“AI agents will outperform humans at almost all jobs by 2026–2027.” - The forecast is everywhere.
So we built the exam to test that claim, on real labor-market aligned work. On the hardest tier, top agents pass 2.6%.
Meet Agents' Last Exam (ALE), a rolling benchmark measuring whether agents can actually do real jobs. 🧵👇
Introducing ✨RigidFormer: Learning Rigid Dynamics with Transformers - our attempt to scale learning-based physical dynamics with Transformers.
RigidFormer learns rigid dynamics with Transformers. It is a mesh-free, object-centric Transformer for multi-object rigid-body contact dynamics from point clouds.
Learning physics with purely neural simulators, without relying on traditional physics engines, is an important and widely studied problem. Prior SOTA methods often use graph neural networks for accuracy and generalization, but still struggle with efficient, high-fidelity simulation at scale.
RigidFormer uses only point inputs, matches or outperforms mesh-based baselines on standard benchmarks, runs much faster, generalizes across point resolutions and datasets, and scales to 200+ objects. We also show a preliminary extension to command-conditioned articulated bodies by treating body parts as interacting object-level components.
RigidFormer is mesh-free: it does not require mesh connectivity, SDFs, or vertex-level message passing, making it well-suited for point-cloud observations and scalable simulation.
This architecture can also be adapted to learn soft-body dynamics by replacing the rigid-body module (differentiable Kabsch alignment).
🎬See our video for more details.
Many thanks to my amazing collaborators: Minghao Guo @GuoMh14, Haixu Wu @Haixu_Wu_1998, Doug Roble, Tuur Stuyck @TuurStuyck, and Wojciech Matusik @wojmatusik.
Project page: https://t.co/6TBaRPVEYo
Paper: https://t.co/3OQUSJSND3
Excited to share that our work NeuralActuator: Neural Actuation Modeling for Robot Dynamics and External Force Perception has been accepted to #RSS2026!
Your robot — even a low-cost one — can feel external forces without torque or tactile sensors.
TL;DR: NeuralActuator is a neural actuator model that jointly predicts 1️⃣torque to capture the nonlinear and time-varying current–to–torque relationship of low-cost servos, 2️⃣external contact forces (and force detection gates) for sensorless force perception, 3️⃣and motor conditions that indicate each motor’s operating regime.
Here is a fast-forward video clip ⬇️ We are also covering more robots like LeRobot-S101 and Franka Panda.
More details coming soon.
SAD: Soft Anisotropic Diagrams for Differentiable Image Representation has been accepted by #SIGGRAPH2026
Check it out, and huge congrats to Lucky! @Luckyballa#SAD represents an image as a soft, anisotropic, differentiable diagram over learnable sites. Each pixel is modeled as a softmax blend over its top-K nearby sites under a site-dependent distance, yielding a differentiable partition of unity with explicit ownership and content-aligned boundaries. A GPU-friendly top-K propagation scheme keeps the cost constant per pixel, enabling fast fitting at matched or better quality.
Classical geometric structures can still inspire fresh perspectives in modern visual computing.
Voronoi and Power diagrams have long been elegant tools for 3D shape analysis, reconstruction, and geometric reasoning; here, related diagram ideas, with connections to Apollonius-style diagrams, are explored for image representations.
Homepage: https://t.co/9woOAGRBPp
arXiv: https://t.co/yAIiplhDN5
#SIGGRAPH2026 #SIGGRAPH #CV #Vision #Graphics #CG
We have seen many works unlock the power of pretrained models for images and videos🏞️. But what about human motion🕺💃?
Can we leverage a pretrained motion prior for a wide range of downstream tasks?
Yes!! UMO is a simple yet effective framework that, for the first time, unlocks the priors of a motion foundation model (i.e., HY-Motion) for 10+ tasks, including editing, reaction generation, stylization, trajectory control, obstacle avoidance, keyframe infilling, and more. Amazing work! @xiaoyan_cong and @kunkun0w0.
🏠Webpage: https://t.co/AhRCOzPxhG
📄 Paper: https://t.co/x2Zt8faTum
With the growing number of tools for transferring SMPL motion to humanoids, we hope it could also become a source of skills for humanoid robot learning.
