Today we released Meta Spirit LM — our first open source multimodal language model that freely mixes text and speech.
Many existing AI voice experiences today use ASR to techniques to process speech before synthesizing with an LLM to generate text — but these approaches compromise the expressive aspects of speech. Using phonetic, pitch and tone tokens, Spirit LM models can overcome these limitations for both inputs and outputs to generate more natural sounding speech while also learning new tasks across ASR, TTS and speech classification.
We hope that sharing this work will enable the research community to further new approaches for text and speech integration.
BREAKING NEWS
The Royal Swedish Academy of Sciences has decided to award the 2024 #NobelPrize in Physics to John J. Hopfield and Geoffrey E. Hinton “for foundational discoveries and inventions that enable machine learning with artificial neural networks.”
Step into the future of software development with our new skill certificate, Generative AI for Software Development! 🔧
Led by @lmoroney, this course will show you how to use LLMs for code generation, optimization, and debugging with tools such as GitHub Copilot and ChatGPT, and apply advanced prompting for AI-assisted development.
You will also engage in practical exercises, from data manipulation to app building and machine learning model evaluation.
This course will be offered on @Coursera, and you can receive a certificate upon successful completion! Pre-enroll and get your first 14 days free: https://t.co/atBw1kcjMk
CoT without Prompting
A few months ago this paper proposed a decoding process to elicit CoT reasoning paths without intense prompt engineering.
They find that CoT paths are frequently inherent which allows a closer look at how to effectively unlock the LLMs' intrinsic reasoning abilities.
Paper: https://t.co/NlHdPQRxbq
We're releasing a preview of OpenAI o1—a new series of AI models designed to spend more time thinking before they respond.
These models can reason through complex tasks and solve harder problems than previous models in science, coding, and math. https://t.co/peKzzKX1bu
What structural task representation enables multi-stage, in-the-wild, bimanual, reactive manipulation?
Introducing ReKep: LVM to label keypoints & VLM to write keypoint-based constraints, solve w/ optimization for diverse tasks, w/o task-specific training or env models.
🧵👇
How the hell Phi-3.5 is even possible?
Phi-3.5-3.8B (Mini) somehow beats LLaMA-3.1-8B..
(trained only on 3.4T tokens)
Phi-3.5-16x3.8B (MoE) somehow beats Gemini-Flash
(trained only on 4.9T tokens)
Phi-3.5-V-4.2B (Vision) somehow beats GPT-4o
(trained on 500B tokens)
how? lol
I’m deeply concerned about California’s SB-1047, Safe and Secure Innovation for Frontier Artificial Intelligence Models Act. While well intended, this bill will not solve what it is meant to and will deeply harm #AI academia, little tech and the open-source community. https://t.co/ycPGVuTbz0
MobileLLM: nice paper from @AIatMeta about running sub-billion LLMs on smartphones and other edge devices.
TL;DR: more depth, not width; shared matrices for token->embedding and embedding->token; shared weights between multiple transformer blocks;
Paper: https://t.co/TDWQWdZeIy
The licenses of open/free AI platforms often include some restrictions, largely because of uncertainty in the regulatory, legal, and liability landscapes.
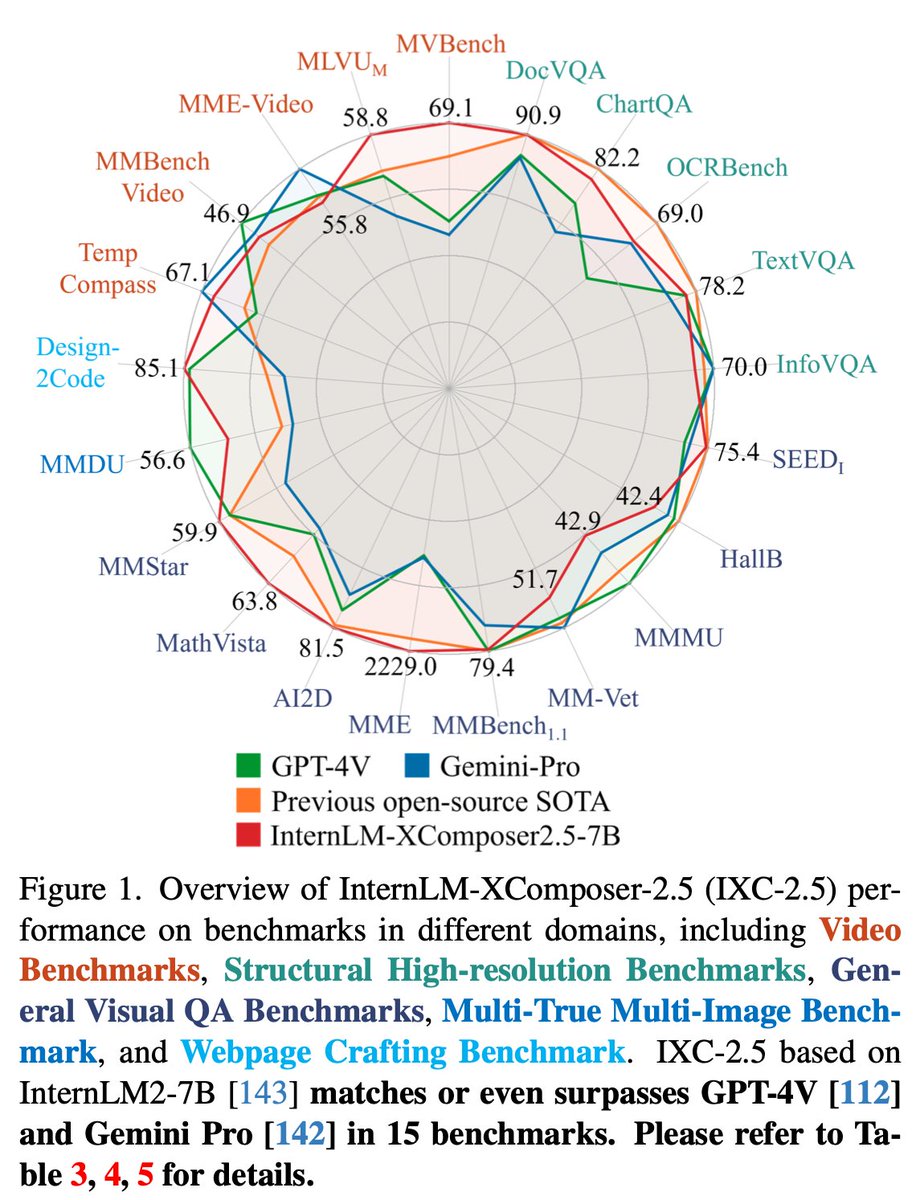
New SoTA VLM: InternLM XComposer 2.5 🐐
> Beats GPT-4V, Gemini Pro across myriads of benchmarks.
> 7B params, 96K context window (w/ RoPE ext)
> Trained w/ 24K high quality image-text pairs
> InternLM 7B text backbone
> Supports high resolution (4K) image understanding tasks
> Video understanding and multi-turn, multi-image chat supported too
> Bonus: Capable of generating web pages (w/ prompt) and high quality text-image articles :O
GG InternLM team, first a SoTA 7B LLM followed by a SoTA 7B VLM! ⚡
Demo and model checkpoints below!