A 178 page survey study for refreshing math and generative AI foundations from University of Huddersfield.
The Little Book of Generative AI Foundations.
A neat takeaway from this paper: Wasserstein distance is not just used to compare distributions, but to define the geometry of learning itself.
The drifting model is reinterpreted as a Wasserstein gradient flow, meaning samples move along the steepest descent direction in distribution space.
In short, optimal transport becomes the rule that tells the generator where to move.
On the Wasserstein Gradient Flow Interpretation of Drifting Models
Paper: https://t.co/V71AKEWFNd
Instead of watching Netflix tonight, watch this Stanford lecture.
It explains how ChatGPT and Claude are actually built.
Stanford released it free.
Bookmark this.
SNAPCHAT PAID $150,000,000 FOR LOOKSERY - STARTUP IN DEEP LEARNING COMPUTER VISION
This 1-hour Stanford lecture on "DL for Computer Vision" will teach you how to build same project from scratch.
Bookmark it & watch today. Stanford's full course (19 lectures) on Deep Learning for Computer Vision below ↓
Terence Tao says the math behind today’s LLMs is actually simple. Training and running them mostly uses linear algebra, matrix multiplication, and a bit of calculus, material an undergraduate can handle. We understand how to build and operate these models.
The real mystery is why they work so well on some tasks and fail on others, and why we cannot predict that in advance. We lack good rules for forecasting performance across tasks, so progress is largely empirical.
A key reason is the nature of real-world data. Pure noise is well understood, perfectly structured data is well understood, but natural text sits in between, partly structured and partly random. Mathematics for that middle regime is thin, similar to how physics struggles at meso-scales between atoms and continua.
Because of this gap, we can describe the mechanisms but cannot yet explain capability jumps or give reliable task-level predictions. That mismatch, simple machinery versus hard-to-predict behavior, is the core puzzle.
----
Video from 'Dr Brian Keating' YT Channel (Link in comment)
I Wrote a New Book!!!
Optimization: A Bootcamp for Machine Learning, Inverse Problems, and Control
Pre-Order Now (July 31)
https://t.co/EoDMFapUUf
Coming Soon:
* Free PDF on website
* YouTube Videos for entire book
* Python code on GitHub
The most mass-complete list of CS video courses on the internet.
cs-video-courses. 78K+ stars.
MIT. Stanford. Berkeley. Harvard. CMU. IIT. Princeton. Caltech.
All free. All video lectures. All in one repo.
Topics covered:
→ Data Structures and Algorithms
→ Operating Systems
→ Distributed Systems
→ Database Systems
→ Computer Networks
→ Machine Learning
→ Deep Learning
→ Natural Language Processing
→ Computer Vision
→ Computer Graphics
→ Security
→ Quantum Computing
→ Robotics
→ Blockchain
From beginner (CS 50) to advanced (6.824 Distributed Systems).
The curriculum is free. The commitment is yours.
GitHub link in comments.
This 1 hour Stanford lecture on Markov Decision Processes will teach you more about the math behind systematic trading decisions than a 3 month internship at Jane Street or JPMorgan.
Bookmark & replace one movie today with this lecture, no matter what.
Godfather of AI: "If you sleep well tonight, you may not have understood this lecture."
This 47-minute lecture is the best thing I saw about AI in the last few months.
It will definitely help you understand how it actually works and where it's going.
Geoffrey Hinton built the neural networks behind every AI alive, then quit Google to warn the world about it.
The part nobody wanted to hear:
> AI is already developing abilities its creators didn't intend
> in most cognitive tasks it's already ahead of us
> the question is no longer if it surpasses us but when
> the only decision left is which side of that line you're on
Right now the average person opens Claude, types something, gets an answer, closes the tab.
They think they're using AI. they're using maybe 10% of it.
I went through his entire lecture, built a practical system from what he was describing.
18 steps to actually use Claude the right way, with copy-paste prompts that work today.
Full guide in the post below.
With the rise of AI in mathematics, many of us are rethinking what math is for—and what it even is. These are philosophical questions, and we should discuss them carefully and openheartedly. This classic essay by Reuben Hersh is a great place to start. https://t.co/Hq2NAe5mFh
FREE Math Book.
