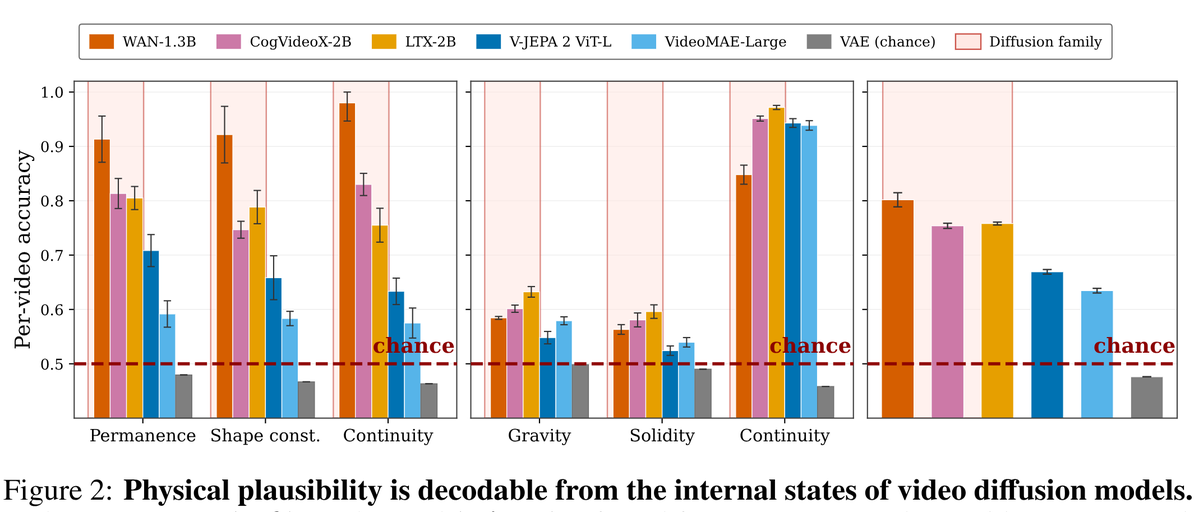
You may have recently heard claims that video generation models are "dumb" about physics, and only "world models" (V-JEPA, specifically) have a valid internal model of physics.
This turns out to be false. In a recent paper, researchers show that a LINEAR probe of diffusion videogen models predict various "physics" very well, significantly better than V-JEPA or VideoMAE (and plain VAE just sucks).
This is noteworthy, because a *linear* probe being this accurate shows that the model has a pretty explicit internal representation of the physics!
I was stunned when Jingdong showed me the results for shadow removal. We tested a lot of our travel shots with complex effects UniSER works well on all of them. Please come to the poster to talk insights with Jingdong!
🎉 Excited to present UniSER at #CVPR2026!
📅 Sat, Jun 6 | 11:45 AM – 1:45 PM MDT
📍 ExHall F 173
We propose a unified foundation model for soft effects removal (flare, haze, shadows, reflections). Stop by if you're into Generative Editing! 👇
🏠 Proj: https://t.co/93vQrfjf0j
World models are moving beyond offline generation towards interactive, real-time experiences.
Introducing ⚡FlashDreams⚡: an open-source high-performance inference and serving library built for autoregressive world models:
🔥 Up to 3.10× faster LingBot-World inference
🔥 Up to 2.12× faster Self-Forcing inference
🔥 Up to 1.40× faster Wan2.1 inference
🔥 8 integrated models
🔥 Multi-GPU, streaming, low-latency serving
🔥 Agentic skills that teach you how to use it
FlashDreams is designed for a new generation of AI systems that continuously evolve over time while responding to user interactions. It powers applications across robotics, autonomous vehicle simulation, gaming, and virtual worlds.
Github: https://t.co/xM8LuPaRTS
Docs: https://t.co/IInORNIzy3
Research page: https://t.co/mZ6TLQSpIO
Join the #flashdreams Discord channel at https://t.co/GGOQ0k7liY
FlashDreams is also the runtime backbone behind NVIDIA OmniDreams (https://t.co/PLUt55gxxh)
1/n
#AI #WorldModels #FastInference #PhysicalAI #OpenSource #NVIDIA
Introducing ✨RigidFormer: Learning Rigid Dynamics with Transformers - our attempt to scale learning-based physical dynamics with Transformers.
