MMLU Pro cooked +10 Physics + jumps in Chem etc
🎮Built an entire shooter game “Qwopus Commander”
🚨Handles 303k token context at Q8 KV cache
⭐️ Runs on 24GB VRAM (Q5_K_M – RTX 4090 etc)
Runs best at 0.75–1.0 temp (higher temp = pure magic)
Inversion techniques + curriculum training = Jackrong @KyleHessling1 cooking again 👨🍳
Pull this & run it on https://t.co/01NO8kDmhd on your setup 👇🏻
https://t.co/bWIP3jGjKM
BREAKING! Qwopus 3.6 27B is LIVE!
Thank you for your patience on this one, but I believe you'll find the wait was worth it!
We've benchmarked this thing up and down, verified that it holds at least a 75.25% (152/202) in the initial 202 SWE bench solves. Not a full run of 500, but it shows the agentic coding quality from the original 27B is retained while adding all of the additional Qwopus benefits across many domains. As always, Jackrong is absolutely cooking here!
COT quality has improved significantly through the inversion techniques from our Negentropy proof of concept. It also went through thorough curriculum training. You can check out the MMLU pro benchmarks on the model card, but it improved a whopping 10 points over the base model in physics, as well as meaningful jumps in Chemistry, business, and computer science.
However, the best part is that I was able to build an entire survival shooter game using this local model entirely. I genuinely was blown away by the results, which you can play right now on my HF space (link in comments below). "Qwopus Commander" was completed in 9 turns of Qwopus 3.6! To test the new long context training, I made it re-output the entire 3000+ line program each turn, and it would make fixes and add features that I requested in large prompts, while perfectly replicating the entire rest of the game from context. What's more is that I did it all at Q8 KV cache quantization, and never had an issue over the entire 303k token run!
IMPORTANT: Run it at --temp 0.75 to 1. Mess with it in that range for your use case. Higher temp actually lets the fine-tune shine and be exploratory and is also more stable. Swe Bench was run at temp 1, the game was built mostly at 0.8!
We're so blessed to have all of you here and using the models! The support means so much! Please let me know what you build with it in the comments! Or if you have any issues getting it up and running, I will try my best to get back to you!
Looking forward to seeing what you legends produce with it this weekend!
https://t.co/AEl3APtTLk
Introducing HRM-Text.
An ultra-lean 1B-parameter reasoning language model designed to deliver strong general performance with a fraction of the data, compute, and infrastructure.
Trained on just 40B structured tokens, HRM-Text achieves competitive performance while using ~1/1000 of the training data of comparable models.
The kicker? The full model trains in roughly one day on a $1,000 budget.
This opens the door to a new generation of AI that is powerful, accessible, and radically easier to adapt. Theories and research concepts once deemed too expensive to test are officially back in the game.
Sapient Intelligence invites you to help us shape a new paradigm for general intelligence.