"A Brief Introduction to Machine Learning for Engineers" by Simeone. Topics: Introduction to key concepts & algorithms, Bayesian Learning, Stochastic Gradient Descent, Autoencoders, Probabilistic Graphical Models, Monte Carlo-Based Variational Inference, Approximate Learning, Entropy, Reinforcement Learning, etc.
Link to Book PDF: https://t.co/IK5HwLJRyH
MIT JUST MADE A 1048 PAGE COMPUTER SCIENCE MATHEMATICS TEXTBOOK COMPLETELY FREE.
No paywall or signup. Just the full book.
This is the exact math foundation that every serious software engineer, data scientist, and AI researcher needs.
What is inside:
↳ Mathematical proofs from scratch
↳ Logic and logical formulas
↳ Number theory and probability
↳ Graph theory and structures
↳ Algorithms and complexity
↳ Data types, sets, functions, and relations
This is the curriculum MIT charges tens of thousands of dollars to teach in person.
You can read the entire thing for free right now.
The people who will build the next generation of AI systems are not just good at coding. They understand the math underneath the code.
This book is where that understanding starts.
Save this. Share it with every developer, student, and self-taught engineer you know.
Link in comments.
MIT published 12 AI textbooks written by the top researchers who built the field.
These are not just books these are primary source material behind the world top AI ChatGPT, Claude, Gemini... (save this!)
1. Foundations of Machine Learning https://t.co/cyIHr6qm2z
2. Understanding Deep Learning https://t.co/5XUo4bPHRu
3. Machine Learning Systems https://t.co/l5bCCyXSV0
4. Algorithms for Decision Making https://t.co/1ZNU1XvSYK
5. Deep Learning https://t.co/JAo52d4JTI
6. Reinforcement Learning: An Introduction https://t.co/0XqopIY5CR
7. Distributional Reinforcement Learning https://t.co/z7bqEUK2ky
8. Multi-Agent Reinforcement Learning https://t.co/KgOtpxXAUc
9. Algorithms for Decision Making (Long Game) https://t.co/F6J9Za0igV
10. Fairness and Machine Learning https://t.co/r9egFAY6tL
11. Probabilistic Machine Learning: An Introduction https://t.co/xmmj7Ev7Of
12. Probabilistic Machine Learning: Advanced Topics https://t.co/6lUCb9blt8
I hope you found this helpful,
For more such useful resources you can follow me @ZabihullahAtal
An MIT professor taught the same math course for 62 years, and the day he retired, students from every country on earth showed up online to watch him give his final lecture.
I opened the playlist at 2am and ended up watching three of them back to back.
His name is Gilbert Strang. The course is MIT 18.06 Linear Algebra.
Every machine learning engineer, every data scientist, every quant, every self-taught programmer who actually understands how AI works learned the math from this one man. Most of them never set foot on MIT's campus. They just opened a free playlist on YouTube and let him teach.
Here's the story almost nobody tells you.
Strang joined the MIT math faculty in 1962. He retired in 2023. That is 61 years of standing at the same chalkboard teaching the same subject to 18-year-olds.
The interesting part is what he did when MIT launched OpenCourseWare in 2002. Most professors were skeptical. They worried that putting their lectures online would make their classrooms irrelevant. Strang did not hesitate. He said his life's mission was to open mathematics to students everywhere. He filmed every lecture and gave it away.
The decision quietly changed how the world learns math.
For decades linear algebra was taught the wrong way. Professors started with abstract vector spaces and proofs about field axioms. Students drowned in the abstraction. Most never recovered. They walked out believing they were bad at math when they had simply been taught in an order that nobody's brain is built to absorb.
Strang inverted the entire curriculum.
He started with matrix multiplication. Something you can write down on paper. Something you can compute by hand. Something you can see. Then he showed his students that everything else in linear algebra eigenvectors, singular value decomposition, orthogonality, the four fundamental subspaces was just a different lens for understanding what the matrix was actually doing under the hood.
His rule was strict. If a student could not explain a concept using a concrete 3 by 3 example, that student did not actually understand the concept yet. The abstraction was supposed to come last, not first. The intuition was the foundation. The proofs were just confirmation that the intuition was correct.
The second thing Strang changed was the classroom itself. He said please and thank you to his students. Every single lecture. He paused mid-derivation to ask "am I OK?" to check if anyone was lost. He never used the word "obviously" or "trivially" because he knew exactly what those words do to a student who is one step behind. He treated 19-year-olds learning math for the first time the way he treated his own colleagues. With patience. With respect. With the assumption that they belonged in the room.