RigidFormer learns rigid dynamics with Transformers. It is a mesh-free, object-centric Transformer for multi-object rigid-body contact dynamics from point clouds.
Learning physics with purely neural simulators, without relying on traditional physics engines, is an important and widely studied problem. Prior SOTA methods often use graph neural networks for accuracy and generalization, but still struggle with efficient, high-fidelity simulation at scale.
RigidFormer uses only point inputs, matches or outperforms mesh-based baselines on standard benchmarks, runs much faster, generalizes across point resolutions and datasets, and scales to 200+ objects. We also show a preliminary extension to command-conditioned articulated bodies by treating body parts as interacting object-level components.
RigidFormer is mesh-free: it does not require mesh connectivity, SDFs, or vertex-level message passing, making it well-suited for point-cloud observations and scalable simulation.
This architecture can also be adapted to learn soft-body dynamics by replacing the rigid-body module (differentiable Kabsch alignment).
🎬See our video for more details.
Many thanks to my amazing collaborators: Minghao Guo @GuoMh14, Haixu Wu @Haixu_Wu_1998, Doug Roble, Tuur Stuyck @TuurStuyck, and Wojciech Matusik @wojmatusik.
Project page: https://t.co/6TBaRPVEYo
Paper: https://t.co/3OQUSJSND3
We are back. After one year of quiet building.
Introducing GENE-26.5, our first robotic brain that takes a major step toward human-level capability.
For years, robotics has struggled to learn from the world’s largest and valuable data source: Humans.
Solving it means rethinking the whole stack from the ground up:
- A robotics-native foundation model.
- A 1:1 human-like robotic hand.
- A noninvasive data collection glove for motion, force, and touch.
- A simulator that turns weeks of experiments into minutes.
GENE-26.5 is trained across language, vision, proprioception, tactile, and action. We designed a set of tasks to test how far we can go with this new paradigm.
Fully autonomous, 1x speed, one model, same weights. (Enjoy with sound on)
We are approaching the endgame for robotics.
And this is just a beginning.
Two months ago, I vaguely posted a number: 0.9 FID, one-step, pixel space.
Now it is 0.75, and can be even lower.
Many wonder how.
I thought it might end as a small FID prank: simple and deliberate.
It started with one question: can FID be optimized directly, and what does it reveal?
Introducing FD-loss.
Excited to share that our work NeuralActuator: Neural Actuation Modeling for Robot Dynamics and External Force Perception has been accepted to #RSS2026!
Your robot — even a low-cost one — can feel external forces without torque or tactile sensors.
TL;DR: NeuralActuator is a neural actuator model that jointly predicts 1️⃣torque to capture the nonlinear and time-varying current–to–torque relationship of low-cost servos, 2️⃣external contact forces (and force detection gates) for sensorless force perception, 3️⃣and motor conditions that indicate each motor’s operating regime.
Here is a fast-forward video clip ⬇️ We are also covering more robots like LeRobot-S101 and Franka Panda.
More details coming soon.
SAD: Soft Anisotropic Diagrams for Differentiable Image Representation has been accepted by #SIGGRAPH2026
Check it out, and huge congrats to Lucky! @Luckyballa#SAD represents an image as a soft, anisotropic, differentiable diagram over learnable sites. Each pixel is modeled as a softmax blend over its top-K nearby sites under a site-dependent distance, yielding a differentiable partition of unity with explicit ownership and content-aligned boundaries. A GPU-friendly top-K propagation scheme keeps the cost constant per pixel, enabling fast fitting at matched or better quality.
Classical geometric structures can still inspire fresh perspectives in modern visual computing.
Voronoi and Power diagrams have long been elegant tools for 3D shape analysis, reconstruction, and geometric reasoning; here, related diagram ideas, with connections to Apollonius-style diagrams, are explored for image representations.
Homepage: https://t.co/9woOAGRBPp
arXiv: https://t.co/yAIiplhDN5
#SIGGRAPH2026 #SIGGRAPH #CV #Vision #Graphics #CG
I am very happy to share the result of my internship at FAIR (Meta): V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning with @ylecun@AdrienBardes
Our approach learns dense, spatially coherent features from video while preserving strong global understanding
We have seen many works unlock the power of pretrained models for images and videos🏞️. But what about human motion🕺💃?
