Day 2 of VLX, VLX-Seek: improving VLM fine-grained perception via region reference instead of coordinate generation!
VLMs are good at understanding what is in an image, but still struggle to pinpoint where it is.
Coordinate generation is fragile: long numeric outputs, formatting errors, missed objects, and hallucinated boxes.
VLX-Seek takes a different path: region reference instead of coordinate generation.
It retrieves candidate regions, turns them into language-addressable region tokens, and lets the model select <region_i> instead of generating [x1, y1, x2, y2].
From detection and referring expressions to counting, OCR, and embodied interaction, VLX-Seek pushes VLMs from “seeing the image” toward “grounding objects in space.”
Github:https://t.co/JUl9jPttwg
huggingface:https://t.co/rrig30Dn8e
#VLX #VLXModel #VLXSeries #StreamingMultimodal #OnDeviceAI #PhysicalAI #EmbodiedAI #EdgeAI #VisionLanguageModel #AI
We’re excited to release VLX, starting with VLX-Flow: a streaming vision-language model designed for real-time video understanding!
Long context isn't the cure for live video streams. Reprocessing history blows up VRAM, while sparse sampling drops crucial causal details.
The fix? Incremental memory updates.
This is VLX-Flow: video stream -> memory state -> interaction.
It continuously tracks "what just happened," so Q&A and alerts can trigger anytime.
Github :https://t.co/DD7W3ZLXfD
huggingface:https://t.co/N6mz654JEQ
#VLX #VLXModel #VLXSeries #StreamingMultimodal #OnDeviceAI #PhysicalAI #EmbodiedAI #EdgeAI #VisionLanguageModel #AI
VLX Model Series is coming.
Built for intelligent agents operating in the physical world, the **VLX On-Device Streaming Multimodal Model Series** delivers continuous perception, precise localization, and real-time action decision-making.
From robots to smart wearbales, VLX is designed to power the next generation of AI devices.
Coming Soon.
#VLX #VLXModel #VLXSeries #StreamingMultimodal #OnDeviceAI #PhysicalAI #EmbodiedAI #EdgeAI #VisionLanguageModel #AI
(1/4) Excited to share our latest work from Om AI Research and ZJU! As we push toward Vision-First architectures for physical AI, a critical question remains:
Which pre-training method provides the best foundation model for Spatial Intelligence? VLM or VGM? 🧵👇
Latest blog on teaching VLMs to understand fine-grained objects.
VLM-FO-1 equips a novel object-enhanced vision tower, achieving remarkable object understanding performance with only 3B parameters. Larger models and RL-enhanced coming soon.
https://t.co/2rQJbzw2Pe
🚀 VLM-R1 Full Technical Report Released!
We dissect how GRPO incentivizes visual reasoning in VLMs. Include lots of lessons on reward engineering, data sampling, and generalization. Check it out!
#AI#ReinforcementLearning#ComputerVision#VLMs
https://t.co/OYL4szlMAJ
1/3: 🚀 Thrilled to share VLM-R1’s latest results! After hitting SoTA in REC & Math, we’ve supercharged RL for open vocab detection (OVD).
TL;DR: With the right rewards, RL-powered VLM nails SoTA on OVD + sparks cool "aha" moments.
Dive in: https://t.co/ipBRtRadSi
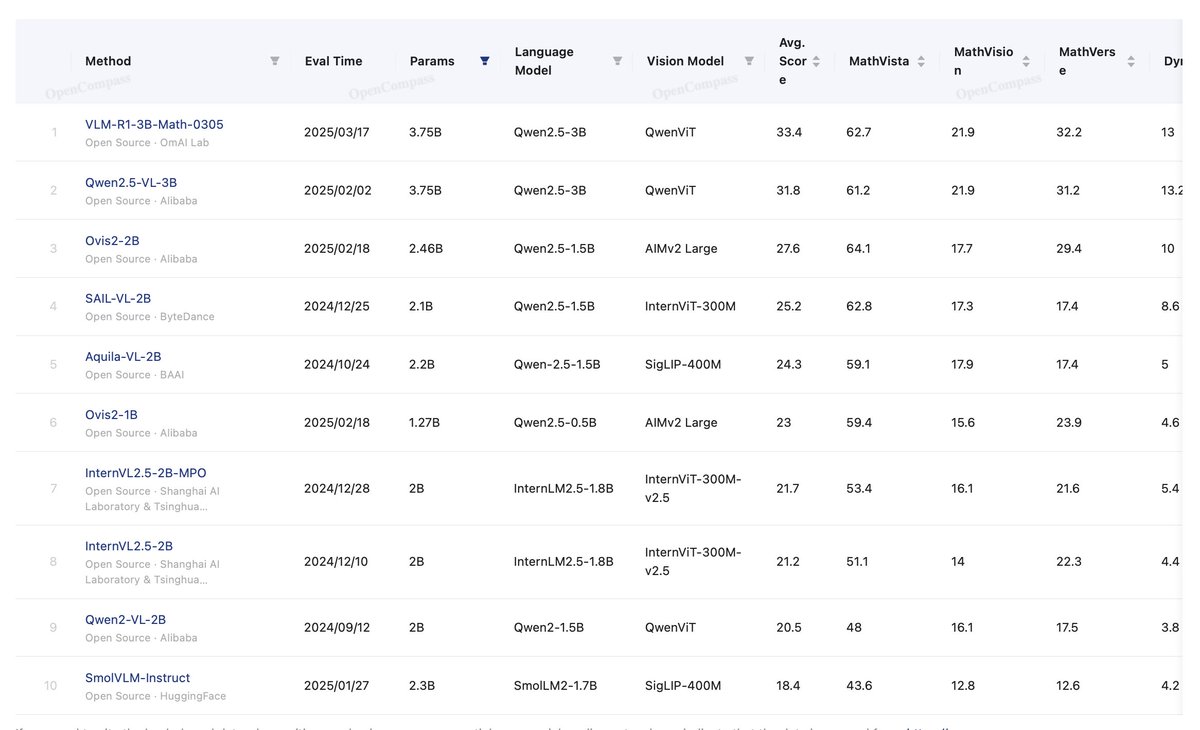
🚀 We just dropped a new RL fine-tuned VLM ranking #1 on Open Compass Multimodal Math Benchmark (<4B params)! 🏆
✨ New features:
• Multi-image input 🖼️🖼️
• Customizable base models ⚙️
🔥 Check it out:
https://t.co/XZd9o647f5
#AI#MachineLearning#OpenSource
🌟 VLM-R1 just got SUPERCHARGED!🚀
🔥 Multi-Node Training for GRPO: Scale training across clusters! Tackle massive vision-language tasks 2x faster with our new multinode_training_demo.sh script.
