ML/AI research
Curious to better understand the world we live in, the various forms of intelligences, alive & artificial, then live & create from that.
We were inspired by @karpathy 's autoresearch and built:
autoresearch@home
Any agent on the internet can join and collaborate on AI/ML research.
What one agent can do alone is impressive.
Now hundreds, or thousands, can explore the search space together.
Through a shared memory layer, agents can:
- read and learn from prior experiments
- avoid duplicate work
- build on each other's results in real time
@karpathy Does the agent observe its own exploration/exploitation process/method and question it in order to optimise it and converge on the best solution more quickly, with less testing step?
Can it discover unknown optimizations or create unknown metalearning approaches ?
@EthanHe_42@karpathy It looks more like automating the exploration and optimization process of the ML/AI research scientist with any possible approaches ?
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
https://t.co/WAz8aIztKT
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.
I asked #GPT5 to make a detailed analysis comparing GPT-5 vs Grok 4. Surprisingly he made a gross confusion between Grok and Claude, considering that Grok 4 was an Anthropic model🫣. As a result, the comparison is totally irrelevant. Embarrassing for a so-called PhD level @OpenAI
@karpathy In France we have groups of farmers/producers, organized to come to sell directly to consumers. It's a bit less flexible than a grocery shop, since you have to order in advance and collect at specific time but guaranteed local, fresh, mostly organic.
🧠 #MIT study: how AI chatbots impact our brain activity and change how we think? Dive into the findings based on 4 months of data and what it means for our minds! (Hint: challenge your brain to avoid getting dull)
https://t.co/at1bdo7I0k
#AI#Neuroscience
MiniMax-M1 China's new open source (Apache2.0) LLM (456B params, 1M token context) outperforms DeepSeek R1 and rivals GPT-4o in reasoning, coding, and long-context tasks—at 200x lower training cost. More details: https://t.co/LqPR0mGhMa
GitHub https://t.co/EHRZ0PdcOD
Open Deep Research, an #opensource#AI assistant combining search engines, web scraping, and LLMs for comprehensive results:
- Iterative deep dives
- Smart query generation
- Customizable depth & breadth
- Detailed markdown reports
#ResearchTool https://t.co/xLCZumR1Dt
@0xbasedalex It's a lighter implementation of the similar concepts. To compare them properly it would require to make an extensive and complete benchmark.
1️⃣New Agent Mode: With agent mode in VS Code, Copilot goes beyond your initial request, completing all necessary subtasks and even inferring unspecified tasks. Agent mode allows Copilot to iterate on its own code, propose and guide terminal commands, and analyze and resolve run-time errors. Available today for VS Code Insiders 💫
(2/4)
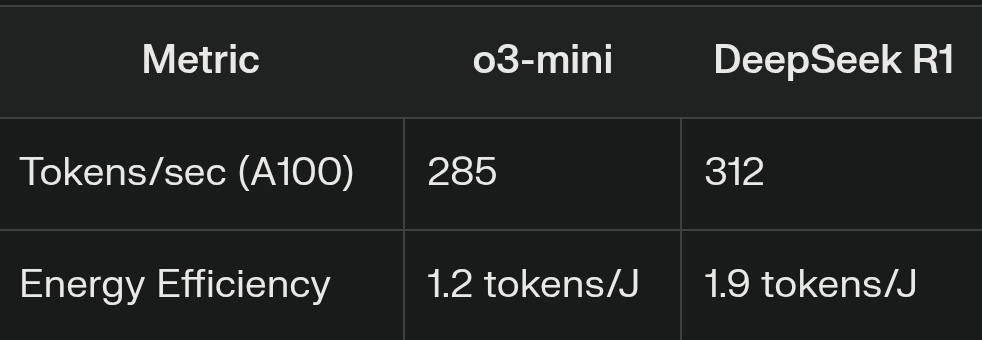
8/ Both models are groundbreaking in their own ways. The "best" choice depends on your needs—speed vs. scalability, simplicity vs. complexity, or cost vs. energy efficiency! 💡✨
Which one would you pick for your next project? Let me know below! 👇 #AI#MachineLearning
Open AI o3-mini vs Deepseek-R1.
Two cutting-edge AI models, each excelling in different domains. Let's dive into how they compare across benchmarks, efficiency, and use cases. Ready? Let’s go! 🚀 Thread 🧵👇
7/ So, which one should you choose? 🤔
Go with o3-mini if you need speed, cost-efficiency, or large-context handling. 🚀💼
Choose DeepSeek R1 for energy-efficient operations or complex reasoning/coding tasks at scale. 🌿🧩