For 62 years.
The result is something that has never happened in the history of education. A single math professor became the default teacher of his subject for the entire planet.
Universities in India, China, Brazil, Nigeria, every country with a computer science department, started telling their own students to just watch Strang's lectures. The University of Illinois revised its linear algebra course to do almost no in-person lecturing. The reason was honest. The professor said they could not compete with the videos.
His final lecture was in May 2023.
The auditorium was packed with students who had never met him before. He walked to the chalkboard, taught for an hour, and at the end the entire room stood and applauded. He looked confused for a moment, like he genuinely did not understand why they were cheering. Then he smiled and waved them off and walked out.
His written comment under the YouTube video of that final lecture was four sentences long. He said teaching had been a wonderful life. He said he was grateful to everyone who saw the importance of linear algebra. He said the movement of teaching it well would continue because it was right.
That was it. No book promotion. No farewell speech. No legacy management.
The man whose teaching is the foundation of modern AI just thanked the audience and went home.
20 million views. Zero ego. The entire engine of the AI revolution sits on top of math that millions of people learned for free from one quiet professor in Cambridge.
The course is still on MIT OpenCourseWare. Every lecture, every problem set, every exam, every solution. Free.
The most important math course of the 21st century is sitting one click away from you. Most people will never open it.
Mathematics.
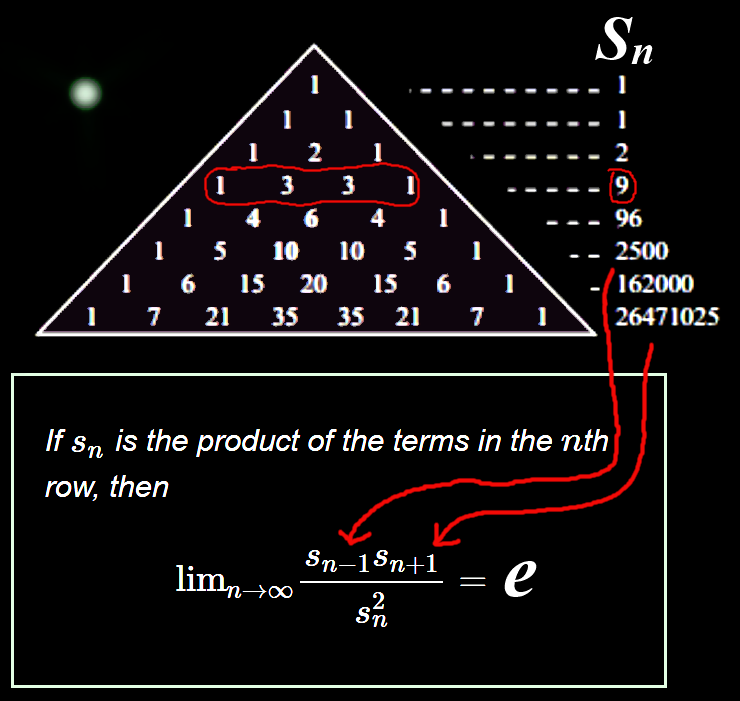
Shiver in ecstasy. "Harlan Brothers discovered the mathematical constant e hiding in Pascal's Triangle. (Compute the products of all elements in a row.)"
