this guy literally put a full AI engineering curriculum on GitHub and made it 100% FREE 🤯
435 lessons.
20 phases.
320 hours.
The rule that makes this curriculum completely different:
Every algorithm gets implemented from raw math before a single framework gets imported.
You build the backprop.
You build the tokenizer.
You build the attention mechanism.
By the time you use PyTorch, it’s just a shortcut for something you already know how to code from scratch.
It spans four languages:
→ Python for ML pipelines
→ TypeScript for agent tooling
→ Rust for performance-critical components
→ Julia for numerical computation
And the best part?
Every single lesson ships something you can actually use.
You walk away with fully deployable prompts, SKILL. md files, agents, and MCP servers.
The curriculum scales from foundational math all the way up to autonomous agent swarms and production infrastructure.
Free, open-source, and MIT licensed.
repo in 🧵↓
ai layoffs are getting out of hands so I built “I GOT FIRED” button 🚨
one click, and it makes entire company codebase public, pushes .env secrets to public repo, drops staging db and finally notifies my lawyer 🙂
I hope I never need it but it’s ready 👍🏻
i co-wrote the Anthropic engineering blog on Claude Managed Agents, and wanted to share some thoughts on agent harnesses + infrastructure for long-horizon tasks ... 🧵
https://t.co/nEHnNyQS9p
Yes it's the tractable form of brain upload. There's a ton of scifi on brain uploads that requires way too exotic tech (scanning and simulating brains etc), when we're about to get a lossy and approximate version of that *a lot* sooner via LLM simulators. You can easily imagine a "brain upload" startup - you show up for a few days to carry out detailed video interviews, then they use all that data with an LLM finetuning process to "upload" you and give you an API endpoint of your simulation that you can talk to. Look at what's already possible with HeyGen as an example, but combine it with an LLM model that has deep knowledge and personality. Trippy and admittedly kind of dystopian but in principle quite possible around now.
I’m proud that so many of the world’s leading companies have joined us for Project Glasswing to confront the cyber threat posed by increasingly capable AI systems head-on.
https://t.co/pn3HSVsThP
Every team at your company should be creating their own 'Team OS' in Claude Code on Github. Here's how:
1:45 - What is a Team OS
13:37 - Shared skills and commands
25:24 - Shared team automations
59:50 - The learning flywheel
This 2-hour lecture by Andrej Karpathy - co-founder of OpenAI, the man who coined "vibe coding" - will build GPT from scratch and show you exactly why message 30 costs you 31x more than message 1.
Bookmark this & give it 2 hours today, no matter what. It's the best thing you can do for your Claude budget. Then read the article below.
After this, you'll never pay for tokens Claude spends talking to itself again.
Karpathy dropped a viral post about building a "second brain" with AI. We built it live in under 20 minutes.
The system:
1. Three folders: raw/ (brain dump), wiki/ (AI organizes it), outputs/ (query results)
2. One-click install: npx skills add NicholasSpisak/second-brain
3. Obsidian Web Clipper to capture any article with one click
4. Run "ingest" and the AI reads everything in raw/, builds wiki pages, and maps connections automatically
5. Query your own knowledge base like talking to an expert
6. Monthly lint command catches contradictions and gaps before they compound
Day 1 it's basic. Day 90 it's a company asset nobody else has.
Free skill in the YouTube description that scaffolds the whole thing in 60 seconds.
Video below, YouTube link in the replies.
🚨 BREAKING: Someone just built the exact tool Andrej Karpathy said someone should build.
48 hours after Karpathy posted his LLM Knowledge Bases workflow, this showed up on GitHub.
