Read this to get started learning ML infra.
This is an excellent high-level overview of important considerations in ML training from CMU. It touches on:
- hardware
- memory
- the ML experimentation process
https://t.co/RTWm0Ecni1
6 guides to understand how LLMs actually work
- What is a Token?
- How token taxonomy affects your bill
- Embeddings (including RoPE)
- Agentic Vector Databases
- Attention: Mechanism, QKV, and KV Cache
- From tokens to answers: What actually happens during LLM inference
Links ↓
MIT's ABSOLUTELY FREE Books on AI & ML:
1. Foundations of Machine Learning
https://t.co/78p57EBbL8
2. Understanding Deep Learning
https://t.co/D2oyRrXqcE
3. Introduction to Machine Learning Systems
❯ Vol 1: https://t.co/IezLFJdhDV
❯ Vol 2: https://t.co/NYP3xAPZ6u
4. Algorithms for ML
https://t.co/lntuD4Q19H
5. Deep Learning
https://t.co/vCHVIZQYTI
6. Reinforcement Learning
https://t.co/JNWhFCuCkH
7. Distributional Reinforcement Learning
https://t.co/GXpkV4BDZi
8. Multi Agent Reinforcement Learning
https://t.co/T8zVmQVutO
9. Agents in the Long Game of AI
https://t.co/HeD3Nsm5zz
10. Fairness and Machine Learning
https://t.co/csAjhdf7Lb
11. Probabilistic Machine Learning
❯ Part 1 : https://t.co/5Leef9ypGj
❯ Part 2 : https://t.co/vRbF0rEIuh
We just launched a new project that teaches you how to build Flash Attention with CUDA, step by step.
By the end, you’ll have a working Flash Attention kernel built from the ground up.
The project covers:
-CUDA primitives warm-up
-Matrix operations
-Naive attention baseline
-Online softmax math
-Tiled attention building blocks
-Fused Flash Attention kernel
-Causal Flash Attention
It will be open to everyone for the first 2 weeks, then it will become part of our premium projects.
'Agent Harness Engineering: A Survey' just cited my Agent Skills for Context Engineering project in its Context & Memory Management section.
It’s a new paper on OpenReview (authors from CMU, Yale, Johns Hopkins, Amazon + others). They reviewed 170+ open-source projects and pulled real production lessons from OpenAI, Anthropic, and LangChain.
Agent performance in the real world = Model capability + Harness quality
For long-horizon, multi-step, production tasks, the harness has become the main bottleneck. Simple harness tweaks (better tool formats, sandbox changes, automated verification loops) deliver significant gains on benchmarks.
This is the second time my open-source work has been cited in academic research (first was Peking University’s State Key Lab paper on meta context engineering).
I’m genuinely proud of that, but more than anything it reminds me why I love open source. I’m not from academia. I learned this field by building, shipping, writing...
Open source lets your experiments enter the research papers. That is still one of the best parts of this field.
The paper is worth reading. We're moving from “build one agent” to “operate a fleet of long-running agents” and the paper repeatedly shows that the biggest improvements come from turning production traces into regression tests and automated harness fixes.
Paper & Repo: https://t.co/PAjqvOXedL
Distribution-Guided Policy Optimization (DGPO) – a new PO method that shifts focus to rewarding useful exploration
DGPO improves famous GRPO. It identifies which reasoning steps really mattered:
1. Like GRPO, DGPO samples several Chain-of-Thought reasoning paths for comparison.
2. A verifier/reward model scores the final answers, and DGPO computes a sequence-level advantage.
It selectively redistributes rewards instead of giving every token the same one.
3. DGPO replaces unstable KL divergence with bounded Hellinger distance that measures how much the model’s token predictions deviate from the reference model.
It compares the square roots of the probabilities that two models assign to the same tokens.
Deviation from the reference model becomes a signal of potential reasoning innovation.
4. Entropy gating filters hallucinations. High entropy → genuine exploration, low entropy → confident hallucination.
5. Tokens responsible for successful reasoning receive larger updates.
▪️ Why DGPO is a good new option:
• Exploration is rewarded and no critic model is needed
• Better token-level reasoning supervision
• More stable than KL-based RL
• Strong improvements on long reasoning tasks like math benchmarks: AIME 2025: 46.0%, AIME 2024 60.0%. It's better than methods like DAPO
Day 124/365 of GPU Programming
Since I've been studying state space models and hybrid attention architectures recently, I'm spending today using some of these models and seeing what kind of inference optimizations I can play around with.
