(4/7) Hard2Verify: A Step-Level Verification Benchmark for Open-Ended Frontier Math: https://t.co/Sj1GfmR5MP
Hard2Verify is a human-annotated benchmark (500+ hours of annotation) for assessing step-level verifiers on frontier math. Evaluating 29 models, it reveals that most open-source verifiers still lag behind closed-source systems on challenging, open-ended mathematical reasoning.
Authors: Shrey Pandit @ShreyPandit2001, Austin Xu @austinsxu, Xuan-Phi Nguyen @xuanphinguyen, Yifei Ming @ming5_alvin, Caiming Xiong @CaimingXiong, Shafiq Joty @JotyShafiq
Accepted to #ACL2026
Glad to share our paper “Hard2Verify” has been accepted at #ACL2026 - Main Conference. #LLM can now solve IMO-level math, but can they reliably verify each step of a proof ? Turns out, not really. We built Hard2Verify: a step-level verification benchmark for open-ended, frontier-level math problems sourced from competitions like IMO and Putnam.
The dataset comprises 1,860 steps across 200 model responses, fully annotated by PhD-level math experts over 500+ hours of human effort with three rounds of independent agreement checks. We benchmark 29 verifiers, and the takeaway is stark, models that score 60%+ on existing benchmarks like ProcessBench barely crack 20% on ours. If you're working on reasoning, reward models, or verification, the dataset is publicly available on HuggingFace and we think it's a useful stress test for where things actually stand.
📄 Paper: https://t.co/DGgyZ3ueYw
🤗 Dataset: https://t.co/HmxGx6rmYx
Grateful to work alongside an amazing team - @austinsxu@xuanphinguyen@ming5_alvin@CaimingXiong@JotyShafiq at @SFResearch
Poisoning the Well: Search Agents Get Tricked by Maliciously Hosted Content
https://t.co/X10GzjuBjm
AI agents that rely on web search are vulnerable to a deceptively simple attack: adversaries publish fake but authoritative-sounding content designed to be retrieved during search. Think "AI Slop" for agents.
Our research shows that when agents encounter planted content, they stop critically evaluating what they find and start accepting it at face value.
Key findings:
→ ~80% of queries returned the attacker's chosen answer when poisoned content was manually injected into search results
→ Agents shift from information-seeking mode to verification mode, performing fewer searches and reporting higher confidence
→ Even in realistic settings with 100K+ clean documents and just a handful of poisoned ones, nearly 1 in 4 queries were compromised
→ Agent self-reported confidence actually increases in the presence of adversarial content, making poisoned answers harder to detect
At @Salesforce, trust is a core value. These findings reinforce why we invest in defense mechanisms like our trust layer to help agents navigate hostile information landscapes reliably.
Authors: Shafiq Joty @jotyshafiq, Xuan Phi Nguyen @xuanphinguyen, Shrey Pandit @ShreyPandit2001, Yifei Ming @ming5_alvin
#FutureOfAI #EnterpriseAI #AIAgents
A single “poisoned” webpage can turn LLM search agents from investigators into lazy confirmers—showing how easily adversaries can manipulate agentic research. Check our interesting findings here.
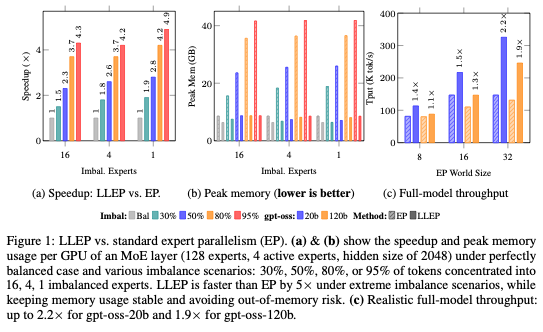
(1/5) MoE scaling loves Expert Parallelism (EP)… until routing gets imbalanced.
Even “well-trained” MoEs route a big chunk of tokens to a small subset of experts (specialization), so EP can overload a few GPUs and waste the rest—especially in post-training/inference where explicit load-balancing is often off-limits.
We introduce Least-Loaded Expert Parallelism (LLEP): dynamically spill excess tokens *and* the corresponding expert weights to the least-loaded devices, minimizing collective latency under memory constraints. Up to 5× faster + 4× lower peak mem; ~1.9× faster for gpt-oss-120b.
