What would truly open-source AI look like? Not just open weights, open code/data, but *open development*, where the entire research and development process is public *and* anyone can contribute. We built Marin, an open lab, to fulfill this vision:
There are two types of advances: (i) a singular change that provides 3x and (ii) a series of micro changes that each provide 20%. It is easy to celebrate (i), but (ii) is just as important, and the hard part is making sure the improvements stack. We care about both in Marin.
Building momentum at Marin! Upgrading from Dense -> 129B parameter MoEs -> architecture improvements -> optimizer improvements gives our pretraining recipe an estimated 6x cumulative learning speedup, accounting for MFU. Includes community contributions. https://t.co/5dPB9uBiSp
Quoting @dlwh : we are at risk of losing the reputation of spiky loss runs!
This run incorporates some stability techniques from my past projects: Hyperball, Gated Norm, and Gated Attention. Excited to see the next run from Marin!
MiniMax-M3 combines 1M context, native multimodality, and MiniMax Sparse Attention.
The next layer is serving it efficiently: KV-block-major sparse attention, paged MSA decode, optimized index scoring, and multimodal preprocessing before the GPU worker.
Together’s Inference and Kernel teams improved throughput by 81–125% across common agentic-shape traffic.
We go deeper in this deep dive from @ywangfirstlean, @zhyncs42, @realDanFu and the team.
Here's a simple idea that works surprisingly well: model generates a response, it "self-verifies" its own response, and trains on those that pass. No ground truth answers or external verifiers. The key is the UQ verifier which we developed in previous work to check rigorously.
Can an already post-trained reasoning model further improve using only itself and unlabeled seed questions?
@percyliang and I introduce Self-Verified Distillation, a new work showing that your language model is secretly its own synthetic data pipeline.
🧵
AI is changing how employers hire workers.
Today we are publishing our research over the past four years into this high-stakes application of AI.
We independently studied the impacts of deployed AI hiring tools based on the real outcomes for 3.3 million people.
While this run was going, we were busy curating more high quality data and making some architectural improvements, all of which will go into the next run. If you want to follow along in real time, come hang out with us in the Marin discord:
https://t.co/Lw7rHUmlVE
Not only do we want to train a good model, we want to know it'll be good before we even start training.
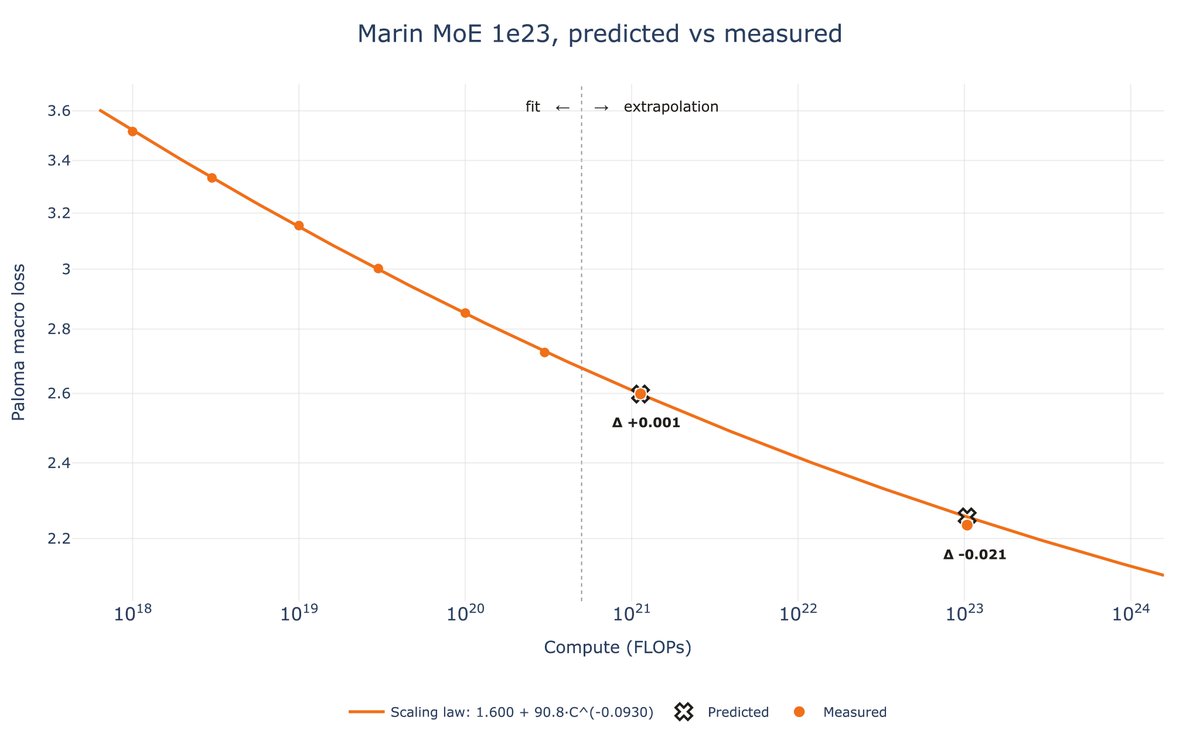
About a month ago, the Marin team launched a 129B (16B active) 1e23 FLOPs MoE run and preregistered a loss of 2.252. The run finished this past week and landed at 2.234.