Mainly trying out Qwen 3.5 and looking at Qwen 3.5 with its gated attention layers. Also first time working with Hugging Face, which has been fun. Really nice how easy they make comparing models and downloading weights.
Will probably spend the next few days looking into different ways to minimize inference latency, reading through existing solutions and trying out different things on my local machine with whatever models I can fit.
Day 83/365 of GPU Programming
Looking at DeepSeek's Multi-Head Latent Attention today. The last part of the AMD challenge series is to optimize an MLA decode kernel for MI355X where the absorbed Q and compressed KV cache are given and your task is to do the attention computation.
A resource that really helped internalize what MLA does was @rasbt's incredible visual guide to attention variants in LLMs (luckily he posted that last week!), which covers everything from MHA to GQA to MLA to SWA, et cetera. If there's one place to get a visual intuition for recent attention mechanisms, it's this blog post.
@jbhuang0604's video on MQA, GQA,MLA and DSA was the best conceptual intro I found on the topic and progressively builds up the ideas from first principles.
The Welch Labs analysis of MLA is a great watch as well. Beautiful visualization of the changes DeepSeek made for MLA.
Tried out a few kernels once I had a basic understanding of MLA and I think I'm slowly getting more comfortable with at least analyzing kernels.
Recursive Language Models (RLMs) have been floating around for a couple of months, but in the last two weeks the discussion has picked up fast, especially alongside ideas like GEPA.
The issue they’re trying to address isn’t new. When you build agents, the context window becomes a bottleneck pretty quickly.
Packing more into the prompt leads to context rot and we know it well.
RLMs take a different angle. Instead of treating the input as a fixed blob of text, the model treats it more like an environment it can explore.
You give the root model something like a REPL, and now it doesn’t have to read everything upfront.
It can decide what’s worth inspecting and make recursive sub-calls when needed.
So instead of one big forward pass, you get structured computation.
The paper shows RLMs handling up to two orders of magnitude beyond context window
But on simple retrieval i.e "needle in a haystack", there’s basically no difference compared to standard models.
Difference appears once context gets large (around 16K tokens and beyond), which is expected.
Things change with tasks like OOLONG, where the model has to aggregate information across many entries (linear complexity). Vanilla models degrade steadily as the input grows, while RLMs hold up much better.
On OOLONG at 132K tokens, base GPT-5 scores 44% while the RLM scores 56.5% . A ~28% improvement.
Another breakpoint shows up with OOLONG-Pairs, which requires pairwise comparisons (quadratic complexity). Standard models are essentially at zero. RLMs get to ~58% F1.
This isn't surprising as these task can't be done with single forward pass as attention isn’t designed for that.
On deeper research-style tasks (like browsing large document sets), RLMs also show strong gains, both in accuracy and token efficiency.
One of the more interesting side effects is what people are calling “small model inversion.” With the right recursive setup, smaller models can outperform larger ones on long-context reasoning.
There are cases where a GPT-5-mini-based RLM beats GPT-5 on harder splits, and where smaller fine-tuned models outperform much larger ones on million-token tasks. That suggests the bottleneck isn’t just model size.
The main thing to keep in mind is that RLMs aren’t universally better. On short, simple tasks, they don’t really add value.
But as context length and reasoning complexity increase, the advantage becomes hard to ignore.
The OOLONG-Pairs result ~58% vs <0.1% is probably the clearest signal.
Once a task requires structured computation rather than just pattern matching, giving the model the ability to act over the context changes what it can do.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Sebastian Raschka is one of the most respected researchers in ML/AI education. Period.
And now he's done something quietly brilliant.
He built an LLM Architecture Gallery - a single, browsable reference that maps out the internal architecture of every major open-weight model released in the last few years.
This is a serious research artifact, made free for everyone.
