Or go to the Presidio, jump in the ocean, get a coffee at The Mill, watch sunset at Twin Peaks, ride a bike anywhere, see live music, eat a burrito, take a grass nap in GG Park, have beer at The Page, watch the Bay Bridge lights, wander Chinatown, wander Ferry building, run across GG Bridge, walk Fort Funston, eat the best meal of your life with friends…drive any direction for 2hrs. And be deeply grateful for the heavenscape you live in.
Can we build a blind, *unlinkable inference* layer where ChatGPT/Claude/Gemini can't tell which call came from which users, like a “VPN for AI inference”?
Yes! Blog post below + we built it into open source infra/chat app and served >15k prompts at Stanford so far. How it helps with AI user privacy:
# The AI user privacy problem
If you ask AI to analyze your ChatGPT history today, it’s surprisingly easy to infer your demographics, health, immigration status, and political beliefs. Every prompt we send accumulates into an (identity-linked) profile that the AI lab controls completely and indefinitely. At a minimum this is a goldmine for ads (as we know now). A bigger issue is the concentration of power: AI labs can easily become (or asked to become) a Cambridge Analytica, whistleblow your immigration status, or work with health insurance to adjust your premium if they so choose.
This is a uniquely worse problem than search engines because your average query is now more revealing (not just keywords), interactive, and intelligence is now cheap. Despite this, most of us still want these remote models; they’re just too good and convenient! (this is aka the "privacy paradox".)
# Unlinkable inference as a user privacy architecture
The idea of unlinkable inference is to add privacy while preserving access to the remote models controlled by someone else. A “privacy wrapper” or “VPN for AI inference”, so to speak.
Concretely, it’s a blind inference middle layer that:
(1) consists of decentralized proxies that anyone can operate;
(2) blindly authenticates requests (via blind signatures / RFC9474,9578) so requests are provably sandboxed from each other and from user identity;
(3) relays prompts over randomly chosen proxies that don’t see or log traffic (via client-side ephemeral keys or hosting in TEEs); and
(4) the provider simply sees a mixed pool of anonymous prompts from the proxies. No state, pseudonyms, or linkable metadata.
If you squint, an unlinkable inference layer is essentially a vendor for per-request, anonymous, ephemeral AI access credentials (for users or agents alike). It partitions your context so that user tracking is drastically harder.
Obviously, unlinkability isn’t a silver bullet: the prompt itself still goes to the remote model and can leak privacy (so don't use our chat app for a therapy session!). It aims to combat *longitudinal tracking* as a major threat to user privacy, and its statistical power increases quickly by mixing more users and requests.
Unlinkability can be applied at any granularity. For an AI chat app, you can unlinkably request a fresh ephemeral key for every session so tracking is virtually impossible.
# The Open Anonymity Project
We started this project with the belief that intelligence should be a truly public utility. Like water and electricity, providers should be compensated by usage, not who you are or what you do with it. We think unlinkable inference is a first step towards this “intelligence neutrality”.
# Try it out! It’s quite practical
- Chat app “oa-chat”: https://t.co/ELf8LvxFzX
(<20 seconds to get going)
- Blog post that should be a fun read: https://t.co/OwFmyFlZH5
- Project page: https://t.co/Swerz1xDE2
- GitHub: https://t.co/38CeKajCy2
New paper, w/@AlecRad
Models acquire a lot of capabilities during pretraining.
We show that we can precisely shape what they learn simply by filtering their training data at the token level.
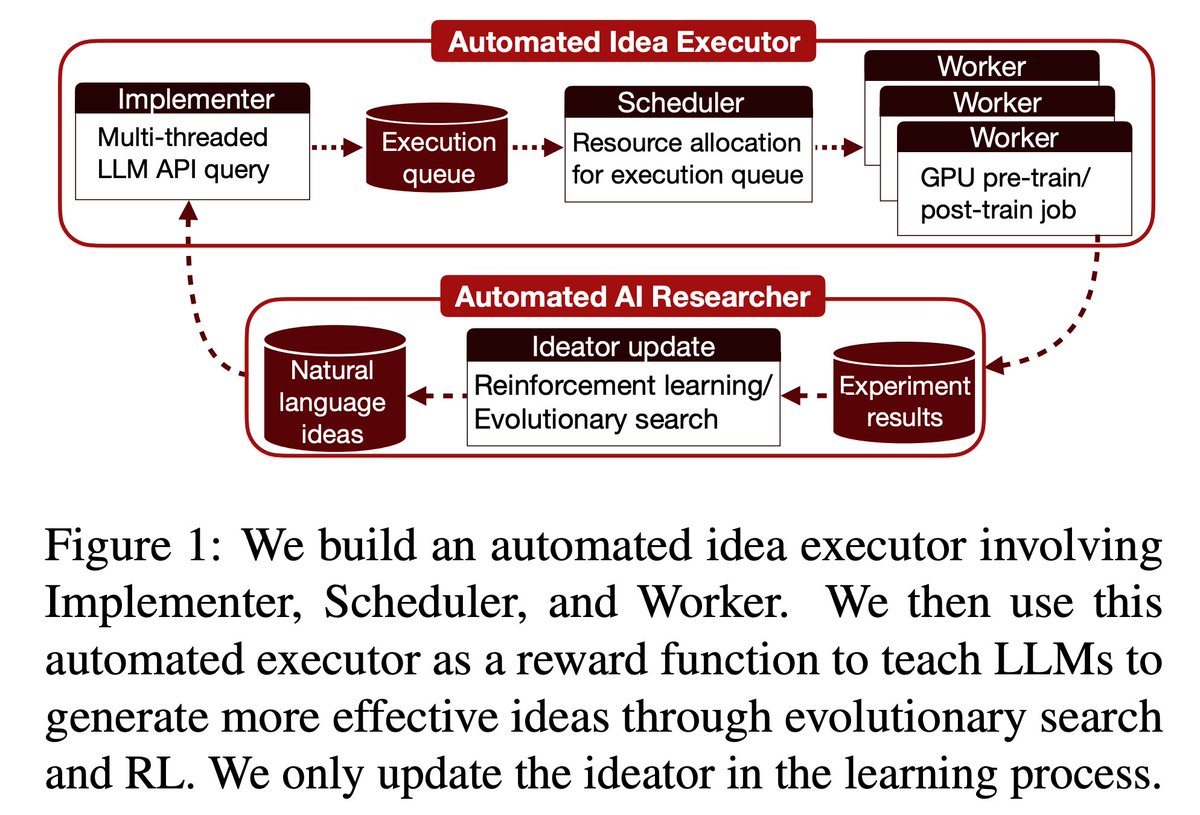
