Senior research scientist at @LosAlamosNatLab. Former prof at @ucl
and @UTAustin. CogSci, AI, Comp Neuro, AI for scientific discovery
Also @profdata on Bluesky
"Large language models surpass human experts in predicting neuroscience results" w @ken_lxl and https://t.co/YOhCmQlJsu. LLMs integrate a noisy yet interrelated scientific literature to forecast outcomes. https://t.co/49WYirBdBv 1/8
@samzliu@GaryMarcus I attribute consciousness to other humans not through the third-person perspective of science, but by the imperfect process of analogy to myself. No denial of the hard problem; it's just not addressable by scientific means.
Last month Dawkins declared Claude conscious and was mocked. @GaryMarcus cleverly called it The Claude Delusion. My (and Nagel's?) take: Both are wrong for the same reason. Here's an essay on why machine consciousness will never be settled scientifically. https://t.co/o3KYXAZEgC
@YeshuaGod22@GaryMarcus As someone who usually looks for answers in science, I too struggle where we go from here. In day-to-day life, it seems we attribute consciousness to others and animals by analogy to ourselves, but that seems egotistical and flawed.
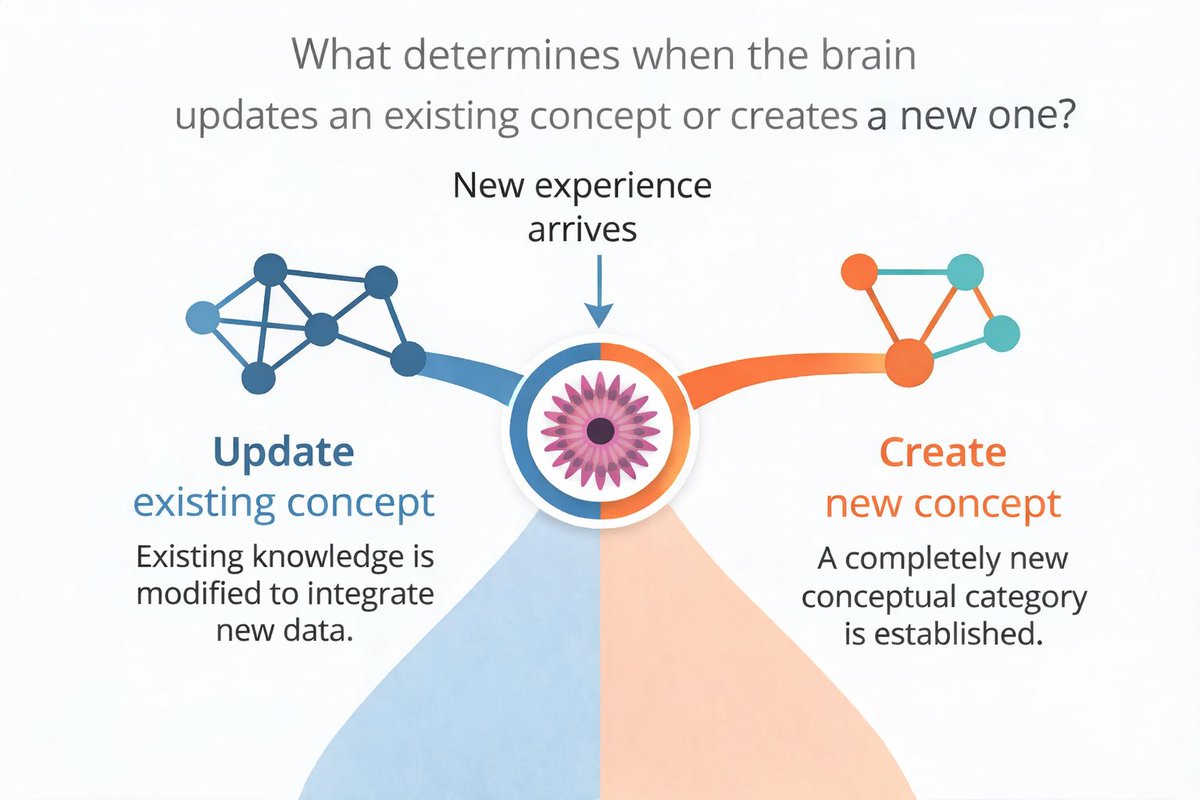
Every time you experience something new, your brain faces a decision: Should it update an existing memory or create a new one?
In our new paper in @JNeurosci, we isolate that exact decision, moment-by-moment during learning. 🧵
Personally, I will be looking to mentor projects with Mahindra Rautela on (1) Search and Evaluation for test-time AI Reasoning, and (2) model distillation to compress large physics foundation models.