Here's what's inside:
🔹 GPT-2 XL (1.5B)
🔹 Llama 3 (8B)
🔹 OLMo 2 (7B)
🔹 Llama 3.2 (1B)
🔹 Qwen3 (4B, 8B, 32B)
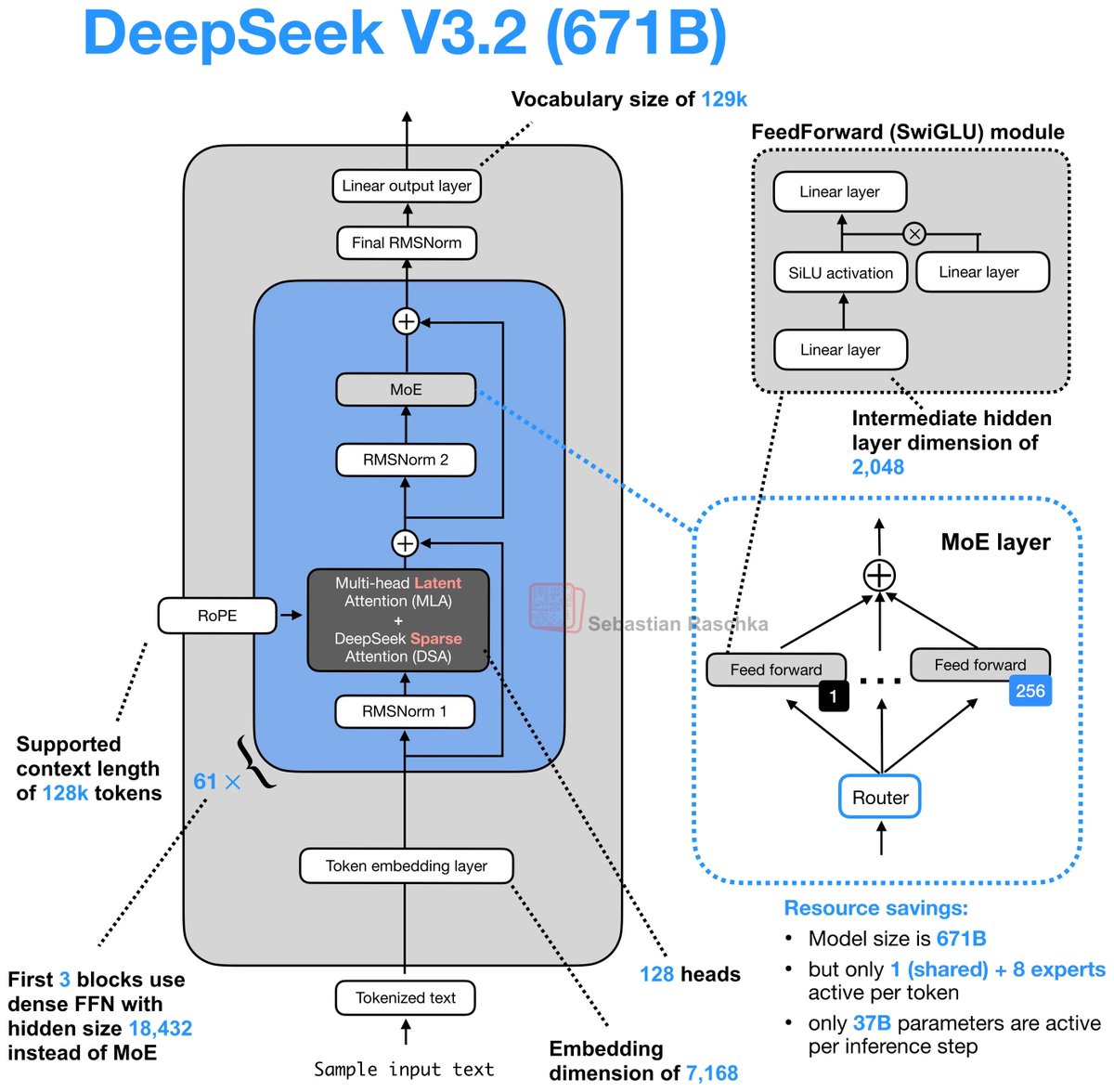
🔹 DeepSeek V3/R1 (671B)
🔹 Kimi K2 (1 Trillion)
🔹 Gemma 3 (4B, 27B, 270M)
🔹 Mistral 3.1 Small (24B) & Mistral Large (673B)
🔹 Llama 4 Maverick (400B)
🔹 Qwen3 235B-A22B & Qwen3 Coder Flash
🔹 SmolLM (1B)
🔹 GPT-OSS (20B, 120B)
🔹 Grok 2.5 (270B)
🔹 GLM-4.5 (355B), GLM-5 (744B), GLM-4.7 (355B)
🔹 MiniMax-M2 (230B) & MiniMax-M2.5
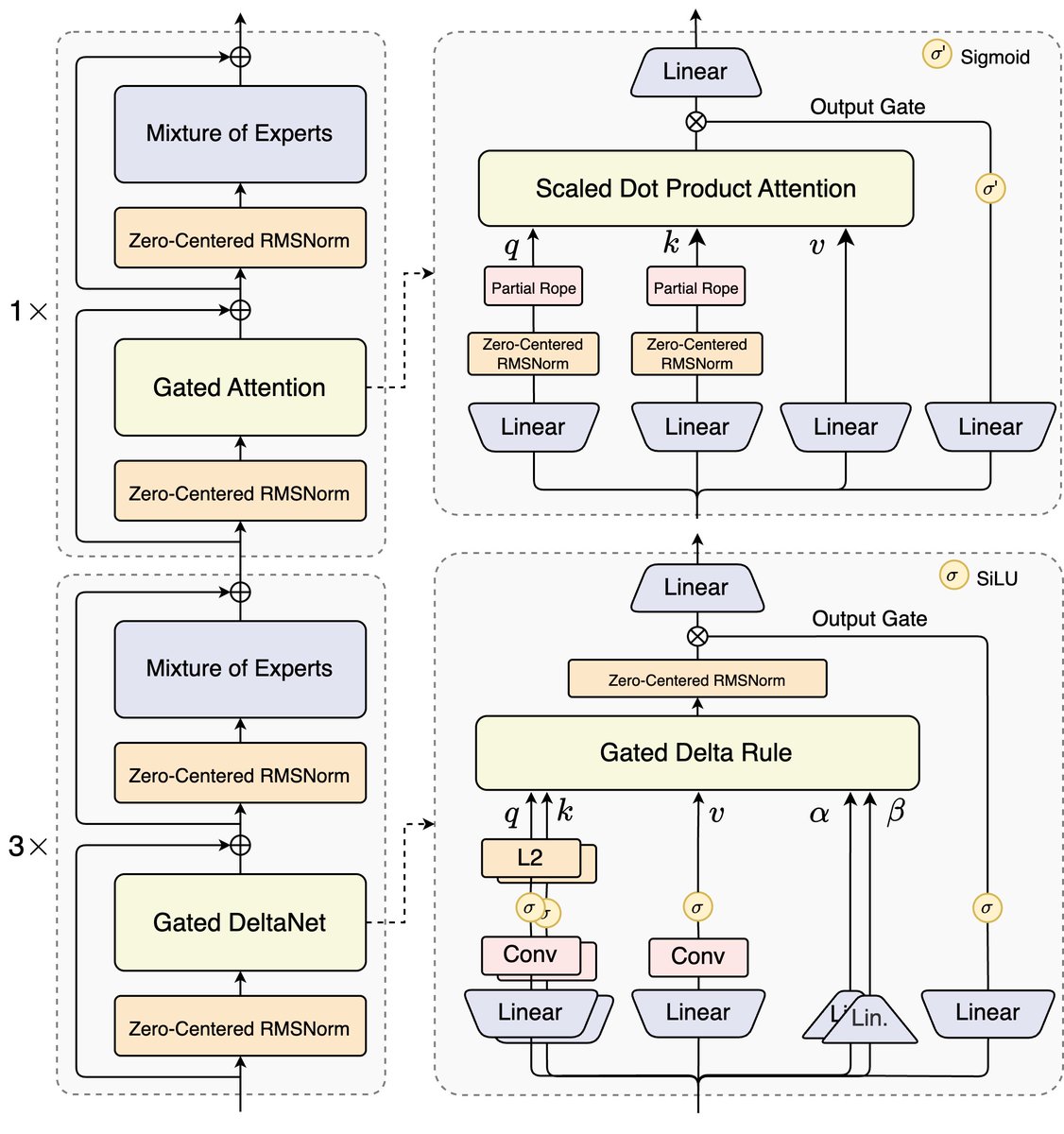
🔹 Kimi Linear (48B-A3B)
🔹 OlMo 3 (7B) & OlMo 3 (32B)
🔹 Nemotron 3 Nano (20B-A3B) & Nemotron 3 Super
🔹 Xiaomi MiMo-V2-Flash (309B)
🔹 Arcee AI Trinity Large (400B)
🔹 Tiny Aya (3.35B)
🔹 Step 3.5 Flash (196B)
🔹 Nanbeige (4.1, 3B)
🔹 Qwen3.5 (997B)
🔹 Ling 2.5 (1T)
🔹 Sarvam (30B, 105B)
And for each model, he links:
→ The original tech report
→ The config[.]json (so you can verify every number yourself)
→ From-scratch implementations where available
But here's what makes it truly special.