#Graphics #Motion #Animation #AIGC #GenerativeAI #Vision #3DV #Robotics #Robot #Humanoid #Learning #GenAI #Animation
Learned from in-the-wild images, GAIA generates 3D Gaussian animatable avatars with identity & expression control and real-time animation
📅 Talk: Aug 14, 9 AM PDT – West Bldg, Rm 211–214
🎮 Live demo @ poster session & E-Tech
🔗https://t.co/sBRFCe3Yd6
#SIGGRAPH2025@NVIDIAAI
Hello 🇸🇬 Singapore!
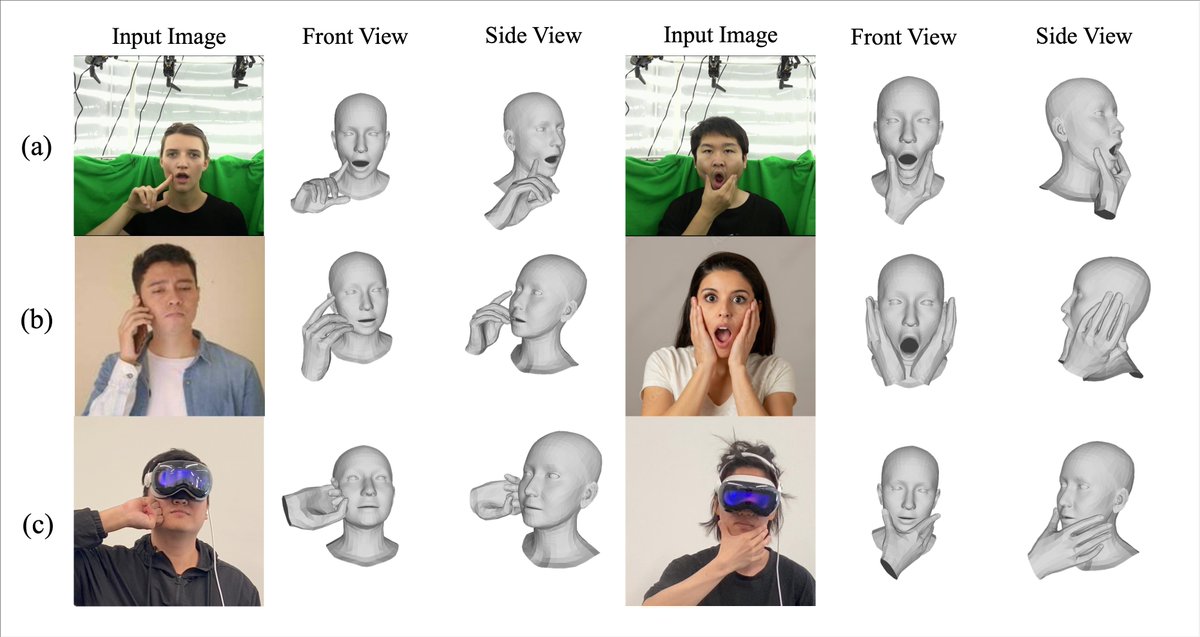
At #ICLR2025, I’ll be presenting our work 🎲DICE from @LingjieLiu1's lab!
With DICE, one can explore hand-face interactions 📷 — this feedforward method simultaneously estimates hand and face poses, contact points, and deformations from a single image using a Transformer-based architecture. Come join us!
📍 Hall 3 + Hall 2B #130 Poster Session 6
🕒 Sat 26 Apr, 3–5:30 p.m.
🎥 Check out the video for more details!
Huge thanks to all our amazing collaborators who made this possible: @qingxuan_wu@xu_sirui , Soshi Shimada, @chenwangcw , @Proof_Yu , @YuanLiu41955461 , @_cheng_lin , Zeyu Cao, Taku Komura, @VGolyanik , Christian Theobalt, Wenping Wang, and @LingjieLiu1.