https://t.co/OptaVa7jIO
Some new results I found surprising that I’m tweeting for Chris (who isnt on here). With enough compute, the best data filter for LMs (on DCLM) might be no filter. Why? Large models can tolerate a surprising amount of nominally 'low quality' data, and can sometimes even benefit.
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
https://t.co/MSPMwnbhVt
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵
🌟Introducing🎻Violin — an Open-source Video Translation Skill.
📹Video is the dominant medium on the internet, yet most high-quality content (lecture, talk, podcast) is locked behind a single language, leaving global audiences behind.
So we built Violin: a video skill that combines speech recognition, LLM translation, and speech synthesis into one seamless pipeline.
🌐 Demo: https://t.co/QFLuz4ANoE
📝 Blog: https://t.co/7FLQYQnCkn
🔗 GitHub: https://t.co/Allp6RZV4V
✨Key Features:
🎙️High-quality multilingual ASR & Translation & TTS.
🗣️Personalize translation & voice (turn an academic talk into something children can follow).
💬Chat with the video — ask any questions grounded in the video.
🧩Support Web app, CLI, and Agent skill
🍃Fully open-source under MIT.
❤️Built with the wonderful @ShangZhu18 and advised by @james_y_zou !
All features powered by @togethercompute .
Try it and let us know what you think! 🎻
Most model trainings have failed outside of frontier labs.
Even inside frontier labs, knowing how to train for very different capabilities is often a matter of taste.
Today, we introduce AutoScientist by @adaption_ai which sets out to change that.
Introducing SWE-ZERO-12M-trajectories: the largest agentic trace dataset in the open, 5.7x larger than the previous largest.
112B tokens · 12M trajectories · 122K PRs · 3K repos · 16 languages
https://t.co/aVqCc4J5tr
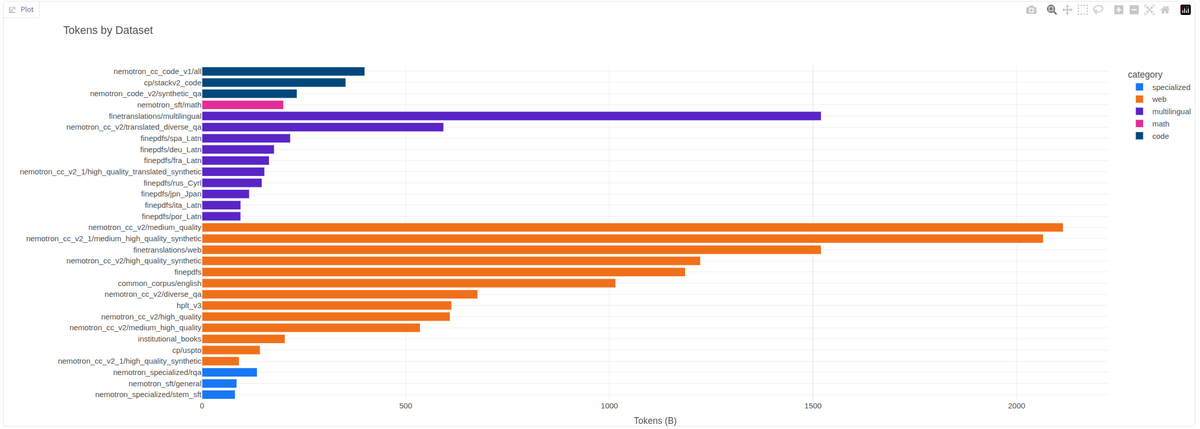
You can see the latest data mix using this token viewer that @WilliamBarrHeld built:
https://t.co/DaSgZa3Q2y
Thanks to @nvidia@huggingface@allen_ai@togethercompute BigCode, CommonPile, and many others who have been releasing high quality data, which helps the entire community!
