Can we release all the weights of an LLM but still provide differential access to privileged users?
Yes! We introduce: 𝗧𝗶𝗲𝗿𝗲𝗱 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹𝘀 (𝗧𝗟𝗠𝘀). Define access tiers corresponding to different computation graphs over the same set of LLM parameters!
Today, we're launching Aside, the AI browser you’ve waited for.
⋅ Crafted in every detail: vertical tabs and Liquid Glass
⋅ SOTA on agentic browsing benchmarks: outperforms Claude Fable
⋅ Full privacy: Everything runs in local and encrypted
⋅ You can use Claude or ChatGPT subscription
The first AI browser built to do real work for you.
https://t.co/coZkFSGfgc
Can a small academic team build a strong text-to-image model using only public datasets?
Introducing i1: a simple, fully open recipe for strong text-to-image models
Seedance 2.5 is mythos moment of Video Models
> more than 30 seconds
> 4k resolution
> prompt adherence is on another level that we never seen before
> our reports was right , this is why follow us and join our server
> July will be do much fun
BYTEDANCE 🔥: Seedance 2.5 has been officially announced, along with an updated Seedance 2.0.
- Seedance 2.0 now supports 4k output
- Seedance 2.5 will be able to generate 30-second videos in one go
- ByteDance also announced a new AI copyright commercialization platform
This video ad is stunning 👀
Today we're releasing prime-rl v0.6.0 — enabling RL at trillion-parameter MoE scale on agentic workloads at the highest efficiency.
We've relentlessly optimized our RL infra.
The result: GLM-5 on agentic SWE tasks at 131k context and sub-5-minute step time.
We want to help all companies be secure, working with the USG and the security ecosystem.
*The full version of GPT-5.5-Cyber is here; state of the art performance on CyberGym.
*Patch The Planet and Codex Security will help solve security problems instead of just finding them.
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API.
Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls.
Try it: https://t.co/hhO6qTawgb 🐡
gemma-4-12B-agentic-fable5-composer2.5 V2 is out.
the agentic upgrade to the model trained on Fable 5's reasoning. Running it now with TurboQuant llama.cpp on a single RTX 4060( 8 GB VRAM) at 30 tokens/second with full 25000 context and reasoning:
# The benchmarks
v2 is built for coding + agentic work. writing code, running commands, using tools, debugging, multi step technical tasks. The clearest signal is tau2 bench telecom, an agentic tool use benchmark whose diagnose → fix → verify loop mirrors real terminal/debugging work:
tau2 bench telecom numbers:
base Gemma 4 12B: ~15%
this finetune: ~55%. (Self reported)
thats a huge jump
# TheTom/llama-cpp-turboquant flags:
llama-server.exe -m gemma4-v2-Q4_K_M.gguf -ngl 99 -c 25000 --cache-type-k q8_0 --cache-type-v turbo3 --port 8080
Flag breakdown:
-ngl 99 → full GPU offload
-c 25000 → 25K context
--cache-type-k q8_0 --cache-type-v turbo3 → mixed-precision KV cache — K at 8-bit, V at ~3-bit via TurboQuant (Walsh Hadamard rotated polar quant, Google's own KV-compression research).
Not even merged into mainline llama.cpp. running it off a fork.
No API. No cloud. Just llama.cpp. well, a fork of it and any 6gb+ GPU.
If you tried yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF, check this out and share your experience with the models
- 2016-2024: 🇺🇸leads in open-source AI
- 2024-2027: 🇺🇸 leads in general AI & massively benefits
- 2024-2026: 🇨🇳 leads in open-source AI
- 2026-2030: ??
It's not open-source AI leadership OR general AI leadership, it's open-source AI leadership BEFORE general AI leadership!
Open-source AI is the foundation of all AI. It does not only creates more innovation, competition, jobs, and prosperity now, it's also the best (only?) way for a national tech ecosystem to accelerate and ultimately reach the frontier of AI in general.