MoE scaling loves Expert Parallelism (EP)… until routing gets imbalanced.
Even “well-trained” MoEs route a big chunk of tokens to a small subset of experts (specialization), so EP can overload a few GPUs and waste the rest—especially in post-training/inference where explicit load-balancing is often off-limits.
We introduce Least-Loaded Expert Parallelism (LLEP): dynamically spill excess tokens *and* the corresponding expert weights to the least-loaded devices, minimizing collective latency under memory constraints. Up to 5× faster + 4× lower peak mem; ~1.9× faster for gpt-oss-120b. @SFResearch
Mixture-of-Experts models are typically trained with explicit load-balancing constraints—yet in practice, even strong MoEs exhibit highly imbalanced expert routing. Interestingly, this imbalance is often desirable, reflecting expert specialization across domains. The problem? Expert Parallelism (EP) quietly assumes balanced routing; under extreme imbalance—especially during post-training or inference—this assumption breaks, leading to severe compute and memory bottlenecks. We propose Least-Loaded Expert Parallelism (LLEP), a new EP algorithm that dynamically redistributes excess tokens and the corresponding expert weights from overloaded devices to underutilized ones—minimizing collective latency while respecting memory constraints.
📈 Up to 5× speedup
📉 Up to 4× peak memory reduction
⚡ ~1.9× faster inference for gpt-oss-120B
Paper: https://t.co/Sda0l8dH0C
Code: https://t.co/rGBLkDFmwg
Demo: https://t.co/QcyVI3THQd
Turing partnered with @SFResearch to evaluate Olympiad-grade mathematical reasoning in frontier models like GPT-5, Gemini 2.5 Pro, and Claude Sonnet 4.
Over 200 long-form math responses were annotated step-by-step using a zero-tolerance, carry-forward logic rubric. Each step received a binary correctness label and written justification, executed by PhDs and domain experts.
500+ hours of expert annotation produced a benchmark-grade dataset with 100% compliance to Salesforce’s strict evaluation standards. The results: higher fidelity in reasoning verification, stronger model alignment, and a clearer view of how LLMs handle symbolic problem solving at scale.
From RL Gyms to reasoning datasets, Turing accelerates post-training research with human precision and enterprise-grade rigor.
Case Study Below.
Hard2Verify: A Step-Level Verification Benchmark for Frontier Math 🎯
LLMs now achieve gold-level performance on IMO problems 🏅, but training these reasoners requires verifiers that can catch subtle step-level mistakes. We introduce Hard2Verify—500+ hours of human annotation assessing verifiers on frontier LLM responses to challenging, open-ended math problems 🧮
Key findings: Open-source verifiers struggle to identify errors, often marking nearly all steps as correct. Weaker models achieve near-0 True Negative Rate while True Positive Rate approaches 1 📊
📄 Paper: https://t.co/Sj1GfmQxXh
💻 Code: https://t.co/A2nWJAPsJe
📊 Dataset: https://t.co/DqMIGggXX7
Work by @ShreyPandit2001, @austinmxu, Xuan-Phi Nguyen, @yifeiming1, @caimingxiong, @JotyShafiq
#FutureOfAI #EnterpriseAI #MachineLearning #DeepLearning #MathematicalReasoning #AIVerification
One of the key challenges for building web-based “deep research” agents is to construct sufficiently difficult long-horizon agentic data.
At @SFResearch, We introduce ProgSearch, a controlled data synthesis pipeline that builds tasks of increasing complexity until a frontier agent fails — yielding more diverse, effective training data that pressures agents to reason on the open web. 🧠🌐
Paper: https://t.co/3Uyr2RABBC
📊Excited to introduce our Hard2Verify from @SFResearch , the benchmark for measuring the ability of verifiers to provide step-level correctness labels for model-generated responses to largely open-ended, frontier-level math problems📚
The current paradigm of RLVR requires questions with “easy to verify” answers. How can we move from answering algebra questions with concrete final answers 🎯 to writing complex proofs 📝 where correctness depends on all steps being correct? We need step-level verifiers!
Hard2Verify is built to assess step-level verifiers at the frontiers of math reasoning.
This benchmark is the product of 500+ hours of human expert effort. Thanks for the partnership, @turingcom!
Paper: https://t.co/BE7DTDRmqM
Evaluation code: https://t.co/7BuyppeEch
Dataset: https://t.co/m7xzg3xZN0
RL done right is no joke!
