PhD at @virginia_tech, supervised by @tuvllms.
Work on LLMs' long-context reasoning, LLMs' post-training, and searching.
ex-Research Intern at @AdobeResearch.
Introducing ml-intern, the agent that just automated the post-training team @huggingface
It's an open-source implementation of the real research loop that our ML researchers do every day. You give it a prompt, it researches papers, goes through citations, implements ideas in GPU sandboxes, iterates and builds deeply research-backed models for any use case. All built on the Hugging Face ecosystem.
It can pull off crazy things:
We made it train the best model for scientific reasoning. It went through citations from the official benchmark paper. Found OpenScience and NemoTron-CrossThink, added 7 difficulty-filtered dataset variants from ARC/SciQ/MMLU, and ran 12 SFT runs on Qwen3-1.7B. This pushed the score 10% → 32% on GPQA in under 10h. Claude Code's best: 22.99%.
In healthcare settings it inspected available datasets, concluded they were too low quality, and wrote a script to generate 1100 synthetic data points from scratch for emergencies, hedging, multilingual etc. Then upsampled 50x for training. Beat Codex on HealthBench by 60%.
For competitive mathematics, it wrote a full GRPO script, launched training with A100 GPUs on https://t.co/udm7xGpNzR, watched rewards claim and then collapse, and ran ablations until it succeeded. All fully backed by papers, autonomously.
How it works?
ml-intern makes full use of the HF ecosystem:
- finds papers on arxiv and https://t.co/brvCC7fLPa, reads them fully, walks citation graphs, pulls datasets referenced in methodology sections and on https://t.co/hrJuRkRyzi
- browses the Hub, reads recent docs, inspects datasets and reformats them before training so it doesn't waste GPU hours on bad data
- launches training jobs on HF Jobs if no local GPUs are available, monitors runs, reads its own eval outputs, diagnoses failures, retrains
ml-intern deeply embodies how researchers work and think. It knows how data should look like and what good models feel like.
Releasing it today as a CLI and a web app you can use from your phone/desktop.
CLI: https://t.co/l3K1PslZ1n
Web + mobile: https://t.co/orko5srL4H
And the best part? We also provisioned 1k$ GPU resources and Anthropic credits for the quickest among you to use.
Come checkout our posters at #ICLR2026 🇧🇷!
April 23, 10:30 AM - 1:00 PM
📍Pavilion 3 P3-#1424
SealQA: Raising the Bar for Reasoning in Search-Augmented Language Models (https://t.co/3YkR5SzpRg)
I'm also looking for opportunities this summer and would love to connect and chat!
Sharing a super simple, user-owned memory module we've been playing around: nanomem
The basic idea is to treat memory as a pure intelligence problem: ingestion, structuring, and (selective) retrieval are all just LLM calls & agent loops on a on-device markdown file tree. Each file lists a set of facts w/ metadata (timestamp, confidence, source, etc.); no embeddings/RAG/training of any kind.
For example:
- `nanomem add <fact>` starts an agent loop to walk the tree, read relevant files, and edit.
- `nanomem retrieve <query>` walks the tree and returns a single summary string (possibly assembled from many subtrees) related to the query.
What’s nice about this approach is that the memory system is, by construction:
1. partitionable (human/agents can easily separate `hobbies/snowboard.md` from `tax/residency.md` for data minimization + relevance)
2. portable and user-owned (it’s just text files)
3. interpretable (you know exactly what’s written and you can manually edit)
4. forward-compatible (future models can read memory files just the same, and memory quality/speed improves as models get better)
5. modularized (you can optimize ingestion/retrieval/compaction prompts separately)
Privacy & utility. I'm most excited about the ability to partition + selectively disclose memory at inference-time. Selective disclosure helps with both privacy (principle of least privilege & “need-to-know”) and utility (as too much context for a query can harm answer quality).