Source: Alexander Bogomolny, https://t.co/jkrn1hnXuW
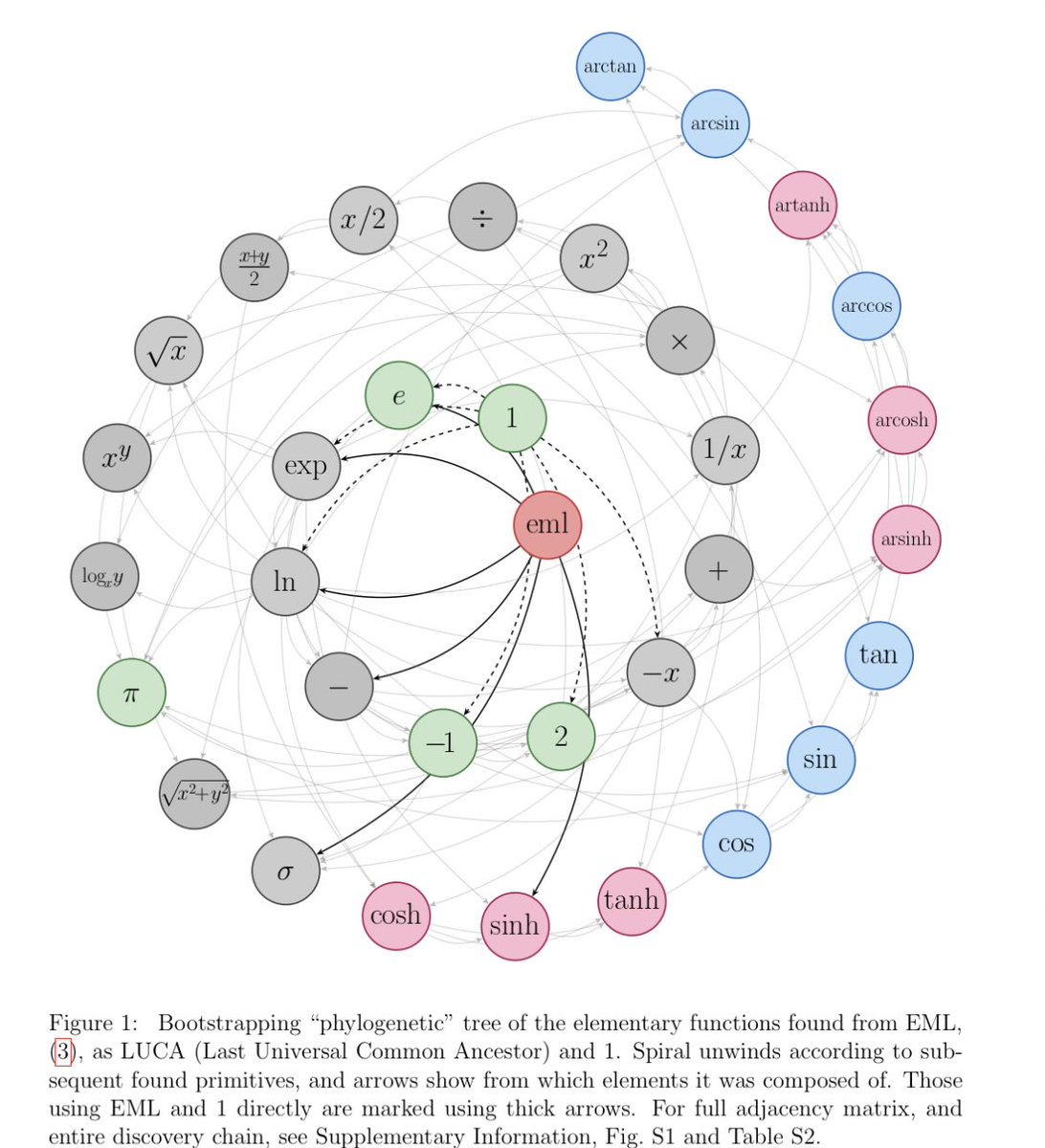
Polski naukowiec napisał ciekawą pracę - i nie bójmy się nazwać jej przełomową. Przez setki lat matematyka miała dziesiątki “podstawowych” funkcji jak sinus, cosinus, logarytm, pierwiastek, eksponenta. Znacie to ze szkoły. Wiadomo o co chodzi. Fizyk z Uniwersytetu Jagiellońskiego właśnie pokazał, że to wszystko jeden operator: E(x, y) = exp(x) - ln(y), oraz 1.
Sin, cos, π - wszystko z tego pięknie wynika, wystarczy odpowiednio zagnieździć. Natura ukryła najprostszy możliwy zapis rzeczywistości. I znaleźliśmy go przez przypadek. Całość jest piękna i wspaniała, a słowo „przełomowe” nie stanowi tu marketingowego buzzworda.