#ICLR25 #ICLR2025 #AI #Animation #CV #CG #Interaction
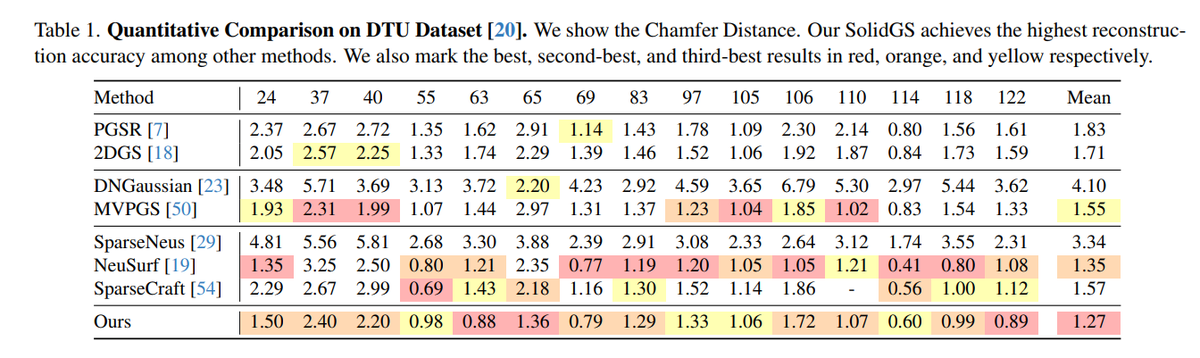
3R-GS: Best Practice in Optimizing Camera Poses Along with 3DGS
Contributions:
1. We propose 3R-GS, a robust method for reconstructing high-quality 3D Gaussians and poses from the MASt3R's imperfect output cameras.
2. Identifying two main challenges in bundle-adjusting 3DGS, we propose an effective solution that combines 3DGS-MCMC, an MLP-based pose refiner, and an epipolar distance loss to address these issues.
3. Our experiments demonstrate the superior performance of 3R-GS in both novel view synthesis and camera pose estimation.
DICE 🎲was accepted by #ICLR2025.
With DICE, one can learn more about hand face interactions 👤🤏. This end-to-end method also enables better scalability to learn and model hand-face interaction. Congrats to @qingxuan_wu !
Check the video for more details :)
#ICLR#ICLR2025
#SIGGRAPHASIA#SIGGRAPHASIA2024#ACMTOG
🐟 We introduce Collective Behavior Imitation Learning (CBIL), a scalable, self-supervised framework for learning fish schooling behaviors from videos, to be presented at SIGGRAPH ASIA 2024 Tokyo (journal track)🗼!
🦈Reproducing realistic collective behaviors presents a captivating challenge, as traditional rule-based methods fall short in realism, while data-driven approaches rely on hard-to-acquire motion trajectories.
🐠CBIL first leverages a Masked Video AutoEncoder (MVAE) to map 2D observations to expressive latent states. Then an adversarial imitation learning framework with bio-inspired rewards is developed for stable and realistic motion generation. We demonstrate CBIL's effectiveness across various fish body shapes and its capability to detect abnormal behaviors from in-the-wild videos (real2sim4real).
I like this attempt to “inject data priors” for Visual Imitation Learning, especially given the challenges of obtaining ground truth 3D motion for imitation.
A heartfelt thanks to our amazing intern, Yifan Wu @Littlecobbler! Always remember the excitement we felt during those sleepless nights! And special gratitude to our incredible collaborators: Yuko Ishiwaka, Shun Ogawa, Yuke Lou, Wenping Wang, @LingjieLiu1, and Taku Komura.
🏠Project Page: https://t.co/7MdAIAmjAX
📑Paper: ACM Transactions on Graphics https://t.co/wFFkC8JRJN
#AI #ImitationLearning #Animation #Animation #AI #CrowdAnimation #BehaviorAnalysis #CrowdMotion
#Graphics #CG #Motion #AIGC #MotionSynthesis
We showcase real-world videos and synthesized results, aligned for clearer visualization (rather than as reconstructions).
Surf-D will be posted today. Please check out with our handsome boy @frankzydou if you're at ECCV 2024 @eccvconf!!