Please feel free to get in touch with questions or to express interest. 2/2
Are you a graduate student interested in working at Los Alamos National Laboratory (LANL) this summer? LANL has student internships, apply here: https://t.co/j427EZJP1V 1/2
Intuitive cell types don't necessarily play the ascribed functional role in the overall computation. This is not a message the field wants to hear as it suggests better baselines, controls, and some reflection. https://t.co/l0aedcRrnM... w @ken_lxl , @robmok.bsky.social @ 2/2
"The inevitability and superfluousness of cell types in spatial cognition". Intuitive cell types are found in random artificial networks using the same selection criteria neuroscientists use with actual data. https://t.co/l0aedcRrnM... 1/2
Working with monkey data, we found neural representations stretched across brain regions to emphasize task relevant features on a trial-by-trial basis. Spike timing mattered over spike rate. Deep nets did the same. https://t.co/P3v6oB1LtA 2/2
Exciting "new" work illustrating our broken publishing system. @seb_bobadilla presented this work online at neuromatch 2.0 at the height of the pandemic. Then, @xinyazhang_ worked years on addressing reviewer comments, which added some rigor but didn't change the message. 1/2
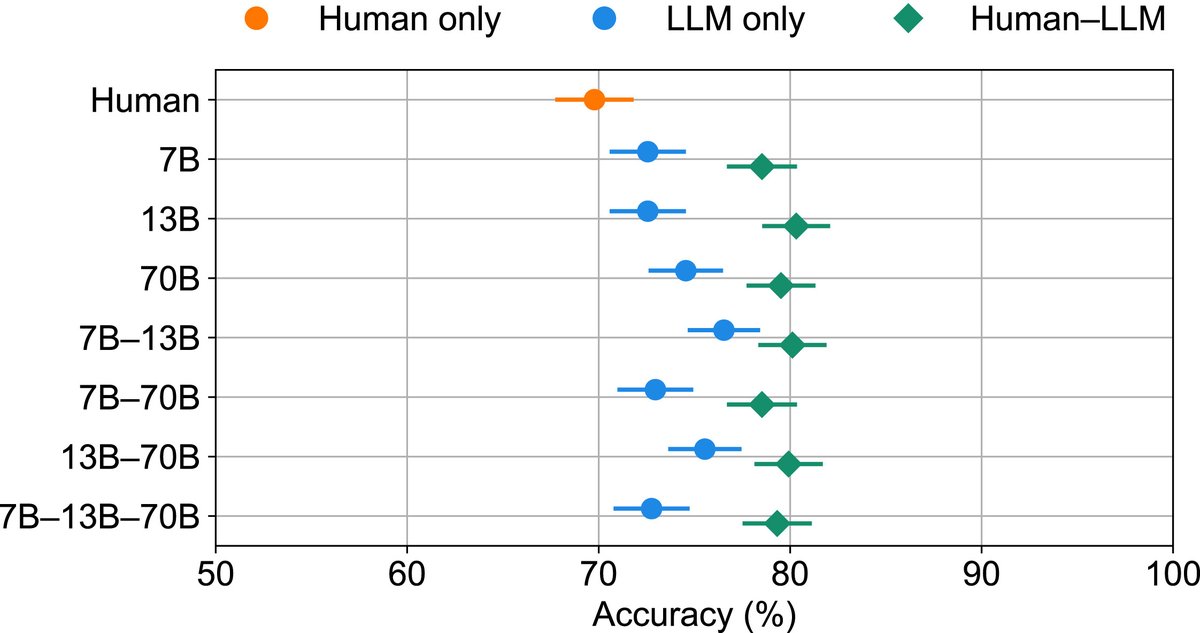
We developed a straightforward method of combining confidence-weighted judgments for any number of humans and AIs. w @yanezlang, Omar Minero, @ken_lxl 2/2
When AI surpasses human performance, what's left for humans? We find that human judgment boosts performance of human-AI teams because humans and machines make different errors. https://t.co/6yHm4dCBwq 1/2
Researchers are using LLMs to analyze the literature, brainstorm hypotheses, build models and interact with complex datasets. Hear from Martin Schrimpf @martin_schrimpf, Kim Stachenfeld @neuro_kim, Jeremy Magland, Bradley Love and others.
https://t.co/HHAOg4BUOD
🧵🎉 Our mega-paper is finally published in TMLR! We're "Getting Aligned on Representational Alignment" - the degree to which internal representations of different (biological & artificial) information processing systems agree. 🧠🤖🔬🔍 #CognitiveScience#Neuroscience#AI
New blog w @ken_lxl, “Giving LLMs too much RoPE: A limit on Sutton’s Bitter Lesson”. The field has shifted from flexible data-driven position representations to fixed approaches following human intuitions. Here’s why and what it means for model performance https://t.co/f1GSA1ZWgt
New blog, "Backwards Compatible: The Strange Math Behind Word Order in AI" w @ken_lxl. It turns out the language learning problem is the same for any word order, but is that true in practice for large language models? paper: https://t.co/SSU3WwfC94 BLOG: https://t.co/PQBEVnPIeu
Bonus: I found it counterintuitive that (in theory) the learning problem is the same for any word ordering. Aligning proof and simulation was key. Now, new avenues open to address positional biases, better training and knowing when to trust LLMs
w @ken_lxl, @ramscar1, @XinyiXu6
"Probability Consistency in Large Language Models: Theoretical Foundations Meet Empirical Discrepancies"
Oddly, we prove LLMs should be equivalent for any word ordering: forward, backward, scrambled. In practice, LLMs diverge from one another. Why? 1/2 https://t.co/SSU3Wwf4jw
When LLMs diverge from one another because of word order (data factorization), it indicates their probability distributions are inconsistent, which is a red flag (not trustworthy). We trace deviations to self-attention positional and locality biases. 2/2 https://t.co/SSU3Wwf4jw