Can we leverage a pretrained motion prior for a wide range of downstream tasks?
Yes!! UMO is a simple yet effective framework that, for the first time, unlocks the priors of a motion foundation model (i.e., HY-Motion) for 10+ tasks, including editing, reaction generation, stylization, trajectory control, obstacle avoidance, keyframe infilling, and more. Amazing work! @xiaoyan_cong and @kunkun0w0.
🏠Webpage: https://t.co/AhRCOzPxhG
📄 Paper: https://t.co/x2Zt8faTum
With the growing number of tools for transferring SMPL motion to humanoids, we hope it could also become a source of skills for humanoid robot learning.
#Graphics #Motion #Animation #AIGC #GenerativeAI #Vision #3DV #Robotics #Robot #Humanoid #Learning #GenAI #Animation
Open-source dexterous hands with fingertip sensors! 🪬
@orcahand just released three dexterous hand models.
Their mission: is to democratize robotic hand dexterity. They're sharing progress on exceptional, low-cost hardware and a software layer from low-level control to robotic hand learning.
This is the open-source approach to dexterous manipulation.
It has 83 taxels per finger with 0.1 N force detection which pretty is impressive for an open-source design. Tactile sensing is critical for dexterous manipulation, knowing contact forces enables gentle grasping, slip detection, and force-controlled assembly.
Also 700g weight for the lite version makes it practical for mounting on robot arms without exceeding payload limits. Lower weight means faster movements and lower torque requirements.
Open hardware accelerates robotics by letting researchers and builders modify designs for their specific needs without starting from scratch!
~~
♻️ Join the weekly robotics newsletter, and never miss any news → https://t.co/GoA3ZuwoPB
AMI Labs just raised $1.03B. World Labs raised $1B a few weeks earlier. Both are betting on world models.
But almost nobody means the same thing by that term.
Here are, in my view, five categories of world models.
---
1. Joint Embedding Predictive Architecture (JEPA)
Representatives: AMI Labs (@ylecun), V-JEPA 2
The central bet here is that pixel reconstruction alone is an inefficient objective for learning the abstractions needed for physical understanding. LeCun has been saying this for years — predicting every pixel of the future is intractable in any stochastic environment. JEPA sidesteps this by predicting in a learned latent space instead.
Concretely, JEPA trains an encoder that maps video patches to representations, then a predictor that forecasts masked regions in that representation space — not in pixel space.
This is a crucial design choice.
A generative model that reconstructs pixels is forced to commit to low-level details (exact texture, lighting, leaf position) that are inherently unpredictable. By operating on abstract embeddings, JEPA can capture "the ball will fall off the table" without having to hallucinate every frame of it falling.
V-JEPA 2 is the clearest large-scale proof point so far. It's a 1.2B-parameter model pre-trained on 1M+ hours of video via self-supervised masked prediction — no labels, no text. The second training stage is where it gets interesting: just 62 hours of robot data from the DROID dataset is enough to produce an action-conditioned world model that supports zero-shot planning. The robot generates candidate action sequences, rolls them forward through the world model, and picks the one whose predicted outcome best matches a goal image. This works on objects and environments never seen during training.
The data efficiency is the real technical headline. 62 hours is almost nothing. It suggests that self-supervised pre-training on diverse video can bootstrap enough physical prior knowledge that very little domain-specific data is needed downstream. That's a strong argument for the JEPA design — if your representations are good enough, you don't need to brute-force every task from scratch.
AMI Labs is LeCun's effort to push this beyond research. They're targeting healthcare and robotics first, which makes sense given JEPA's strength in physical reasoning with limited data. But this is a long-horizon bet — their CEO has openly said commercial products could be years away.
---
2. Spatial Intelligence (3D World Models)
Representative: World Labs (@drfeifei)
Where JEPA asks "what will happen next," Fei-Fei Li's approach asks "what does the world look like in 3D, and how can I build it?"
The thesis is that true understanding requires explicit spatial structure — geometry, depth, persistence, and the ability to re-observe a scene from novel viewpoints — not just temporal prediction.
This is a different bet from JEPA: rather than learning abstract dynamics, you learn a structured 3D representation of the environment that you can manipulate directly.
