"Transformers" by Daniel Jurafsky and James H. Martin is one of the clearest and most mathematically grounded introductions to the Transformer architecture I have ever read.
Chapter 8 introduces the Transformer as the standard architecture behind modern large language models. What makes this chapter particularly interesting is its step-by-step presentation of the underlying mechanisms: contextual embeddings, self-attention, query, key and value vectors, scaled dot-product attention, multi-head attention, residual streams, feedforward layers, layer normalization, masking, and the parallel matrix formulation of attention.
In particular, the treatment of attention as a weighted sum of contextual representations is especially valuable. The chapter first develops an intuitive, simplified view of attention and then gradually derives the full formulation using the Q, K, and V matrices. This approach makes it easier to understand what is actually happening inside the architecture from an algebraic and matrix-based perspective, rather than simply viewing the usual block diagrams.
I think it is an excellent resource for anyone interested in understanding how Transformers work from linguistic, mathematical, and computational perspectives.
https://t.co/3fitdPy6Fv
Three years ago was when @citrini told me to buy $CLS too. He also got me into $SMCI at 2x NTM earnings for “making boxes for NVDA” and rode it from $80 to $1200. And $AAOI since $4. Bubbles are good if you are early. @patrick_oshag really should interview him on @InvestLikeBest.
To young engineers and entrepreneurs who are curious about foundation models:
Take this course:
https://t.co/dF05jWPICS
Before that, learn basic Python and machine learning.
Learn distributed systems from MIT:
https://t.co/QT8yutibq7
Learn how to use modern coding tools from Stanford:
https://t.co/7J9welvbmx
Some of the best knowledge in the world today is open source. You just need 3–4 like-minded people to start building a company.
Advice for AI engineers 💡
The best way to learn local AI is to build with local AI.
7 hands-on webinars from the last 7 months. All open-source. All small LFM models. All running on-device.
The full collection 🧵 (1/7)↓
I want to offer some unsolicited advice to computer vision researchers jumping into robotics. Don't focus too much on VLMs, VLAs etc. That's fine, but the real action is at the sensorimotor level. Most of the open problems in robotics are in manipulation, which is about hand-object interaction, and contacts and forces are central. Proprioception and tactile sensing are as important as vision. Don't get seduced by cherry-picked demos. You can't do robotics without doing robotics.
As an AI Engineer. Please learn
>Harness engineering, not just prompt engineering
>Context engineering, not just long prompts
>Prompt caching vs. semantic caching tradeoffs
>KV cache management, eviction, reuse, and memory pressure at scale
>Prefill vs. decode latency and why they optimize differently
>Continuous batching, paged attention, and throughput optimization
>Speculative decoding vs. quantization vs. distillation tradeoffs
>INT8, INT4, FP8, AWQ, GPTQ, and when quantization hurts quality
>Structured output failures, schema validation, repair loops, and fallback chains
>Function calling reliability, tool contracts, argument validation, and idempotency
>Agent guardrails, loop budgets, tool budgets, and termination conditions
>Model routing, graceful fallback logic, and degraded-mode UX
>RAG architecture: chunking, embeddings, hybrid search, reranking, and freshness
>Retrieval evals: recall, precision, grounding, attribution, and citation quality
>Evals: golden sets, regression tests, adversarial tests, LLM-as-judge, and human evals
>LLM observability as a first-class discipline: traces, spans, tokens, latency, errors, and drift
>Cost attribution per feature, workflow, tenant, and user journey not just per model
>Safety engineering: prompt injection defense, data leakage prevention, and permission boundaries
>Multi-tenant isolation, cache safety, and cross-user context contamination prevention
>Fine-tuning vs. in-context learning vs. RAG vs. distillation and when each is the wrong tool
>Latency, quality, cost, and reliability tradeoffs across the full inference stack
>Production failure modes: hallucinated tool calls, malformed JSON, stale retrieval, runaway agents, and silent eval regressions
One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]
Video lectures, Toronto ECE 1508 Applied Deep Learning winter 2026, by Ali Bereyhi
https://t.co/FMUDrheYcc
https://t.co/J2nmfLc7EL
https://t.co/TJCeQ6afNQ
.
Here is what production quality Python code actually looks like.
You'll learn how principles like cohesion, encapsulation, loose coupling, and simplicity show up in real code.