Because open-source AI reduces siloes, shares learning and innovation, intensify emulation which all lead to an acceleration of the local ecosystem progress that no others can match if they're less open and collaborative.
Same seems to be true for companies btw, OpenAI/Google started with open science and open-source AI which led to their (and Anthropic who spun off from OAI) domination. Meta could have done the same but decided to change course for some reason.
GLM 5.2 is now on DeepSWE as the top open-source model on our leaderboard.
With a pass@1 score of 44% at max effort, GLM 5.2 is indisputable #1 open-source model besting Kimi K2.7 Code by 17%.
ICYMI
Nanbeige 4.1, a 3b model released by Chinese Indeed, outperforms Qwen3-30b-A3b + Qwen 3.5 4b. It can finish long horizon tasks with 600+ tool calls
We are working on something similar. thinking about doing a paper reading session. dm/comment for interest.
MotionBricks by NVIDIA.
the all-in-one brain for character movement.
No manual rigging/animation, you just let this AI handle the physics and style in real-time.
- 15k FPS on RTX 5090! You could run an entire city of unique NPCs without breaking a sweat.
- Smart Primitives. The AI fills in the natural-looking motion automatically.
- Zero-Shot Skills.
- Glitch-Free. Keeps movements stable.
https://t.co/pgiwjvQgLs
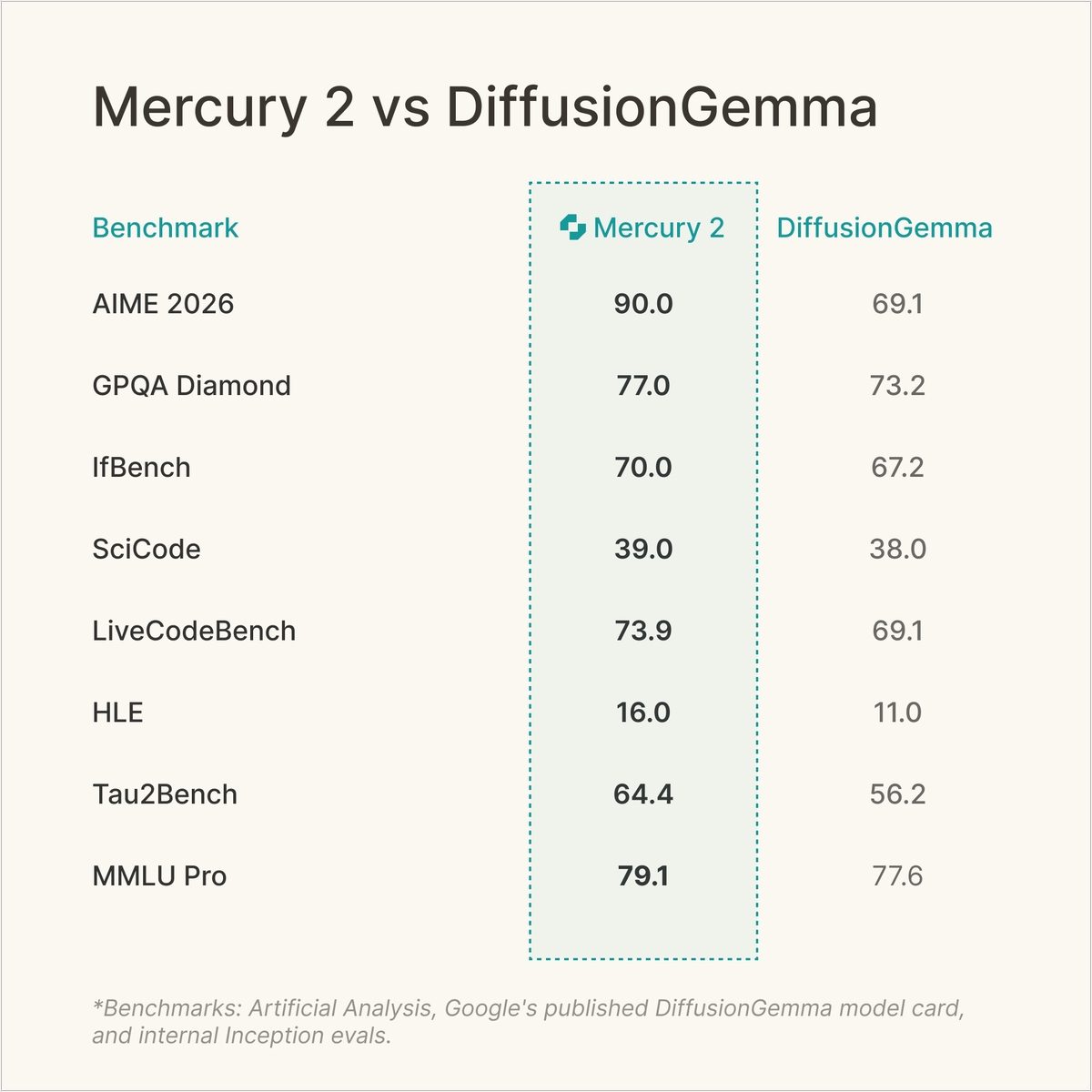
Welcome to the diffusion era.
We bet on parallel generation years ago, when it was a contrarian idea. It's great to see the industry arrive.