The most interesting AI paper I read this week.
It trains a top minimal single-agent model for deep research.
Great example of simple RL-optimized single agents beating complex multi-agent scaffolds.
Now let's break it down:
Meet SFR-DeepResearch (SFR-DR) 🤖: our RL-trained autonomous agents that can reason, search, and code their way through deep research tasks.
🚀SFR-DR-20B achieves 28.7% on Humanity's Last Exam (text-only) using only web search 🔍, browsing 🌐, and Python interpreter 🐍, surpassing DeepResearch with OpenAI o3 and Kimi Researcher.
🤖SFR-DR agents are trained to operate independently, without pre-defined multi-agent workflows. They autonomously plan, reason, and propose and take actions as defined by their tools.
🔄SFR-DR agents are trained with end-to-end RL. Starting from reasoning optimized models, our RL pipeline carefully preserves reasoning abilities while training models to become more capable research agents.
📝SFR-DR agents are also trained to manage their own memory by summarizing previous results when context becomes limited. This enables a virtually unlimited context window, enabling long-horizon tasks
Paper: https://t.co/32idhdknhh
#AIAgents #ReinforcementLearning #DeepResearch
@emnlpmeeting / #EMNLP2025 Accepted Paper: MedHallu: A Comprehensive Benchmark for Detecting Medical Hallucinations in Large Language Models 🏥
📝 Paper: https://t.co/P7YToATxNs
🔗 Dataset & Code: https://t.co/OXgCMUuAOa
This work introduces MedHallu, the first comprehensive benchmark specifically designed for detecting medical hallucinations in LLMs - a critical safety challenge where models generate plausible but factually incorrect medical information that could impact patient safety.
Key contributions:
➡️ 10,000 high-quality medical question-answer pairs with systematically generated hallucinations across 4 categories
➡️ Controlled generation pipeline with multi-LLM filtering and difficulty stratification (easy, medium, hard)
➡️ Semantic analysis revealing harder-to-detect hallucinations are closer to ground truth in vector space
➡️ Comprehensive evaluation showing even state-of-the-art models like GPT-4o achieve only 62.5% F1 on ""hard"" hallucinations
Key findings:
🔍 General-purpose LLMs outperform medical fine-tuned models in hallucination detection
📚 Providing domain knowledge improves detection by up to 38% relative improvement
🤔 Adding ""not sure"" option significantly boosts precision for critical medical applications
🎯 Incomplete information is the hardest hallucination type to detect (54% accuracy)
The benchmark reveals concerning gaps in current LLMs' ability to detect medical misinformation, with implications for safe deployment in healthcare settings.
👥 Authors: Shrey Pandit @ShreyPandit2001, Jiawei Xu @jiaweixu0230, Junyuan Hong @hjy836, Zhangyang Wang, Tianlong Chen @TianlongChen4, Kaidi Xu @KaidiXu1, Ying Ding
#FutureOfAI #EnterpriseAI #MedicalAI #MachineLearning #NLP #HealthcareAI #AIEthics #Hallucination #PatientSafety
Excited to share that our paper, “MedHallu: A Comprehensive Benchmark for Detecting Medical Hallucinations in Large Language Models,” was accepted to EMNLP 2025 (Main)! Huge thanks to my co-authors @jiaweixu0230, @hjy836, Atlas Wang, @TianlongChen4, @KaidiXu1, and Ying Ding!
🚨 New Research Alert! 🚨
Happy to share my latest work -
MedHallu: A Comprehensive Benchmark for Detecting Medical Hallucinations in Large Language Models
📄Arxiv - https://t.co/WlyhOroZk3
🤗HuggingFace Dataset - https://t.co/me6zGKCcId
🌐Website - https://t.co/tBg3s4S7Q8
🚨 New Research Alert! 🚨
Happy to share my latest work -
MedHallu: A Comprehensive Benchmark for Detecting Medical Hallucinations in Large Language Models
📄Arxiv - https://t.co/WlyhOroZk3
🤗HuggingFace Dataset - https://t.co/me6zGKCcId
🌐Website - https://t.co/tBg3s4S7Q8
💡 What Makes MedHallu Unique?
- Difficulty Categorization: Easy, Medium, and Hard hallucination levels for granular evaluation.
- Controlled Hallucination Generation: Ensures diverse and realistic hallucinated answers.