So if you want to write Python like a more experienced developer, watch this video.
I promise this will be the best 20 min you spend today! Robotics: Endgame, the sequel to my last year's Sequoia AI Ascent talk, "Physical Turing Test". I laid out the roadmap for solving Physical AGI as a simple parallel to the LLM success story. Be a good scientist, copy homework ;)
And stay till the end, more easter eggs and predictions for your polymarket!
00:30 DGX-1 origin story at OpenAI, I was there in 2016 signing with Jensen and Elon. Heading to the Computer History Museum!
01:42 The Great Parallel
03:31 Robotics, the Endgame
03:39 Why VLAs fall short
04:32 Video world models as the 2nd pretraining paradigm
06:09 World Action Models (WAM)
07:46 Strategies for robot data collection and the FSD equivalent to physical data flywheel for robot manipulation
11:06 EgoScale and the Dexterity Scaling Law we discovered recently
14:00 Physical RL: bridging the last mile
15:39 DreamDojo: an end-to-end neural physics engine for scaling RL in silico
17:00 Civilizational Technology Tree and my predictions for the near future. Spoiler: it's closer than you think.
Thanks to my friends at Sequoia for inviting me back to AI Ascent this year! I had a blast! Last year's talk is attached in the thread if you missed it.
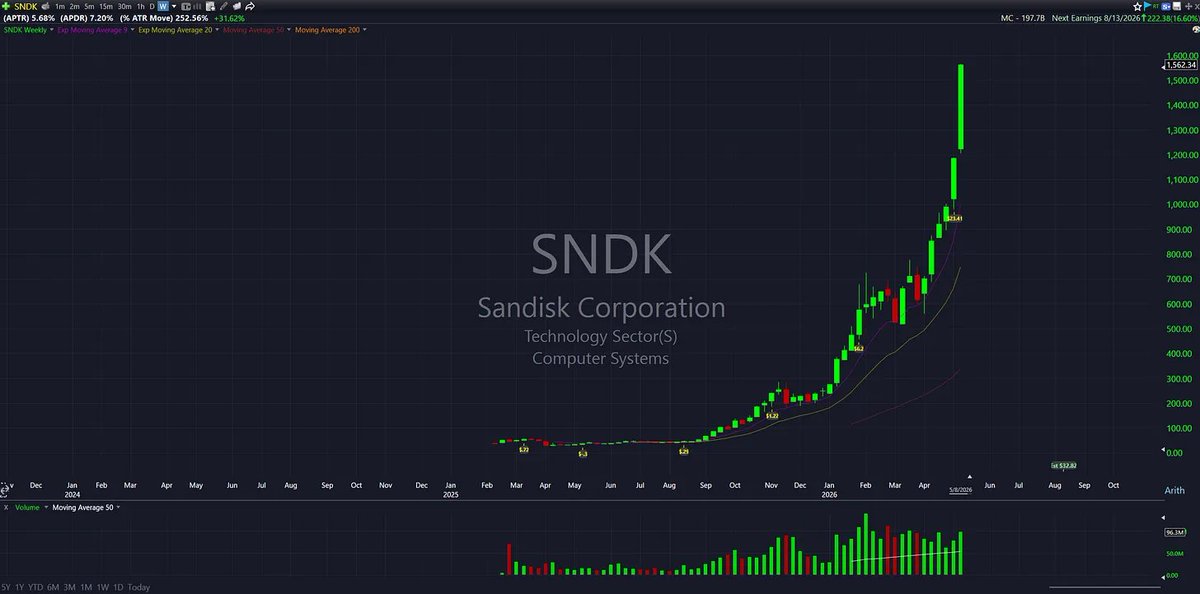
The window of opportunity is open this week for parabolic reversals in $SNDK $MU and solana:JCEmtMhYCuijq6t3bXbZeyr4566RYmsLaSdr6pYd79Rt
Let's see if this post is more hated than the parabolic short write-up I did on Silver in late January....
Jokes aside, I wanted to share my thoughts as I have during parabolic moves over the years with stuff like $SMCI $NVDA $MSTR $SLV $GLD $KORU $CAR etc, especially if I can help someone who is riding a large unrealized gain take advantage and trim into these parabolic extensions.