For the next Marin model, we are putting together a new data mix. Currently we have 18T tokens, but could use more. So if you are sitting on some secret stash of high quality tokens, please let us know! Pre-training, mid-training, SFT data all welcome.
AI Agent literature/web review can get much better. It was peculiar to see how under-the-radar the NanoGPT Speedrun was for agents during Parameter Golf. Many objective improvements, like faster RopE, were not copied. SmearGate was copied incorrectly, and only fixed after a month. Several others were copied in the last couple days, often by the original speedrun author. Even the attributions were not aware of the NanoGPT origins.
To train better open models, we need predictable scaling.
Delphi is Marin’s first step: we pretrained many small models with one recipe, then extrapolated 300× to predict a 25B-param / 600B-token run with just 0.2% error.
Getting there took some work 🧵
AI agents are already going wild, but today’s red-teaming tools for them are still like toys 😢
🔥👽 After spending 20 months and $120K API credits, we are excited to finally open-source DecodingTrust-Agent Platform (DTap): the first controllable, realistic simulation platform for advanced AI agent red-teaming !!
🌍 DTap simulates 50+ real-world environments across 14 high-stakes domains, with realistic agent interfaces replicated from their official MCPs and GUIs. The environments are full-stack, interactive, fully parallelizable, and can be easily configured to reproduce arbitrary real-world attack scenarios, making agent red-teaming scalable and highly transferable to deployment settings.
🔥We also release DTap-Bench, a large-scale benchmark with ~7K agent red-teaming tasks and ~4K policy-grounded malicious goals.
Each red-teaming task includes a sophisticated attack sequence across environment-, tool-, skill-, prompt-level injections, as well as their compositions, plus a handcrafted verifiable judge that checks the actual consequences in the environment.
Using DTap-Bench, we evaluate popular agent frameworks and backbone models across diverse policies, risks, threat models, and attack strategies, revealing systematic vulnerabilities and zero-days in today’s agents!
Paper link: https://t.co/PjnGC5wKk9
Platform + benchmark + code: https://t.co/aicipKMnig
Join our Discord: https://t.co/8UyRjH6RqX
Read more below 👇
Had a great time discussing AI user privacy on @augmind_fm 😃
One discussion I’d like to highlight from the chat is that what constitutes the "Privacy Problem" has been shifting as AI progresses.
It used to be that we care a lot about *training-time* user privacy: what gets trained into the model, and what the model would spit out. Say you take an LLM and a book (or any piece of sensitive text). We cared about whether the book would be regurgitated ("memorization"); whether you can remove such a book from the model ("unlearning"); and whether you can detect the book being trained ("membership inference"). And as part of mitigating these problems, we work on training-time techniques like differential privacy, careful data cleaning, and model alignment/guardrails (in ~increasing order of adoption). Guardrails seem to work well enough that people don’t really talk about sensitive model outputs anymore.
What’s more pressing today, I argue, is *inference-time* user privacy: the fact that intelligent models are served at scale on private user data, which are then centrally managed at model providers. Intelligent models mean that user profiling is now cheap and automatic; your activities can be continuously analyzed to reveal new sensitive insights. Whether your data is trained on or not became less relevant. Having a "digital clone" of you by building on your memory/personalization is now way more profitable. The threat vector changed from the model misbehaving to the provider misbehaving.
Because of this, the techniques to improve user privacy would look different than before. They’ll look less like fancy learning algorithms (e.g. RL to steer model to output paraphrase of a book than the original book), and more like *peripheral systems* sitting around closed models that we do not control but still want to access. The OA project (https://t.co/rOAoavIavT) is an example: you could build a zero-knowledge proxy to mediate AI inference and combat surveillance, and leverage smaller models to help users build personal memory on-device. This is not to say that there’s no room for training; you just train for different things, and on auxiliary models than the closed models.
thank you so much to @EchoShao8899@michaelryan207@shannonzshen for hosting me!
I find myself repeatedly explaining the difference between open-weight (DeepSeek), open-source (Olmo), open-development (Marin). Let's see if this restaurant analogy helps:
- Open-weight: food is made behind closed doors, server brings you the dish
- Open-source: food is made behind closed doors, server brings you the dish and the recipe
- Open-development: you see the chef make the dish in the kitchen (and can shout suggestions while its cooking)!