@thsottiaux I use `/Side` a lot and often need to bring side-thread context back to the main thread with:
“Give a full plan/summary so we can return to the main thread, assume it doesn’t know what we discussed here.”
Which I then copy-paste to the main.
A “Consolidate” button maybe?
@OpenAIDevs A step towards native CCC, love it!
In CCC i used smashing the ‘c’ key 3 times to invoke codex to grab a screenshot and the current text so suggest completion
Thx @OpenAIDevs !
https://t.co/MCfSuKUR4M
@OpenAIDevs@OpenAIDevs any chance you’d consider building something like CCC natively?
We’d love to be able to summon Codex from any textbox and have it understand the app/context I’m in.
https://t.co/MCfSuKUR4M
Codex never ceases to amaze me.
I'm a Mac user, so my Windows troubleshooting skills are… meh.
I had a Surface Book 2 sitting dead for over 2 years, battery dead, hard-resetting a few minutes after every boot.
Today I thought, why not give Codex a shot?
Plugged it in, barely managed to install Codex, and it diagnosed + stabilized the machine through 5 more crashes mid-process.
It's now a huge tablet for streaming, browsing, and casual online games for the kids.
It almost went to the trash 😅
Wow, #Codex. Wow.
Attached is the conversation dump:
https://t.co/dRpJkunSY0
@thsottiaux Eventually I overcame it by moving the images to ephemeral session and consolidating to the main session texts only, which is better (much faster) regardless for the CCC utility, but the process itself made me come across the compaction endless loop
@thsottiaux@thsottiaux I noticed that when a session has many images, once the point of compaction reaches, the session is not compacting the images part, only the texts, and you enter re-compaction in every new turn (reproduced it when I made https://t.co/MCfSuKUR4M)
Shipped🚢 another update
- screenshot context is now much lighter and faster
- small formatting bug located thx to https://t.co/W5HGSOnoUf !
#Codex ❤️🔥
Tibo do you guys ever sleep?
Chronicle & order-of-magnitude faster Codex on the way!
Feels like Santa is in town 🎁
I've built CCC (Casual-Codex-Completion).
Smash the 'c' key 3 times to summon Codex into almost anytext box on macOS.
Made with #Codex ❤️🔥
https://t.co/7CQxpVcktN
We are releasing a *research preview* of Chronicle in Codex. It allows codex to build up memories based on your day to day work on your computer and then refer to these memories to be a lot more helpful.
Available for PRO subscriptions and on Mac to start. This is early and consumes quite a bit of tokens, but it has changed how I and many folks at OpenAI use Codex.
My 7 year old son:
Dad, what are you playing?
Me
It's called ARC-AGI-3
Son
Cool! can you put it on my Gameboy?
(He has RG35XX)
Me
Hold my beer
Any sufficiently advanced technology is indistinguishable from magic
#Codex + #GPT54@OpenAIDevs@arcprize#RG35XX
♫ BloodPixelHero
#AI is undoubtedly the hottest topic in the #insightsindustry. And we all have questions.
How can it be harnessed? How can it benefit both suppliers and clients? Are there pitfalls? Join us next week at the virtual #IIEXAI event, where leading experts from across the market research industry will be sharing their insights, predictions, and experiences to help level-up our understanding, and go deep on some of the trickiest questions.
Roy Sadaka, Director, Machine Learning at Toluna, will lead a session exploring how we can better craft the future of insights through #intelligentcomputing (AI), human ingenuity (HI), and intuitive design (UI).
Join us for free using the link below to hear Roy explain why it is so important to combine these three practices to extract maximum value from this exciting, emerging technology.
➡ Learn more about IIEX AI and register here: https://t.co/EN99dNw8Ij
📢 Unlimiformer now supports LLama-2!
Unlimiformer-LLama-2 allows encoding extremely long inputs without re-training or finetuning LLama-2.
This is an initial implementation, but encoding 130k token inputs using LLama-2 takes only a few minutes!
https://t.co/tQroQ4QkVd
(1/4)
✨ Venture is live on @pypi 🎉 Powered by @OpenAI's #ChatGPT and @Gradio's UI, Venture is an exploration tool for your projects documentations.
https://t.co/Y8OKGQCP1M
(based on humble research) Although much slower than embeddings search, this approach offers higher retrieval accuracy for small scale, up to ~300 docs.
Reasoning Based Search is very experimental we expect it to evolve with more research.
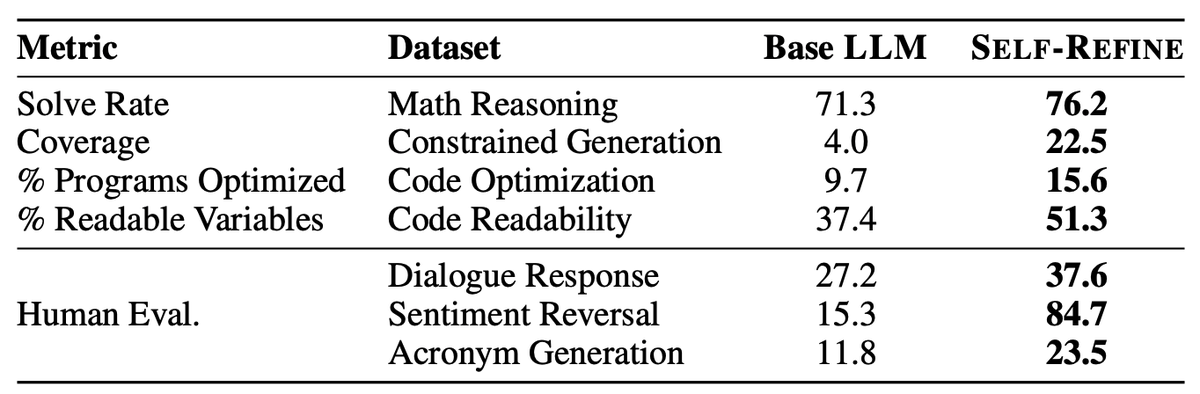
📢New Paper: Self-Refine: Iterative Refinement with Self-Feedback
We use an LLM such as GPT-3.5/4 to:
1. Generate output
2. Provide feedback on its own output
3. Refine its previous output
Improves outputs across 7 tasks without additional data/training!
https://t.co/DVFujOED0Z
🔥 New (1h56m) video lecture: "Let's build GPT: from scratch, in code, spelled out."
https://t.co/2pKsvgi3dE
We build and train a Transformer following the "Attention Is All You Need" paper in the language modeling setting and end up with the core of nanoGPT.
📢 New Paper: Program-aided Language models
Prompting methods such as chain-of-thought (@_jasonwei) employ LLM for decomposing the problem into steps *and* solving each step.
Instead, PaL decomposes the problem into *programmatic* steps and solves using a Python interpreter.
1/4
📢 New paper!
RetoMaton: Neuro-Symbolic Language Modeling with Automaton-augmented Retrieval
#ICML2022
We construct a *weighted automaton* from the training data of a given LM, and traverse it at inference time, in parallel with the LM.
https://t.co/klvV6Ch4MY
🧵 (1/4)
Graph Attention Networks (GAT) are one of the most popular GNNs.
However, their attention mechanism is much weaker than standard attention (e.g., Transformer's)!
Luckily, it can be fixed! We will present GATv2 at #ICLR2022 tomorrow,
Wed Apr 27
1:30-3:30 PM EST
5:30-7:30 PM GMT