Early last week, I shared a screenshot of a spreadsheet I had saved from a study I did on the specific extension metrics in which many historic parabolic moves peaked. I also noted that it was too early to short the semiconductors as that they had not filled out the criteria required for a parabolic short.
Below is the same spreadsheet, but included is $SNDK $MU and solana:JCEmtMhYCuijq6t3bXbZeyr4566RYmsLaSdr6pYd79Rt updated with their extensions as of Friday's close. The green highlighted boxes represent above the average in which all the study examples peaked at.
As you can see they are not all quite above average yet, but any continued hype and momentum early this week and all three of these names will very likely be in play.
One characteristic that is extremely important when identifying a parabolic advance is consecutive weeks of range expansion. We recently saw this with Silver in January when it put together 3 consecutive weeks of range expansion before it's climax, as well as many more classic, model book examples throughout the years.
Consecutive weeks of range expansion signal exponential price progression, a hallmark of parabolic curves. It is a week by week build up into a climactic reversal. The cherry on top is a signifigant range expansion week on the 3rd or 4th week of the burst, which is typically the final week of the move.
Here are the last 3-4 weeks of percentage gains for these names:
$SNDK
Week 1 (+7.48%)
Week 2 (+19.91%)
Week 3 (+31.62%)
$MU
Week 1 (+8.20%)
Week 2 (+9.15%)
Week 3 (+9.16%)
Week 4 (+37.73%)
solana:JCEmtMhYCuijq6t3bXbZeyr4566RYmsLaSdr6pYd79Rt
Week 1 (+9.81%)
Week 2 (+20.50%)
Week 3 (+20.69%)
Week 4 (+25.40%)
Textbook parabolic price progression over consecutive weeks on all three of them.
After that final 3rd or 4th week of signifigant range expansion, you then look for a similar parabolic burst on the daily timeframe. $SNDK $MU and solana:JCEmtMhYCuijq6t3bXbZeyr4566RYmsLaSdr6pYd79Rt all closed down on Thursday, before exploding higher on Friday. Need at least 1-2 more large, consecutive days higher for these to trigger a climactic reversal.
We also witnessed what felt like complete upside panic and FOMO in the leading semiconductors on Friday. One example being the news that hit at 1pm stating that Apple and Intel reached a preliminary chip-making agreement, which led to a near +13% gain in just 20 minutes...
Moments after that headline, Trump said "Go and buy a Dell", which sent $DELL soaring an entire 200% ATR move in just 30 minutes.
This is typically the type of price action and hype you see during the final stage of a parabolic burst. Not to mention the absurd volume of options being traded on these names as we approach May OPEX this Friday...
To close this out, we also have the $QQQ at 9.91 ATR multiples above the 50-day moving average as of Fridays close, a level of extension never before seen since its inception in March of 1999. I have no doubt this market can continue higher this year, but this print only helps add conviction to the names potentially setting up for a opportunity into this week.
To clarify, the parabolic short is an extraordinarily high-probability mean reversion opportunity, that can sometimes lead to secular tops, but not always. I have no clue where these stocks will be a month or a year from now, but I know my setups when I see them.