He also added short concept explainers, so you're not just staring at boxes and arrows:
→ GQA (Grouped Query Attention)
→ MLA (Multi-head Latent Attention)
→ SWA (Sliding Window Attention)
→ QK-Norm
→ NoPE (No Positional Encoding)
→ Gated DeltaNet
This is the kind of resource that used to require buying 3 textbooks, reading 40 papers, and spending a weekend.
Now it's one link.
If you're studying LLMs, building on top of them, or just trying to understand how the field has evolved, this is a must-bookmark.
New art project.
Train and inference GPT in 243 lines of pure, dependency-free Python. This is the *full* algorithmic content of what is needed. Everything else is just for efficiency. I cannot simplify this any further.
https://t.co/HmiRrQugnP
Tips for coding agents to be more RLM-like:
1) Don't read context into prompts. Read context into variables!
2) Don't call sub-agents as direct tools that pollute your context window with I/O. Write code that invokes sub-agents as functions that return values to variables.
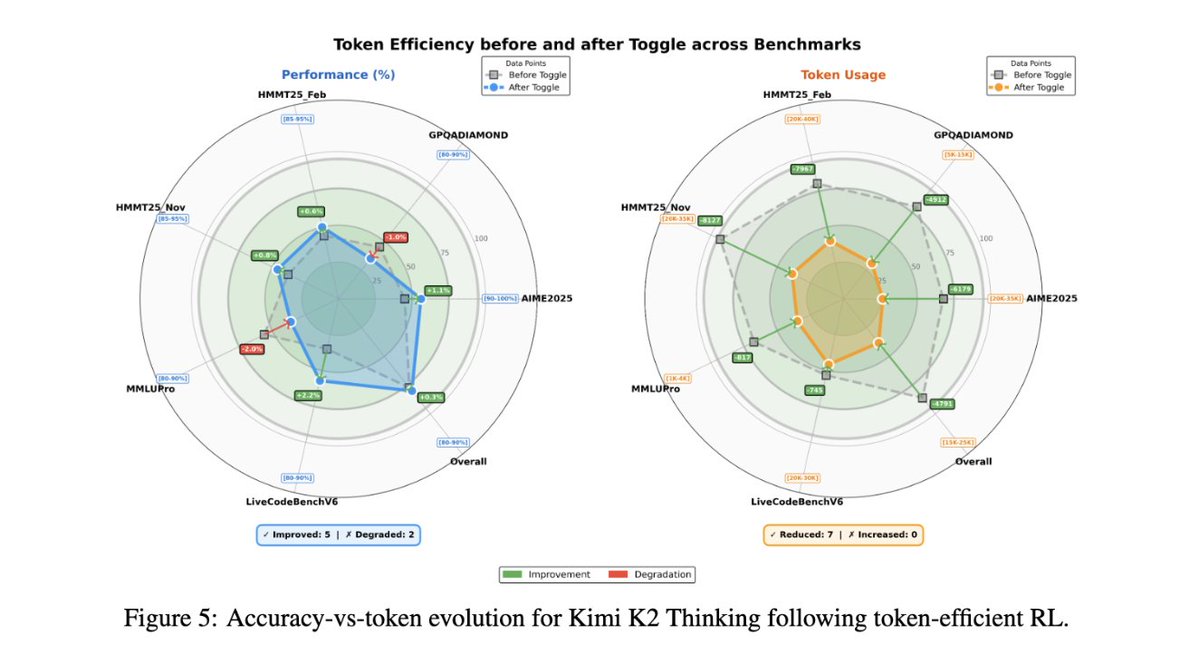
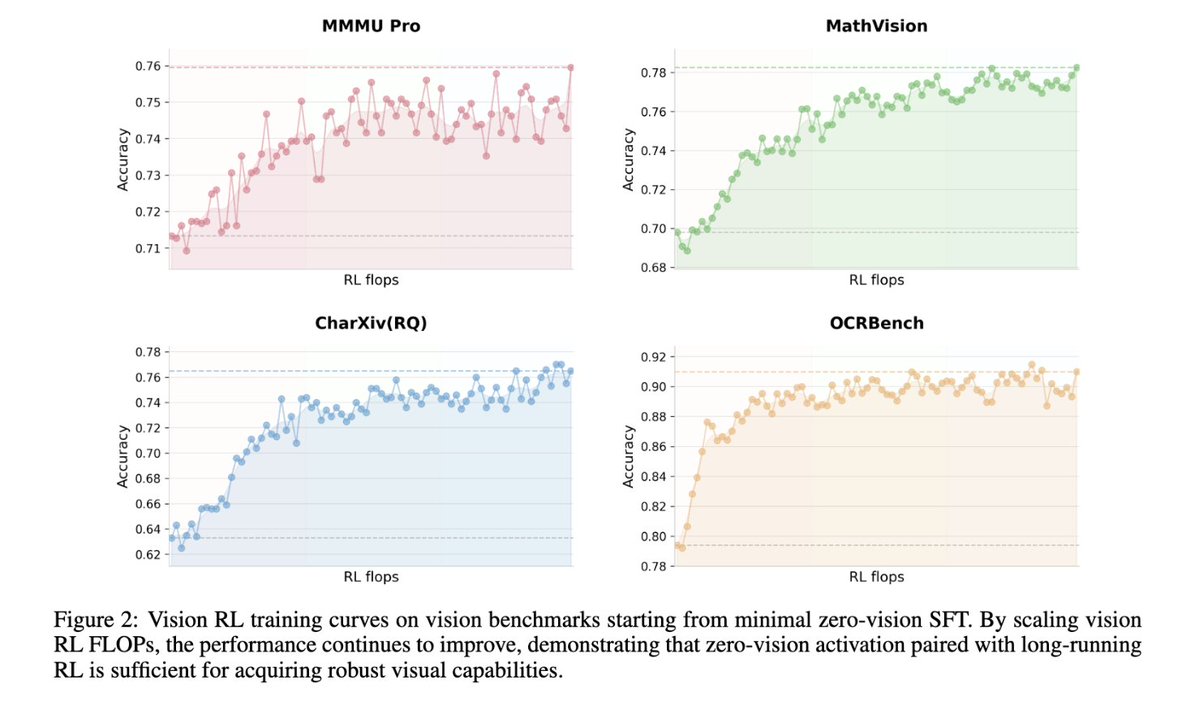
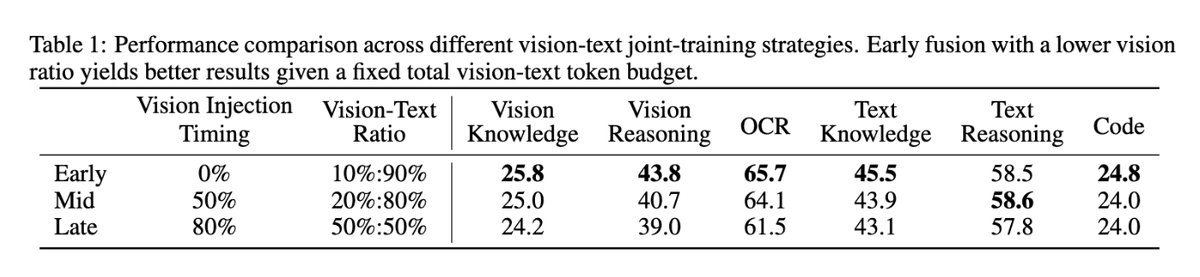
Kimi K2.5 tech report just dropped!