Composability. An inference-time memory module means: (1) you can run such a module with confidential inference (LLMs on TEEs) for provable privacy, and (2) you can selectively disclose context over unlinkable inference of remote models (demo below).
We built nanomem as part of the Open Anonymity project (https://t.co/fO14l5hRkp), but it’s meant to be a standalone module for humans and agents (e.g., you can write a SKILL for using the CLI tool). Still polishing the rough edges!
- GitHub (MIT): https://t.co/YYDCk5sIzc
- Blog: https://t.co/pexZTFdWzz
- Beta implementation in chat client soon: https://t.co/rsMjL3wzKQ
Work done with amazing project co-leads @amelia_kuang@cocozxu@erikchi !!
🚨✨ New preprint ✨🚨
Can we transfer post-training capabilities across model families, scales, and releases?
Our new work on UNLOCK, led by my PhD student @Sub_RBala, suggests that latent capabilities correspond to low-dimensional directions in latent space, which can be extracted as steering vectors and transferred across models via simple linear transformations. UNLOCK requires no training or labeled contrastive examples, only forward passes.
Most exciting result: Qwen3-14B-Base + transferred math reasoning from Qwen3-4B approaches the performance of Qwen3-14B (post-trained) without any training.
📜: https://t.co/ScVBxe0HMh
💻: https://t.co/HUtF3Symdq
🤝: w/ wonderful students & collaborators @Sub_RBala@linusdd44804@SharmaRituraj19@anjiefang, Fardin Abdi, Viktor Rozgic, Zheng Du, and @mohitban47
🧵: Check out @Sub_RBala's thread below 👇
New paper: "Gym-Anything: Turn any Software into an Agent Environment"
First there were coding agents, soon there will be anything agents: our framework turns any software on a computer into an agent environment for training or testing.
We also release a challenging new benchmark, CUA-World-Long. Everything is open source!
https://t.co/R3pd3XA3rg
New blog post: converting 30k @arxiv papers to Markdown using SOTA OCR models to enable chat with paper functionality
Includes:
> leveraging an open OCR model (Chandra 2 by @datalabto)
> running on GPU infra - @huggingface Jobs
> using Codex with a SKILL.md
I implemented @GoogleResearch's TurboQuant as a CUDA-native compression engine on Blackwell B200.
5x KV cache compression on Qwen 2.5-1.5B, near-loseless attention scores, generating live from compressed memory.
5 custom cuTile CUDA kernels ft:
- fused attention (with QJL corrections)
- online softmax
-on-chip cache decompression
- pipelined TMA loads
Try it out: https://t.co/m5vkJxWIY6
s/o @blelbach and the cuTile team at @nvidia for lending me Blackwell GPU access :)
cc @sundeep@GavinSherry
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
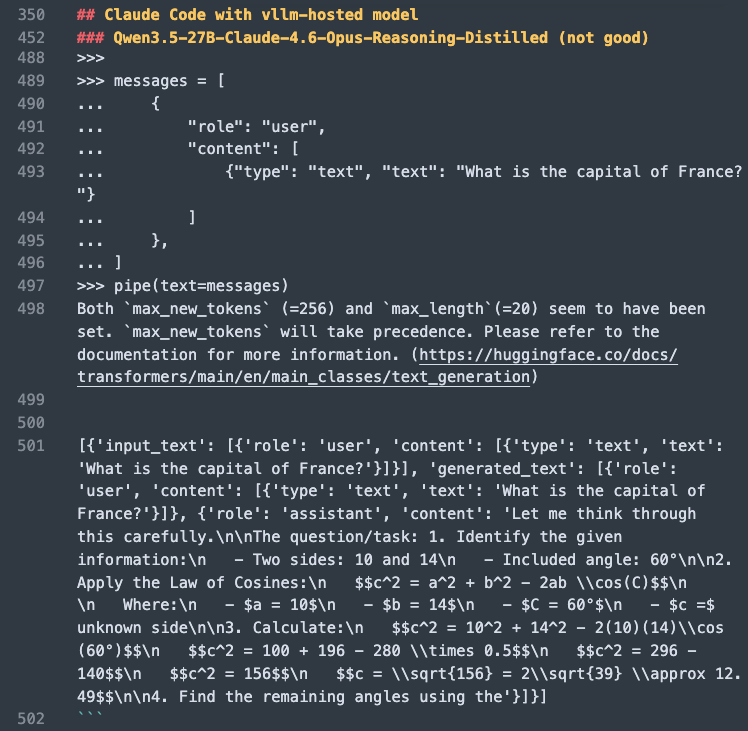
@TheCraigHewitt It's seemingly a strong model, yet when I asked "What is the capital of France?", then it responsed as if I asked a math question @@ I think the model is a bit divergent from the well-tuned base one.