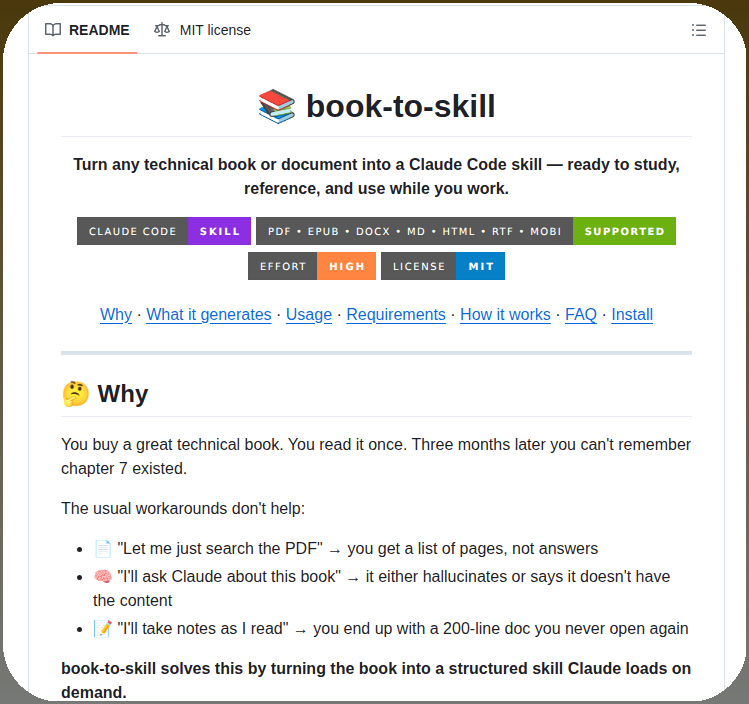
It's called Graphify. One command. Any folder. Full knowledge graph.
Point it at any folder. Run /graphify inside Claude Code. Walk away.
Here is what comes out the other side:
-> A navigable knowledge graph of everything in that folder
-> An Obsidian vault with backlinked articles
-> A wiki that starts at index. md and maps every concept cluster
-> Plain English Q&A over your entire codebase or research folder
You can ask it things like:
"What calls this function?"
"What connects these two concepts?"
"What are the most important nodes in this project?"
No vector database. No setup. No config files.
The token efficiency number is what got me:
71.5x fewer tokens per query compared to reading raw files.
That is not a small improvement. That is a completely different paradigm for how AI agents reason over large codebases.
What it supports:
-> Code in 13 programming languages
-> PDFs
-> Images via Claude Vision
-> Markdown files
Install in one line:
pip install graphify && graphify install
Then type /graphify in Claude Code and point it at anything.
Karpathy asked. Someone delivered in 48 hours.
That is the pace of 2026.
Open Source. Free.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
How to setup your Claude code project?
TL;DR
Most developers skip the setup and just start prompting. That's the mistake.
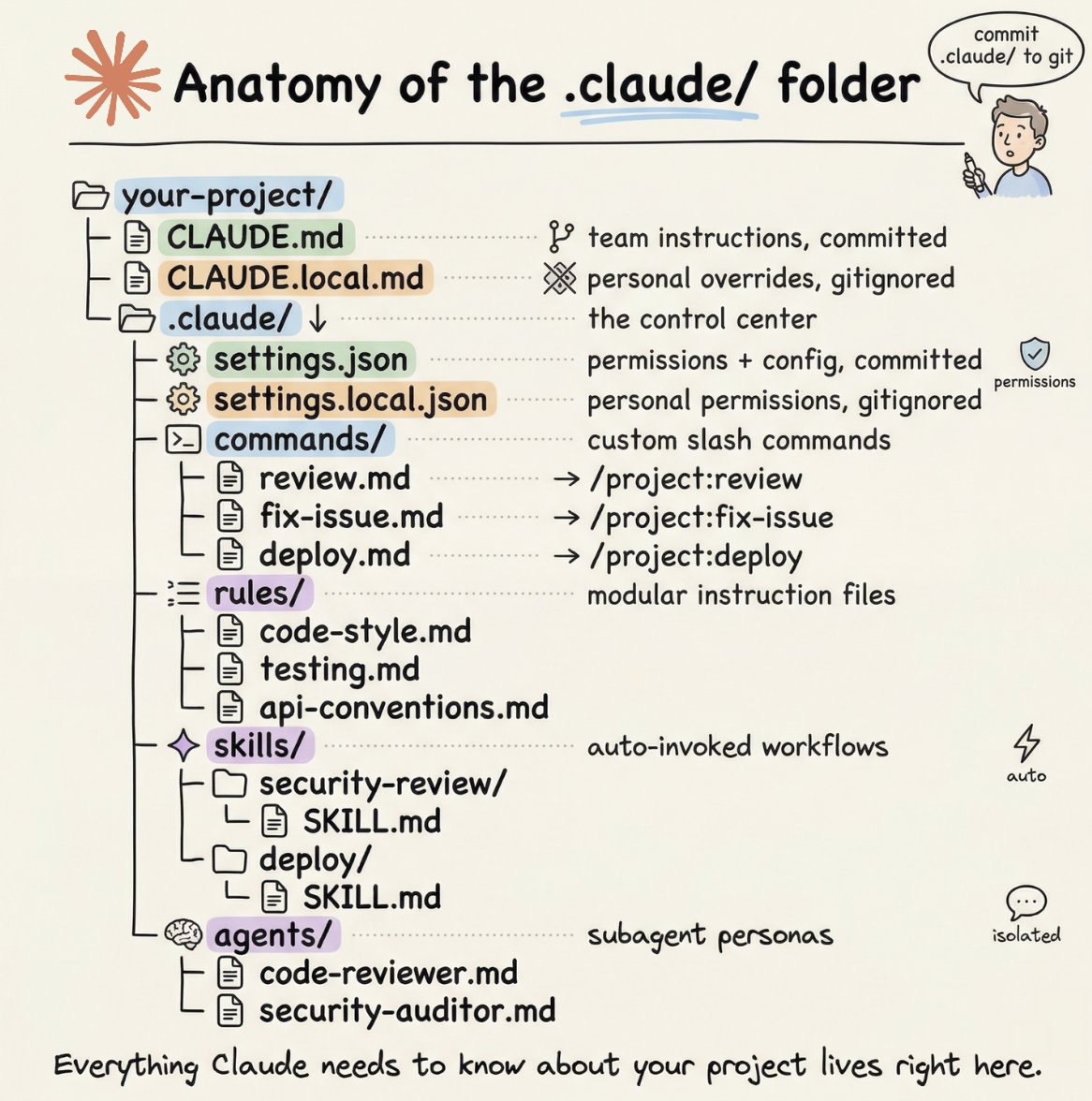
A proper Claude Code project lives inside a .𝗰𝗹𝗮𝘂𝗱𝗲/ folder. Start with 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 as Claude's instruction manual. Split it into a 𝗿𝘂𝗹𝗲𝘀/ folder as it grows. Add 𝗰𝗼𝗺𝗺𝗮𝗻𝗱𝘀/ for repeatable workflows, 𝘀𝗸𝗶𝗹𝗹𝘀/ for context-triggered automation, and 𝗮𝗴𝗲𝗻𝘁𝘀/ for isolated subagents. Lock down permissions in 𝘀𝗲𝘁𝘁𝗶𝗻𝗴𝘀.𝗷𝘀𝗼𝗻.