Quick hits:
- Joint text–vision training: pretrained with 15T vision-text tokens, zero-vision SFT (text-only) to activate visual reasoning
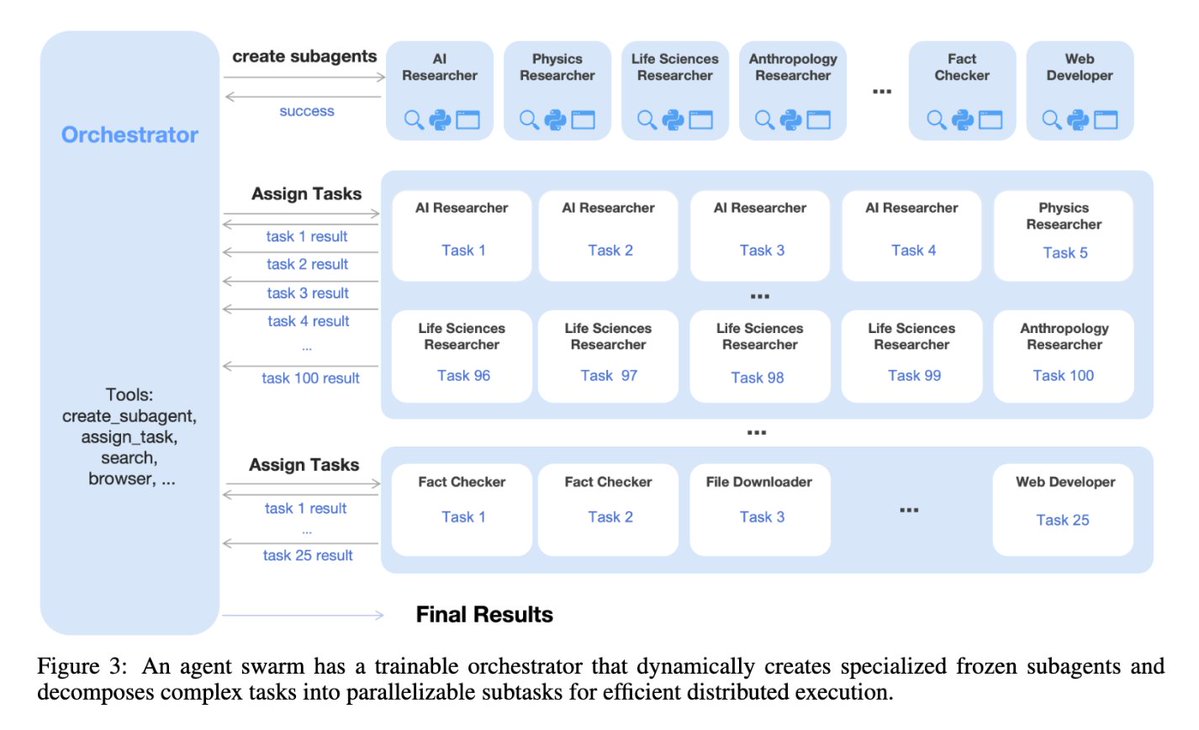
- Agent Swarm + PARL: dynamically orchestrated parallel sub-agents, up to 4.5× lower latency, 78.4% on BrowseComp
- MoonViT-3D: a unified image–video encoder with 4× temporal compression, enabling 4× longer videos in the same context
- Toggle: token-efficient RL, 25–30% fewer tokens with no accuracy drop
Here's our work toward scalable, real-world agentic intelligence. More details in the report 👉https://t.co/N5pwm0M4jm
A conventional narrative you might come across is that AI is too far along for a new, research-focused startup to outcompete and outexecute the incumbents of AI. This is exactly the sentiment I listened to often when OpenAI started ("how could the few of you possibly compete with Google?") and 1) it was very wrong, and then 2) it was very wrong again with a whole another round of startups who are now challenging OpenAI in turn, and imo it still continues to be wrong today. Scaling and locally improving what works will continue to create incredible advances, but with so much progress unlocked so quickly, with so much dust thrown up in the air in the process, and with still a large gap between frontier LLMs and the example proof of the magic of a mind running on 20 watts, the probability of research breakthroughs that yield closer to 10X improvements (instead of 10%) imo still feels very high - plenty high to continue to bet on and look for.
The tricky part ofc is creating the conditions where such breakthroughs may be discovered. I think such an environment comes together rarely, but @bfspector & @amspector100 are brilliant, with (rare) full-stack understanding of LLMs top (math/algorithms) to bottom (megakernels/related), they have a great eye for talent and I think will be able to build something very special. Congrats on the launch and I look forward to what you come up with!