Their product Marble generates persistent 3D environments from images, text, video, or 3D layouts. "Persistent" is the key word — unlike a video generation model that produces a linear sequence of frames, Marble's outputs are actual 3D scenes with spatial coherence. You can orbit the camera, edit objects, export meshes. This puts it closer to a 3D creation tool than to a predictive model, which is deliberate.
For context, this builds on a lineage of neural 3D representation work (NeRFs, 3D Gaussian Splatting) but pushes toward generation rather than reconstruction. Instead of capturing a real scene from multi-view photos, Marble synthesizes plausible new scenes from sparse inputs. The challenge is maintaining physical plausibility — consistent geometry, reasonable lighting, sensible occlusion — across a generated world that never existed.
---
3. Learned Simulation (Generative Video + Latent-Space RL)
Representatives: Google DeepMind (Genie 3, Dreamer V3/V4), Runway GWM-1
This category groups two lineages that are rapidly converging: generative video models that learn to simulate interactive worlds, and RL agents that learn world models to train policies in imagination.
The video generation lineage. DeepMind's Genie 3 is the purest version — text prompt in, navigable environment out, 24 fps at 720p, with consistency for a few minutes. Rather than relying on an explicit hand-built simulator, it learns interactive dynamics from data. The key architectural property is autoregressive generation conditioned on user actions: each frame is generated based on all previous frames plus the current input (move left, look up, etc.). This means the model must maintain an implicit spatial memory — turn away from a tree and turn back, and it needs to still be there. DeepMind reports consistency up to about a minute, which is impressive but still far from what you'd need for sustained agent training.
Runway's GWM-1 takes a similar foundation — autoregressive frame prediction built on Gen-4.5 — but splits into three products: Worlds, Robotics, and Avatars. The split into Worlds / Avatars / Robotics suggests the practical generality problem is still being decomposed by action space and use case.
The RL lineage. The Dreamer series has the longer intellectual history. The core idea is clean: learn a latent dynamics model from observations, then roll out imagined trajectories in latent space and optimize a policy via backpropagation through the model's predictions. The agent never needs to interact with the real environment during policy learning.
Dreamer V3 was the first AI to get diamonds in Minecraft without human data. Dreamer 4 did the same purely offline — no environment interaction at all. Architecturally, Dreamer 4 moves from Dreamer’s earlier recurrent-style lineage to a more scalable transformer-based world-model recipe, and introduced "shortcut forcing" — a training objective that lets the model jump from noisy to clean predictions in just 4 steps instead of the 64 typical in diffusion models. This is what makes real-time inference on a single H100 possible.
These two sub-lineages used to feel distinct: video generation produces visual environments, while RL world models produce trained policies.
But Dreamer 4 blurred the line — humans can now play inside its world model interactively, and Genie 3 is being used to train DeepMind's SIMA agents.
The convergence point is that both need the same thing: a model that can accurately simulate how actions affect environments over extended horizons.
The open question for this whole category is one LeCun keeps raising: does learning to generate pixels that look physically correct actually mean the model understands physics? Or is it pattern-matching appearance? Dreamer 4's ability to get diamonds in Minecraft from pure imagination is a strong empirical counterpoint, but it's also a game with discrete, learnable mechanics — the real world is messier.
---
4. Physical AI Infrastructure (Simulation Platform)
Representative: NVIDIA Cosmos
NVIDIA's play is don't build the world model, build the platform everyone else uses to build theirs.
Cosmos launched at CES January 2025 and covers the full stack — data curation pipeline (process 20M hours of video in 14 days on Blackwell, vs. 3+ years on CPU), a visual tokenizer with 8x better compression than prior SOTA, model training via NeMo, and deployment through NIM microservices.
The pre-trained world foundation models are trained on 9,000 trillion tokens from 20M hours of real-world video spanning driving, industrial, robotics, and human activity data.
They come in two architecture families: diffusion-based (operating on continuous latent tokens) and autoregressive transformer-based (next-token prediction on discretized tokens). Both can be fine-tuned for specific domains.
Three model families sit on top of this.
Predict generates future video states from text, image, or video inputs — essentially video forecasting that can be post-trained for specific robot or driving scenarios.