Mercury 2 continues to lead the Pareto frontier for quality, speed, and cost among publicly available diffusion LLMs.
1/ Today we're bringing Cua Driver to Linux: background computer-use for any agent. Hermes, Claude Code, Codex, or your own loop can drive real Linux desktop apps (X and Wayland in preview) through CLI or MCP while your desktop stays usable
Today we’re releasing the weights for Laguna M.1,
our most capable model to date, with a 256K context length.
Both base and post-trained checkpoints are now available on Hugging Face under Apache 2.0.
































![itarutomy's tweet photo. ニューラルネットワーク(NN)が「群演算(group composition)」を学ぶとき、内部で何が起きているかを初めて数学的に証明した(https://arxiv[.]org/abs/2606.02993)。
群とは整数の加算やモジュラー算術(時計算術、例として x+y mod 12)のような代数構造のこと。g₁⋆g₂ を予測する2層NNを訓練すると、各ニューロンは「既約表現(irreducible representation = 群の最小スペクトル単位で、フーリエ変換の基底に相当するもの)」に確率1で収束することが証明された(Theorem 4.3)。
興味深いのはその「選ばれ方」で、ランダム初期化のタイミングで偶然わずかに優勢だった既約表現が「ロッタリーチケット」として勝ち残り、他の候補は指数的に消えていく。どの表現が選ばれるかは初期化の「籤」で決まる。
アーベル群(足し算のように a⋆b=b⋆a が成り立つ可換な群)では完全な証明が得られた(Theorem 5.1, 5.3)。各ニューロンが学ぶ周波数は全体で均一に分散し、入力層と出力層のフーリエ位相が加法的に揃う(位相アライメント)。両プロセスとも指数収束速度で発生する。
実験はアーベル群 Z₃⊕Z₅(15元素、1024ニューロン)と非アーベル群のフロベニウス群 C₇⋊C₃(21元素)で検証済み。どちらも理論通りの挙動を確認した。
mechanistic interpretability(NNの内部を逆エンジニアリングする研究分野)で「単一周波数への特化」と呼ばれていた現象が、実は群論の表現論的構造そのものを発見していたことを示した研究。さらに「grokking(長い訓練後に突然テスト精度が跳ね上がる現象)」を Stage I(表現学習)→ Stage II(スケールが対数成長してsoftmaxを鋭化)という2段構えのダイナミクスとして説明できる理論的基礎にもなるかもしれない。](https://pbs.twimg.com/media/HLUwq4ZWEAAm0N2.jpg)