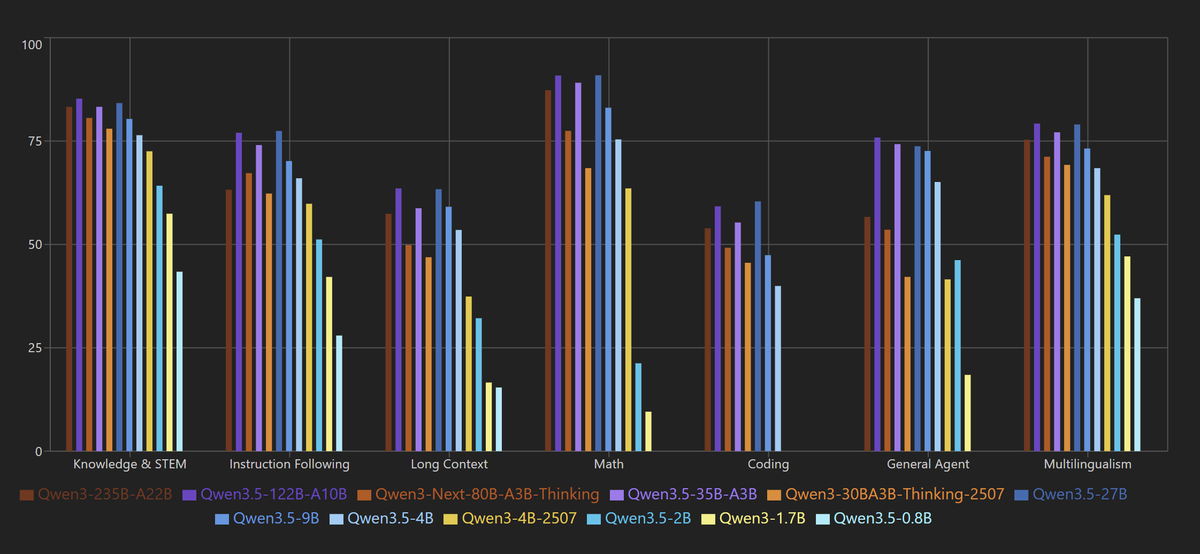


![techNmak's tweet photo. Sebastian Raschka is one of the most respected researchers in ML/AI education. Period.
And now he's done something quietly brilliant.
He built an LLM Architecture Gallery - a single, browsable reference that maps out the internal architecture of every major open-weight model released in the last few years.
This is a serious research artifact, made free for everyone.
Here's what's inside:
🔹 GPT-2 XL (1.5B)
🔹 Llama 3 (8B)
🔹 OLMo 2 (7B)
🔹 Llama 3.2 (1B)
🔹 Qwen3 (4B, 8B, 32B)
🔹 DeepSeek V3/R1 (671B)
🔹 Kimi K2 (1 Trillion)
🔹 Gemma 3 (4B, 27B, 270M)
🔹 Mistral 3.1 Small (24B) & Mistral Large (673B)
🔹 Llama 4 Maverick (400B)
🔹 Qwen3 235B-A22B & Qwen3 Coder Flash
🔹 SmolLM (1B)
🔹 GPT-OSS (20B, 120B)
🔹 Grok 2.5 (270B)
🔹 GLM-4.5 (355B), GLM-5 (744B), GLM-4.7 (355B)
🔹 MiniMax-M2 (230B) & MiniMax-M2.5
🔹 Kimi Linear (48B-A3B)
🔹 OlMo 3 (7B) & OlMo 3 (32B)
🔹 Nemotron 3 Nano (20B-A3B) & Nemotron 3 Super
🔹 Xiaomi MiMo-V2-Flash (309B)
🔹 Arcee AI Trinity Large (400B)
🔹 Tiny Aya (3.35B)
🔹 Step 3.5 Flash (196B)
🔹 Nanbeige (4.1, 3B)
🔹 Qwen3.5 (997B)
🔹 Ling 2.5 (1T)
🔹 Sarvam (30B, 105B)
And for each model, he links:
→ The original tech report
→ The config[.]json (so you can verify every number yourself)
→ From-scratch implementations where available
But here's what makes it truly special.
He also added short concept explainers, so you're not just staring at boxes and arrows:
→ GQA (Grouped Query Attention)
→ MLA (Multi-head Latent Attention)
→ SWA (Sliding Window Attention)
→ QK-Norm
→ NoPE (No Positional Encoding)
→ Gated DeltaNet
This is the kind of resource that used to require buying 3 textbooks, reading 40 papers, and spending a weekend.
Now it's one link.
If you're studying LLMs, building on top of them, or just trying to understand how the field has evolved, this is a must-bookmark.](https://pbs.twimg.com/media/HEf5pCwasAEePjj.jpg)