🎛️ Fine-Grained Parameter Control: Tweak num_iterations for high-precision tasks🎯! Balance exploration vs. exploitation with epsilon—stabilize training & boost generalization!
Level up your VLMs NOW😍 #VisionLanguage #DeepSeek #GRPO
https://t.co/ylW2ceikPz
🚀 OmAgent v0.2.4 is here with exciting new features!
🔹 OmAgent Lite mode: No more dependency on Conductor or other middleware! It’s fully Python-based and supports local execution. Just set OMAGENT_MODE=lite to get started.
🔹 All examples now default to Lite mode – no need for Docker or middleware setup!
🔹 New Agent Operators:
RAP [https://t.co/TWiuh3043Z]
General GOT [https://t.co/keXUV5QKHp]
TOT [https://t.co/3djxgCpp9O]
🔹 Various bug fixes for smoother development!
Get started with the latest version and speed up your development process! ⚡ https://t.co/kod8UlXjyI
#AI #OpenSource #OmAgent
We add a HF demo space to show case the reasoning path. Although not perfect yet, some reasonable rational does emerge from the R1 learning.
https://t.co/r3javu2vts
Introducing VLM-R1!
GRPO has helped DeepSeek R1 to learn reasoning. Can it also help VLMs perform stronger for general computer vision tasks?
Our preliminary answer is YES and it generalizes better than SFT.
https://t.co/iffweRXcpO
OPENAI ROADMAP UPDATE FOR GPT-4.5 and GPT-5:
We want to do a better job of sharing our intended roadmap, and a much better job simplifying our product offerings.
We want AI to “just work” for you; we realize how complicated our model and product offerings have gotten.
We hate the model picker as much as you do and want to return to magic unified intelligence.
We will next ship GPT-4.5, the model we called Orion internally, as our last non-chain-of-thought model.
After that, a top goal for us is to unify o-series models and GPT-series models by creating systems that can use all our tools, know when to think for a long time or not, and generally be useful for a very wide range of tasks.
In both ChatGPT and our API, we will release GPT-5 as a system that integrates a lot of our technology, including o3. We will no longer ship o3 as a standalone model.
The free tier of ChatGPT will get unlimited chat access to GPT-5 at the standard intelligence setting (!!), subject to abuse thresholds.
Plus subscribers will be able to run GPT-5 at a higher level of intelligence, and Pro subscribers will be able to run GPT-5 at an even higher level of intelligence. These models will incorporate voice, canvas, search, deep research, and more.
In EMNLP, I attended a great agent tutorial hosted by @ysu_nlp@Diyi_Yang@ShunyuYao12 , learned a lot about language agents and the progress in agentic ops, e.g. ReAct, CoT etc. How do these methods perform given the same model? I did a study to find out! https://t.co/Rb3ONO69mG
![OmAI_lab's tweet photo. Day 2 of VLX, VLX-Seek: improving VLM fine-grained perception via region reference instead of coordinate generation!
VLMs are good at understanding what is in an image, but still struggle to pinpoint where it is.
Coordinate generation is fragile: long numeric outputs, formatting errors, missed objects, and hallucinated boxes.
VLX-Seek takes a different path: region reference instead of coordinate generation.
It retrieves candidate regions, turns them into language-addressable region tokens, and lets the model select <region_i> instead of generating [x1, y1, x2, y2].
From detection and referring expressions to counting, OCR, and embodied interaction, VLX-Seek pushes VLMs from “seeing the image” toward “grounding objects in space.”
Github:https://t.co/JUl9jPttwg
huggingface:https://t.co/rrig30Dn8e
#VLX #VLXModel #VLXSeries #StreamingMultimodal #OnDeviceAI #PhysicalAI #EmbodiedAI #EdgeAI #VisionLanguageModel #AI](https://pbs.twimg.com/media/HL3ZaGCbgAEtu-5.jpg)












![OmAI_lab's tweet photo. 🚀 OmAgent v0.2.4 is here with exciting new features!
🔹 OmAgent Lite mode: No more dependency on Conductor or other middleware! It’s fully Python-based and supports local execution. Just set OMAGENT_MODE=lite to get started.
🔹 All examples now default to Lite mode – no need for Docker or middleware setup!
🔹 New Agent Operators:
RAP [https://t.co/TWiuh3043Z]
General GOT [https://t.co/keXUV5QKHp]
TOT [https://t.co/3djxgCpp9O]
🔹 Various bug fixes for smoother development!
Get started with the latest version and speed up your development process! ⚡ https://t.co/kod8UlXjyI
#AI #OpenSource #OmAgent](https://pbs.twimg.com/media/GkrvSl1WgAAySvu.jpg)





