👗 Surf-D: Generating High-Quality Surfaces of Arbitrary Topologies Using Diffusion Models
📅 Wed, Oct 2 | 16:30 - 18:30 | Poster Session 4 | Poster 285
Our Surf-D is accepted at ECCV 2024 @eccvconf. Codes are released. Surf-D can generate arbitrary typology shapes in high resolution using UDF representation.
Project page: https://t.co/QC3c4CyKzf
Arxiv: https://t.co/6x5mJXkFrr
Codes: https://t.co/JszrxK22hZ
#eccv#SurfD
🔍 Check out our latest research on 3D hand-face interactions!
🔥 Introducing 🎲 DICE, the first end-to-end method that captures hand-face interactions and deformations from a single image. (1/n)
Our Surf-D is accepted at ECCV 2024 @eccvconf. Codes are released. Surf-D can generate arbitrary typology shapes in high resolution using UDF representation.
Project page: https://t.co/QC3c4CyKzf
Arxiv: https://t.co/6x5mJXkFrr
Codes: https://t.co/JszrxK22hZ
#eccv#SurfD
Got five papers accepted by #ECCV2024@eccvconf ! Huge thanks to all my collaborators! 😃 See you in Milan 🇮🇹
Summary of Selected Works
(I made a fast-forward for them 😄)
- [Shape Generation] Surf-D: Generating High-Quality Surfaces of Arbitrary Topologies Using Diffusion Models, ECCV 2024.
- [Efficient Motion Generation] EMDM: Efficient Motion Diffusion Model for Fast, High-Quality Human Motion Generation, ECCV 2024.
- [Controllable Motion Generation] TLControl: Trajectory and Language Control for Human Motion Synthesis, ECCV 2024.
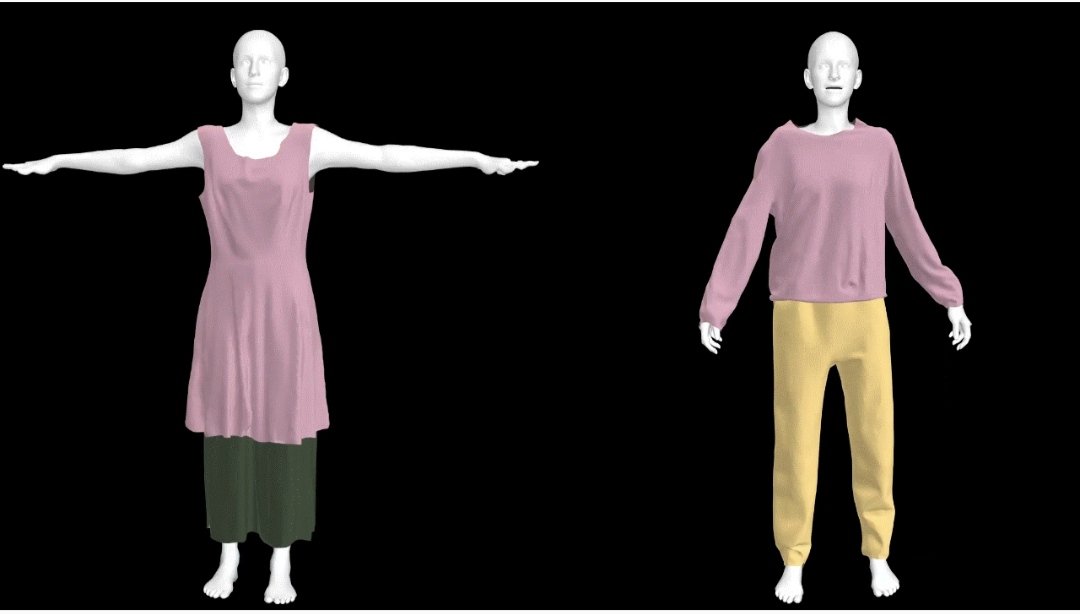
- [Avatar Generation] Disentangled Clothed Avatar Generation from Text Descriptions, ECCV 2024.
Project Page:
Surf-D: https://t.co/CuQUfkglZL
EMDM: https://t.co/pGTAduj1D9
TLControl: https://t.co/rKfIW4q3Ie
SOSMPL: https://t.co/8Vazyl38wL