If you care about @PyTorch, @vllm_project, @sgl_project, and the systems that make inference fly, you’ll want to see this lineup.
Our first featured speakers for Advancing AI 2026 (Developer Track) are live:
🔹@matthew_d_white (@linuxfoundation / PyTorch Foundation)
🔹@ying11231 (@RadixArk / SGLang)
🔹@simon_mo_ (@Inferact / vLLM)
More speakers and hands-on sessions will be announced soon.
📆 July 22–23, 2026
📍 San Francisco
Register Now: https://t.co/j3NVeP39KR
#AdvancingAI #AMDevs
Not every AI workload needs to live in the cloud. The future of AI is hybrid.
This blog explores the rise of “Agent Computers” and why developers are increasingly looking at local inference for better cost control, lower latency, and continuous AI workflows.
https://t.co/CHCqFRH5ym
Local AI is changing how developers build and deploy intelligent systems.
@jackhuynh shares how the new AMD Ryzen AI Halo is helping redefine what #AMDevs can build and run locally. 👇
An open-source 3D printer made from 92% LEGO bricks that actually works. 18-year-old @hackclub student Adam built Studprint, which he designed and rendered on a PC powered by AMD Ryzen 5 7600X.
Full open-source build on @github here: https://t.co/5Kc0oL6hup
@MacroEngineered I’ve been on board with this approach for a while :D https://t.co/d24cyYckS3. Eventually I will get around to sharing all of the stuff I haven’t pushed to the public repo… There may be a branch with some fun stuff buried within.
Definitely written a _lot_ of HCL with LLMs!
OpenClaw + open-source models + AMD GPUs = a very fun workshop
Shoutout to Eda Zhou and Mahdi Ghodsi for the deep dive (and the mini lobsters 🦞)
Good vibes all around at @DeepLearningAI AI Dev '26!
codegen is cheap now. performance isn’t: most generated kernels are kinda mid.
iteration and feedback are missing for both the agent and RL env layers.
so we're open-sourcing Apex: an end-to-end agent using Claude Code + Codex to effectively optimize AMD kernels, instead of one-shotting them
https://t.co/knwjrfJGdP
As the person in charge of ROCm, @AMD's answer to CUDA, @AnushElangovan is singularly critical to the challenger taking any share from the market leader. Impressive, then, that he still answers every anonymous "ROCm sucks" tweet personally. Interview:
https://t.co/idlQN8JlOP
18x IMPROVEMENT ALERT🚀 In under 30 days, AMD was able to improvement Kimi K2.5 1T MXFP4 interactivity by up to 18x when iso-throughput. The main changes are in PR number 35850 AMD fixed their vLLM AITER integration to support the Kimi K2.5 MLA which uses num_head=8 for TP8 & num_head=16 for TP4 along with general GEMM tuning. All of these bug fixes & perf tuning are upstreamed & already in the vLLM 0.18 release. Great work to Chuan Li & @AnushElangovan Speed is the Moat 🔥
AMD Engineer Leverages AI To Help Make A Pure-Python AMD GPU User-Space Driver
Python user-space AMD GPU driver written in part by AI.... What?!?!
https://t.co/1ksDIers6x
Due to optimizations in AMD's MoRI inference communication library & better kernels AMD performance has 1.5x in the span of 30 days. These optimizations for MoE dispatch, MoE combine, kvcache transfer comms have been upstreamed in SGLang for everyone to use in PR 17012, 14626, 18437 etc. MoRI is AMD's inference comms library built from first principles by their 10x china team! In the age of inference, developer velocity of inference optimizations matters a lot & InferenceX™ is our research platform to continuously track the performance.
Inspired by @__tinygrad__ userspace AMD driver, I clauded a userspace driver for some stress testing of SDMA and compute/comms overlap debug.
I didn't open the editor once. Agents are the great equalizer in software. And Speed is the moat.
https://t.co/pc9dDWKTnP
And now it's documented. For people serious about performance, this is a real AMD advantage. Thanks @AnushElangovan for pushing this through! Code is here: https://t.co/WEEj9EVZe8









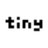


















![network_phil's tweet photo. [NEW BLOG] Rail-Optimized Networking for AI Training Workloads
https://t.co/RIX0Q75mve https://t.co/eOwKB3VBC7](https://pbs.twimg.com/media/HF9jURuWYAAs1IG.jpg)