Can LLMs automate frontier LLM research, like pre-training and post-training?
In our new paper, LLMs found post-training methods that beat GRPO (69.4% vs 48.0%), and pre-training recipes faster than nanoGPT (19.7 minutes vs 35.9 minutes).
1/
🫡 new paper
neurons can be a sparse and interpretable basis for circuit tracing, once you make the right decisions about which neurons and how you circuit trace!
i'm excited for how this affects future progress on circuits + automating interp
@khoomeik no reason for this correspondence to exist, but ngl it bothers me ever so slightly that the length of the differing part in each of the graphemes doesn’t correspond to the position of the tongue 🫠
Introducing Generative Interfaces - a new paradigm beyond chatbots.
We generate interfaces on the fly to better facilitate LLM interaction, so no more passive reading of long text blocks.
Adaptive and Interactive: creates the form that best adapts to your goals and needs!
New paper! We explore a radical paradigm for AI evals: assessing LLMs on *unsolved* questions.
Instead of contrived exams where progress ≠ value, we eval LLMs on organic, unsolved problems via reference-free LLM validation & community verification. LLMs solved ~10/500 so far:
Soon, AI agents will act for us—collaborating, negotiating, and sharing data. But can they truly protect our privacy?
We simulate privacy-critical scenarios, using alternating search to evolve attacks and defenses, uncovering severe vulnerabilities and building protections.
flying to Vienna 🇦🇹 for ACL to present Genie Worksheets (Monday 11am)!
come and say hi if you want to talk about how to create controllable and reliable application layers on top of LLMs, knowledge discovery and curation, or just wanna hang
New #ACL2025NLP Paper! 🎉
Curious what AI thinks about YOU?
We interact with AI every day, offering all kinds of feedback, both implicit ✏️ and explicit 👍. What if we used this feedback to personalize your AI assistant to you?
Introducing SynthesizeMe! An approach for creating natural language personal user models from your interactions.
🧵
new paper! 🫡
why are state space models (SSMs) worse than Transformers at recall over their context? this is a question about the mechanisms underlying model behaviour: therefore, we propose using mechanistic evaluations to answer it!
An LLM generates an article verbatim—did it “train on” the article?
It’s complicated: under n-gram definitions of train-set inclusion, LLMs can complete “unseen” texts—both after data deletion and adding “gibberish” data. Our results impact unlearning, MIAs & data transparency🧵
New paper on synthetic pretraining!
We show LMs can synthesize their own thoughts for more data-efficient pretraining, bootstrapping their capabilities on limited, task-agnostic data. We call this new paradigm “reasoning to learn”.
https://t.co/yxBMwccAUd
Here’s how it works🧵
new paper! 🫡
we introduce 🪓AxBench, a scalable benchmark that evaluates interpretability techniques on two axes: concept detection and model steering.
we find that:
🥇prompting and finetuning are still best
🥈supervised interp methods are effective
😮SAEs lag behind
a big collab on unlearning led by @katherine1ee and @afedercooper!!
it always helps to ask *why* and *how* a specific new technology will tangibly help in practice, or if it’s really just a solution searching for a problem. this is especially true for unlearning as of today.
To what extent can we trade additional parallel compute for lower sampling latency in diffusion models? 🤔
A lot, when you resort to multigrid methods!
Presenting Self-Refining Diffusion Samplers (SRDS) to accelerate diffusion sampling through Parareal iterations! 📈 (1/n)
⚡️ As we demonstrate for pre-trained diffusion models, the early convergence of this refinement procedure speeds up generation for instance by up to 1.7x on a 25-step StableDiffusion-v2 benchmark and up to 4.3x on longer trajectories! (3/n)