NDIVIA Isaac Sim + Isaac Lab gives you a full sim-to-real pipeline - design, train, and deploy robot policies without costly physical iteration. Here's a complete breakdown of how it works. 🧵
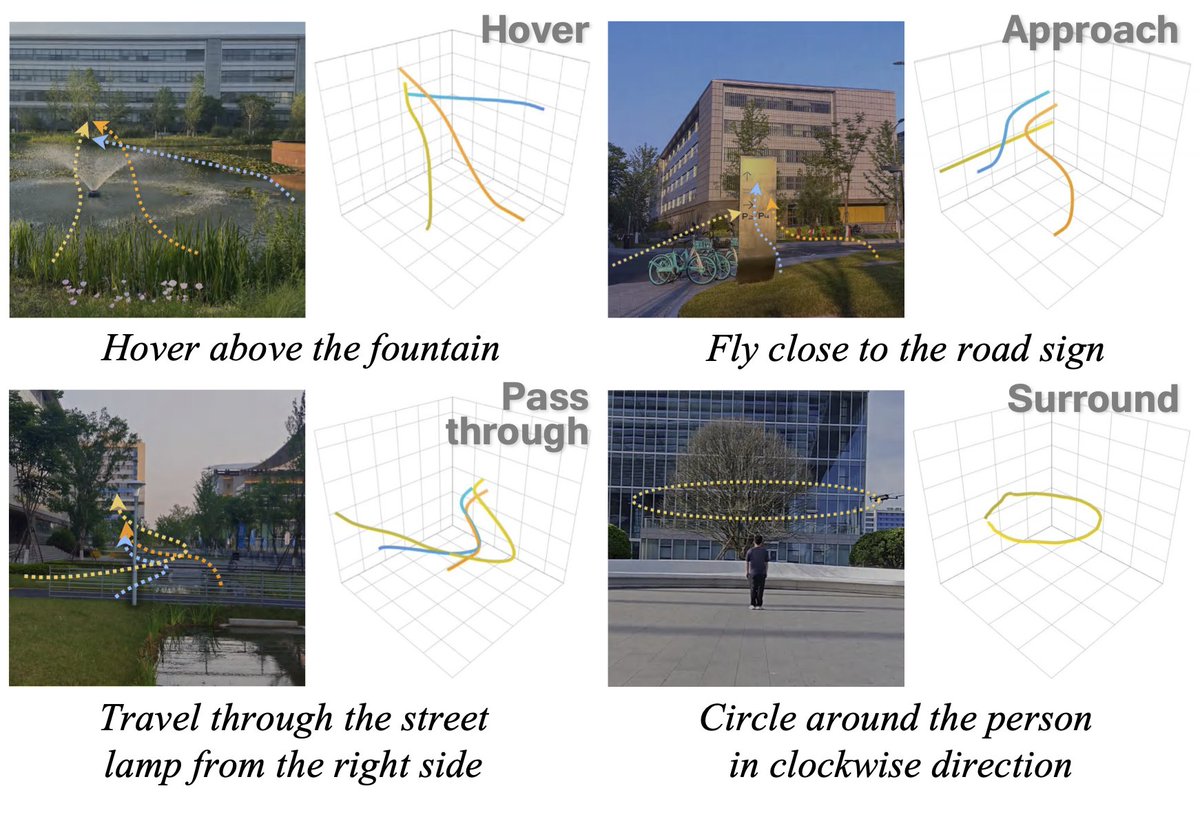
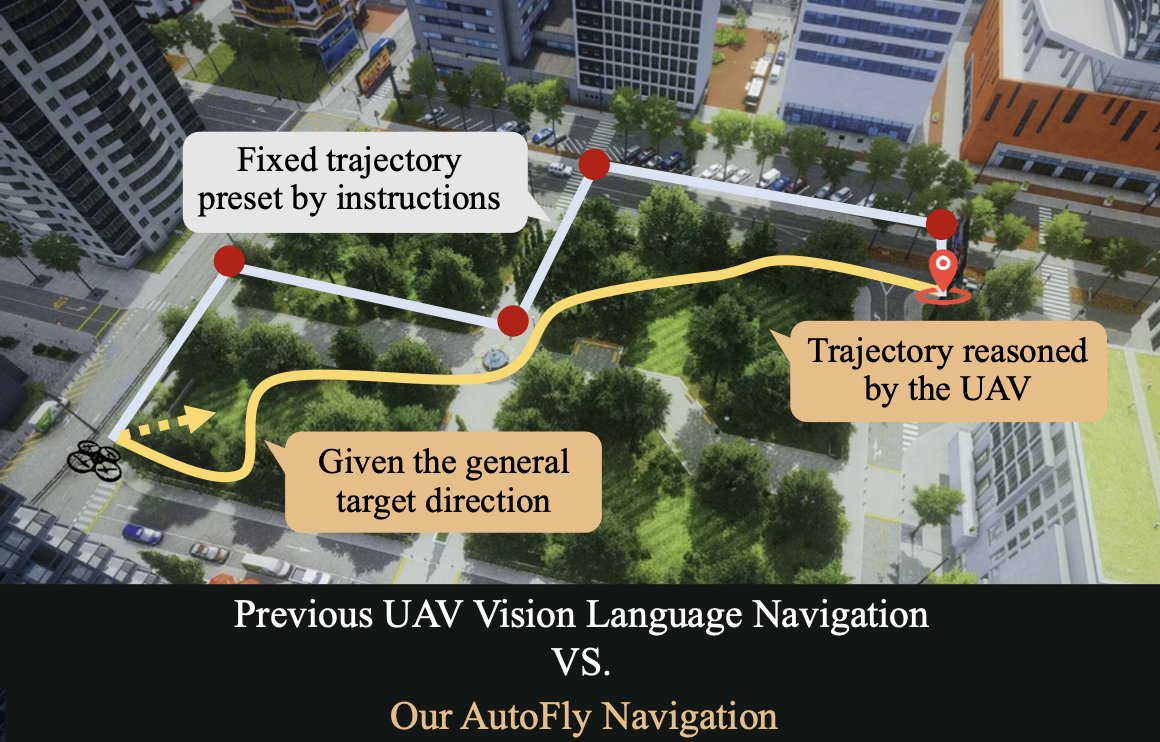
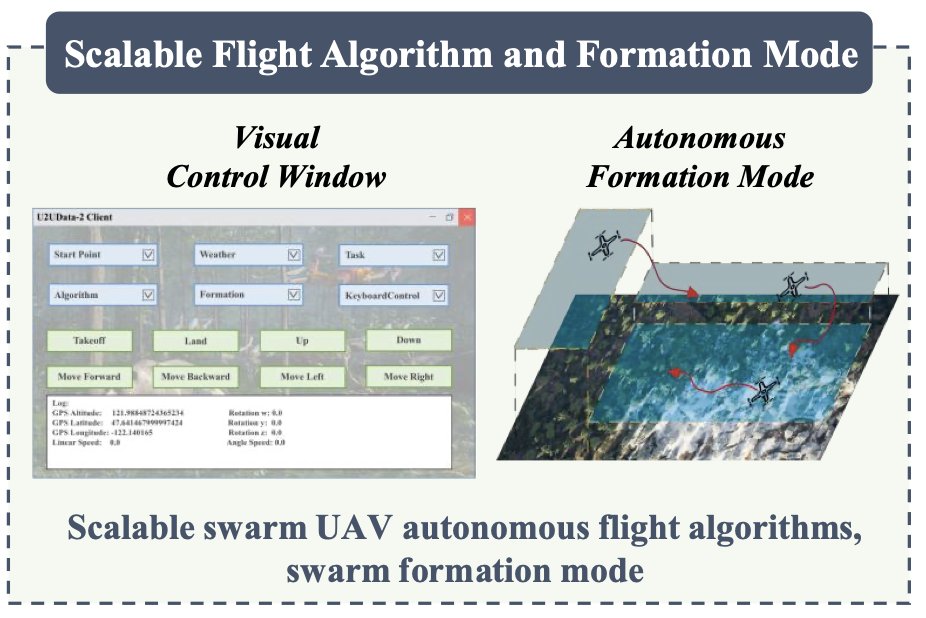
🚨Awesome UAV Datasets
(specifically curated for training VLA's)
> Synthetic UAV Flight Trajectories — Hugging Face dataset with 5,000+ synthetic UAV trajectories over ~20 hours of flight time
https://t.co/EEPjciW8O2
> U2UData+ / U2UData-2 — Large-scale swarm UAV autonomous flight dataset: 15 UAVs, 12 scenes, 720 traces, 120 hours, 600 seconds per trajectory, with RGB, depth/LiDAR, and environmental signals
https://t.co/mtgAiSq88l
> CognitiveDrone Dataset — 8,062 simulated UAV flight trajectories for VLA-style drone control, split across human recognition, symbol understanding, and reasoning tasks
https://t.co/rzint94UhL
> AutoFly Dataset — VLA-style UAV autonomous navigation dataset with 13K+ episodes and 2.5M image-language-action triplets, built from expert demonstrations and simulated trajectories, plus 1K real-world flight episodes for sim-to-real validation
https://t.co/tNkh44ivC0
> UAV-Flow / UAV-Flow-Sim — Real-world language-conditioned UAV imitation-learning benchmark with 30,692 real UAV flight trajectories and 10,109 simulated trajectories, where each sample includes language instruction, egocentric visual observation, and 6-DoF UAV state/action trajectories
https://t.co/yRGwTT1eFE

























![AndrewYNg's tweet photo. One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]](https://pbs.twimg.com/media/HJvWmCHagAAnTxQ.jpg)