Przykładowo zamiast pisać π czy 3.14 można teraz elegancko E(E(E(1,E(E(1,E(1,E(E(1,E(E(1,E(E(1,E(1,E(E(1,1),1))),1)),E(E(E(E(E(1,E(E(1,E(1,E(E(1,E(E(E(1,E(E(1,E(1,E(E(1,1),1))),1)),E(E(1,E(E(1,E(E(1,E(E(1,1),1)),E(E(E(1,E(E(1,E(1,E(E(1,1),1))),1)),E(1,1)),1))),1)),1)),1)),1))),1)),E(E(E(1,E(E(1,E(1,E(E(1,1),1))),1)),E(E(1,E(E(1,E(1,E(E(1,E(E(1,E(E(1,E(1,E(E(1,1),1))),1)),E(1,1))),1))),1)),1)),1)),1),1),1))),1))),1)),E(E(E(1,E(E(1,E(1,E(E(1,1),1))),1)),E(E(1,E(E(1,E(1,E(E(1,E(E(1,E(E(1,E(1,E(E(1,1),1))),1)),E(1,1))),1))),1)),1)),1)),1)
Algorithm Visualizer devrait être dans la boîte à outils de tout·e développeur·se qui apprend ou enseigne des algos — la visualisation en direct à partir du code rend les mécanismes abstraits vraiment lisibles.
https://t.co/LMycabGIbQ
In 1948, a 32-year-old at Bell Labs published a paper nobody fully understood.
Engineers found it too mathematical. Mathematicians found it too engineering-focused. One prominent mathematician reviewed it negatively.
That paper - "A Mathematical Theory of Communication", became the founding document of the digital age.
The man was Claude Shannon. Father of Information Theory.
At 21, he wrote the most important master's thesis of the 20th century.
Working at MIT on an early mechanical computer, Shannon noticed its relay switches had exactly two states - open or closed. He had just taken a philosophy course introducing Boolean algebra, which also operated on two values: true and false.
Nobody had ever connected these two things.
His 1937 thesis proved that Boolean algebra and electrical circuits are mathematically identical, and that any logical operation could be built from simple switches.
Howard Gardner called it "possibly the most important, and also the most famous, master's thesis of the century."
Every digital computer ever built traces back to this insight.
At 29, he proved that perfect encryption exists.
During WWII, Shannon worked on classified cryptography at Bell Labs. His work contributed to SIGSALY, the secure voice system used for confidential communications between Roosevelt and Churchill.
In a classified 1945 memorandum, he mathematically proved the one-time pad provides perfect secrecy, unbreakable not just computationally, but provably, permanently, against an adversary with infinite power.
When declassified in 1949, it transformed cryptography from an art into a science. It laid the foundations for DES, AES, and every modern encryption standard.
At 32, he defined what information is.
His 1948 paper introduced one equation:
H = −Σ p(x) log p(x)
Shannon entropy. The average uncertainty in a probability distribution. The minimum bits required to encode a message.
Three things followed:
> He defined the bit - the fundamental unit of all information. His colleague John Tukey coined the name.
> He proved the channel capacity theorem, every communication channel has a maximum rate of reliable transmission. You can approach it. You can never exceed it.
> He unified telegraph, telephone, and radio into a single mathematical framework for the first time.
Robert Lucky of Bell Labs called it the greatest work "in the annals of technological thought."
Where his equation lives in AI today:
Cross-entropy loss - the function training every classifier and language model, is derived directly from H. Decision tree splits use information gain, which is H applied to data. Perplexity, the standard LLM evaluation metric, is an exponentiation of cross-entropy.
Every time a neural network trains, Shannon's formula runs inside it.
He also built the first AI learning device.
In 1950, Shannon built Theseus, a mechanical mouse that navigated a maze through trial and error, learned the correct path, and repeated it perfectly. Mazin Gilbert of Bell Labs said: "Theseus inspired the whole field of AI."
That same year he published the first paper on programming a computer to play chess. He co-organized the 1956 Dartmouth Workshop, the founding event of AI as a field.
The man:
He rode a unicycle through Bell Labs hallways while juggling. He built a flame-throwing trumpet, a rocket-powered Frisbee, and Styrofoam shoes to walk on the lake behind his house.
He called his home Entropy House.
When asked what motivated him: "I was motivated by curiosity. Never by the desire for financial gain. I just wondered how things were put together."
In 1985, he appeared unexpectedly at a conference in Brighton. The crowd mobbed him for autographs. Persuaded to speak at the banquet, he talked briefly, then pulled three balls from his pockets and juggled instead.
One engineer said: "It was as if Newton had showed up at a physics conference."
He died in 2001 after a decade with Alzheimer's, the cruel irony of information slowly leaving the mind of the man who defined what information was.
Claude, the AI model, is named after Claude Shannon, the mathematician who laid the foundation for the digital world we rely on today.