Transfer handles sim-to-real domain adaptation, which is one of the persistent headaches in physical AI — your model works great in simulation but breaks in the real world due to visual and dynamics gaps.
Reason (added at GTC 2025) brings chain-of-thought reasoning over physical scenes — spatiotemporal awareness, causal understanding of interactions, video Q&A.
---
5. Active Inference
Representative: VERSES AI (Karl Friston)
This is the outlier on the list — not from the deep learning tradition at all, but from computational neuroscience.
Karl Friston's Free Energy Principle says intelligent systems continuously generate predictions about their environment and act to minimize surprise (technically: variational free energy, an upper bound on surprise).
Where standard RL is usually framed around reward maximization, active inference frames behavior as minimizing variational / expected free energy, which blends goal-directed preferences with epistemic value. This leads to natural exploration behavior: the agent is drawn to situations where it's uncertain, because resolving uncertainty reduces free energy.
VERSES built AXIOM (Active eXpanding Inference with Object-centric Models) on this foundation.
The architecture is fundamentally different from neural network world models. Instead of learning a monolithic function approximator, AXIOM maintains a structured generative model where each entity in the environment is a discrete object with typed attributes and relations.
Inference is Bayesian — beliefs are probability distributions that get updated via message passing, not gradient descent. This makes it interpretable (you can inspect what the agent believes about each object), compositional (add a new object type without retraining), and extremely data-efficient.
In their robotics work, they've shown a hierarchical multi-agent setup where each joint of a robot arm is its own active inference agent. The joint-level agents handle local motor control while higher-level agents handle task planning, all coordinating through shared beliefs in a hierarchy. The whole system adapts in real time to unfamiliar environments without retraining — you move the target object and the agent re-plans immediately, because it's doing online inference, not executing a fixed policy.
They shipped a commercial product (Genius) in April 2025, and the AXIOM benchmarks against RL baselines are competitive on standard control tasks while using orders of magnitude less data.
---
imo, these five categories aren't really competing — they're solving different sub-problems.
JEPA compresses physical understanding.
Spatial intelligence reconstructs 3D structure.
Learned simulation trains agents through generated experience.
NVIDIA provides the picks and shovels.
Active inference offers a fundamentally different computational theory of intelligence.
My guess is the lines between them blur fast.
𝗢𝗻𝗲 𝗺𝗲𝗺𝗼𝗿𝘆 𝗰𝗮𝗻’𝘁 𝗿𝘂𝗹𝗲 𝘁𝗵𝗲𝗺 𝗮𝗹𝗹.
We present 𝗟𝗼𝗚𝗲𝗥, a new 𝗵𝘆𝗯𝗿𝗶𝗱 𝗺𝗲𝗺𝗼𝗿𝘆 architecture for long-context geometric reconstruction.
LoGeR enables stable reconstruction over up to 𝟭𝟬𝗸 𝗳𝗿𝗮𝗺𝗲𝘀 / 𝗸𝗶𝗹𝗼𝗺𝗲𝘁𝗲𝗿 𝘀𝗰𝗮𝗹𝗲, with 𝗹𝗶𝗻𝗲𝗮𝗿-𝘁𝗶𝗺𝗲 𝘀𝗰𝗮𝗹𝗶𝗻𝗴 in sequence length, 𝗳𝘂𝗹𝗹𝘆 𝗳𝗲𝗲𝗱𝗳𝗼𝗿𝘄𝗮𝗿𝗱 inference, and 𝗻𝗼 𝗽𝗼𝘀𝘁-𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗮𝘁𝗶𝗼𝗻.
Yet it matches or surpasses strong optimization-based pipelines. (1/5)
@GoogleDeepMind@Berkeley_AI
Figure has released a new video of its humanoid robot cleaning a living room autonomously:
“In this new demonstration, Helix 02 performs whole body, end-to-end living room cleanup - walking through the room while continuously manipulating objects, tools, and containers.”
@ziyuchen_ Incredible! It's like a world model with more physics grounding by the simulation, and also efficient. Would be super useful for action models.
🤩Video world models are cool, but it is cooler if they can simulate any 3D physical actions in real time! Introducing RealWonder⚡️: Now you can simulate 3D physical action (robot actions, 3D forces, force fields, etc.) consequences from a single image in real time! 🧵1/6