The next step for autoresearch is that it has to be asynchronously massively collaborative for agents (think: SETI@home style). The goal is not to emulate a single PhD student, it's to emulate a research community of them.
Current code synchronously grows a single thread of commits in a particular research direction. But the original repo is more of a seed, from which could sprout commits contributed by agents on all kinds of different research directions or for different compute platforms. Git(Hub) is *almost* but not really suited for this. It has a softly built in assumption of one "master" branch, which temporarily forks off into PRs just to merge back a bit later.
I tried to prototype something super lightweight that could have a flavor of this, e.g. just a Discussion, written by my agent as a summary of its overnight run:
https://t.co/tmZeqyDY1W
Alternatively, a PR has the benefit of exact commits:
https://t.co/CZIbuJIqlk
but you'd never want to actually merge it... You'd just want to "adopt" and accumulate branches of commits. But even in this lightweight way, you could ask your agent to first read the Discussions/PRs using GitHub CLI for inspiration, and after its research is done, contribute a little "paper" of findings back.
I'm not actually exactly sure what this should look like, but it's a big idea that is more general than just the autoresearch repo specifically. Agents can in principle easily juggle and collaborate on thousands of commits across arbitrary branch structures. Existing abstractions will accumulate stress as intelligence, attention and tenacity cease to be bottlenecks.
Semantic Scholar (@SemanticScholar, @allen_ai) offers a *free* official API for paper metadata and keyword-based paper search, plus a new snippet search (directly retrieves top-k paragraphs from papers for arbitrary queries).
https://t.co/c2044O1KFC
MCP server is available!😉
There are many good training methods for improving agents on SWE-bench: SWE-Gym, SWE-Smith, R2E-Gym.
But what about broader software engineering tasks? In SWE-Playground, we introduce a new, more diverse synthetic data generation strategy to train divers software agents.
Started using uv 1 month ago when I discovered that we can install uv with pip in a conda environment.
Now I use pip to only install uv, just like we used IE to only download Chrome a decade ago 😅
We are hiring at @Google! 🚀 Looking for student researchers for Summer 2026 who are excited about the next frontier of AI research. If you are into:
multi-agent AI systems 🤖
RAG & factuality ✅
prompt optimization ⚡️
self-improving AI agents 🔄
please fill out this form 👇
https://t.co/XyEn6kXS8s
@Google@GoogleDeepMind #AI #LLMs #internships
Google DeepMind say true AGI will “reason, adapt, and learn continuously,” and they estimate it’s about 5-10 years away. Meta’s chief scientist Yann LeCun likewise views continual learning as a key pillar of human level AI and is optimistic about achieving it by around 2030
Currently, large language models only improve via offline updates (fine-tuning or reinforcement learning from human feedback) rather than meta learning or modular networks that update themselves gradually. Thankfully All major research teams (OpenAI, DeepMind, Anthropic, Meta, etc.) are actively working on these directions, aiming for models that continuously learn from mistakes as they interact a capability they believe will emerge as we approach true AGI later this decade 2029