There are two .𝗰𝗹𝗮𝘂𝗱𝗲/ folders: one committed with your repo, one global at ~/.𝗰𝗹𝗮𝘂𝗱𝗲/ for personal preferences and auto-memory across projects.
The .𝗰𝗹𝗮𝘂𝗱𝗲/ folder is infrastructure. Treat it like one.
The article below is a complete guide to 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱, custom commands, skills, agents, and permissions, and how to set them up properly.
I'm joining @OpenAI to bring agents to everyone. @OpenClaw is becoming a foundation: open, independent, and just getting started.🦞
https://t.co/XOc7X4jOxq
+1 for "context engineering" over "prompt engineering".
People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step. Science because doing this right involves task descriptions and explanations, few shot examples, RAG, related (possibly multimodal) data, tools, state and history, compacting... Too little or of the wrong form and the LLM doesn't have the right context for optimal performance. Too much or too irrelevant and the LLM costs might go up and performance might come down. Doing this well is highly non-trivial. And art because of the guiding intuition around LLM psychology of people spirits.
On top of context engineering itself, an LLM app has to:
- break up problems just right into control flows
- pack the context windows just right
- dispatch calls to LLMs of the right kind and capability
- handle generation-verification UIUX flows
- a lot more - guardrails, security, evals, parallelism, prefetching, ...
So context engineering is just one small piece of an emerging thick layer of non-trivial software that coordinates individual LLM calls (and a lot more) into full LLM apps. The term "ChatGPT wrapper" is tired and really, really wrong.